[Alpha] Cross-Data Center Disaster Recovery
Contents
[Alpha] Cross-Data Center Disaster Recovery#
Background#
In a single-cluster deployment environment, OpenMLDB has high availability capabilities at the node level within the cluster. However, in scenarios involving uncontrollable factors such as power outages in data centers or natural disasters, causing the data center or a significant number of nodes to be inoperable, the cluster’s state might become abnormal, leading to interruptions in online services. Therefore, OpenMLDB also provides a cross-data center disaster recovery solution to address this issue.
In this solution, users can deploy independent OpenMLDB clusters in multiple geographically distant data centers and set up these multiple OpenMLDB clusters in a master-slave replication mode. In this deployment architecture, if the primary cluster fails to provide services, users can perform a master-slave switch to ensure uninterrupted business operations.
Architecture#
Definition of Terms#
Master Cluster: This cluster supports both read and write operations and synchronizes data with slave clusters. A master cluster can have multiple slave clusters.
Slave Cluster: A cluster that only handles read requests, maintains data consistency with the master cluster, can switch to a primary role when necessary, and can be deployed in multiple instances.
Partition Leader: The primary partition responsible for receiving both read and write data.
Partition Follower: A secondary partition that exclusively accepts data synchronized from the partition leader. It does not directly accept write requests from clients.
Offset: This term refers to the data offset stored in OpenMLDB’s binlog. A larger offset value indicates newer data.
For a more comprehensive understanding of these terms, please consult the OpenMLDB documentation on Online Module Architecture.
Goals#
The master cluster facilitates write operations, while both the master and slave clusters support read operations.
A master cluster can be supplemented with multiple slave clusters for redundancy.
In the event of an unexpected master cluster outage, a manual switch can promote a slave cluster to the master cluster role.
Capable of automatically handling scenarios where nodes within the master cluster or slave clusters become unavailable or go offline, including nameservers and tablets.
Solution#
The overall technical architecture of the master-slave cluster is shown in the following figure:
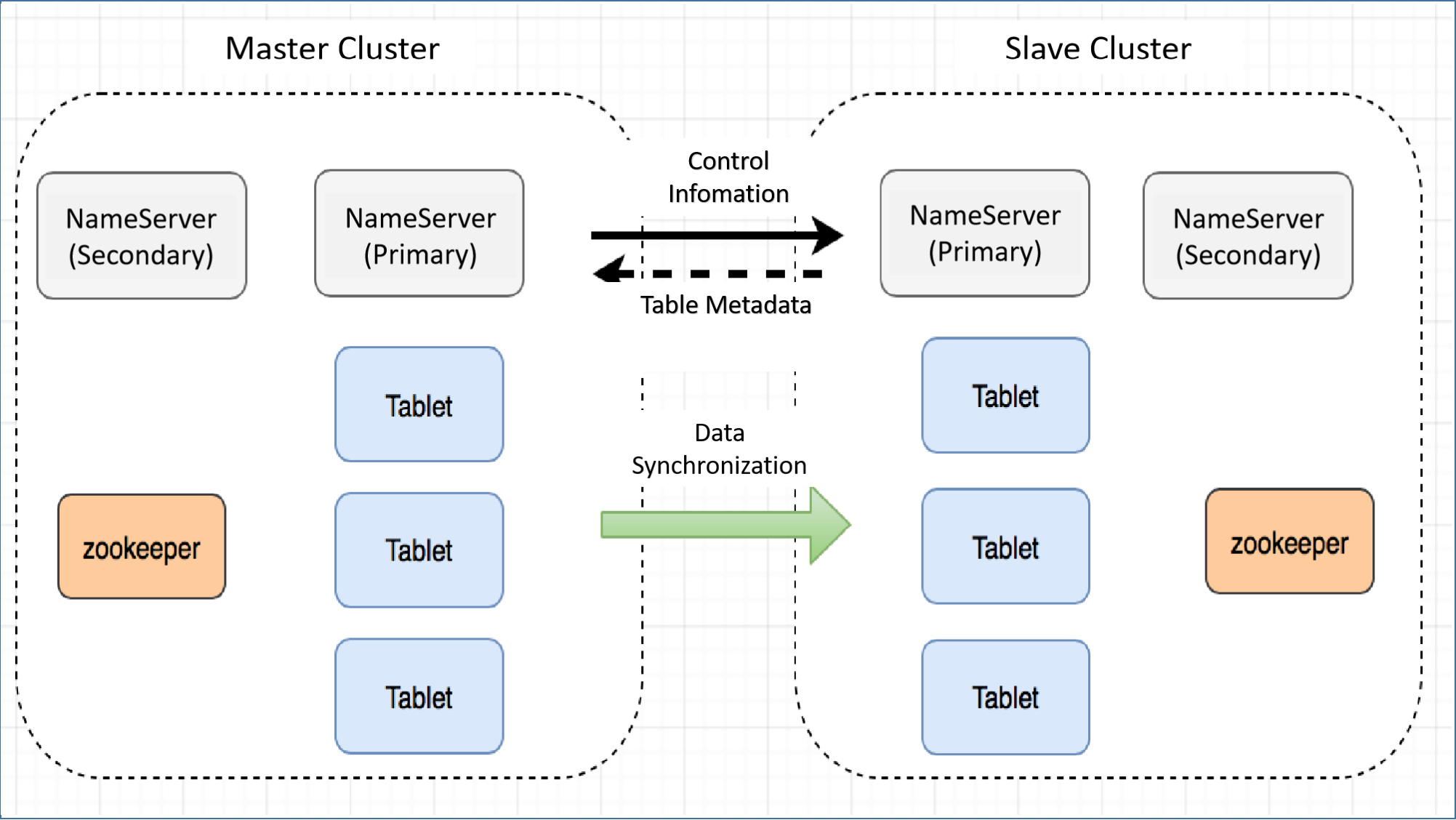
Synchronization information between master-slave clusters primarily encompasses data synchronization and metadata information synchronization.
Initial State
The initial state of the master-slave cluster can fall into one of the following categories:
Both the master and slave clusters contain empty data.
Either the master or slave cluster contains data. The table name and schema are consistent across the master-slave clusters, and the master cluster’s offset is equal to or greater than the slave cluster’s offset. Any discrepancies result in an error.
Metadata Information Synchronization
Metadata information synchronization occurs between the nameservers of the master-slave cluster, following these steps:
Upon establishing the master-slave relationship, the master cluster’s nameserver syncs table information with the slave cluster and creates corresponding tables within the cluster. Note that node count need not match between master-slave clusters, but partition counts in each table must align.
The master cluster’s nameserver periodically fetches table topology information from the slave cluster.
Data Synchronization
Data synchronization between master and slave clusters primarily relies on binlogs. The synchronization logic unfolds as follows:
Within a single cluster: Leader nodes transmit data to follower nodes for synchronization.
Between master and slave clusters: The leader node of the master cluster transmits data to the leader node of the slave cluster for synchronization.
The subsequent visualization illustrates the synchronization logic and data flow direction.
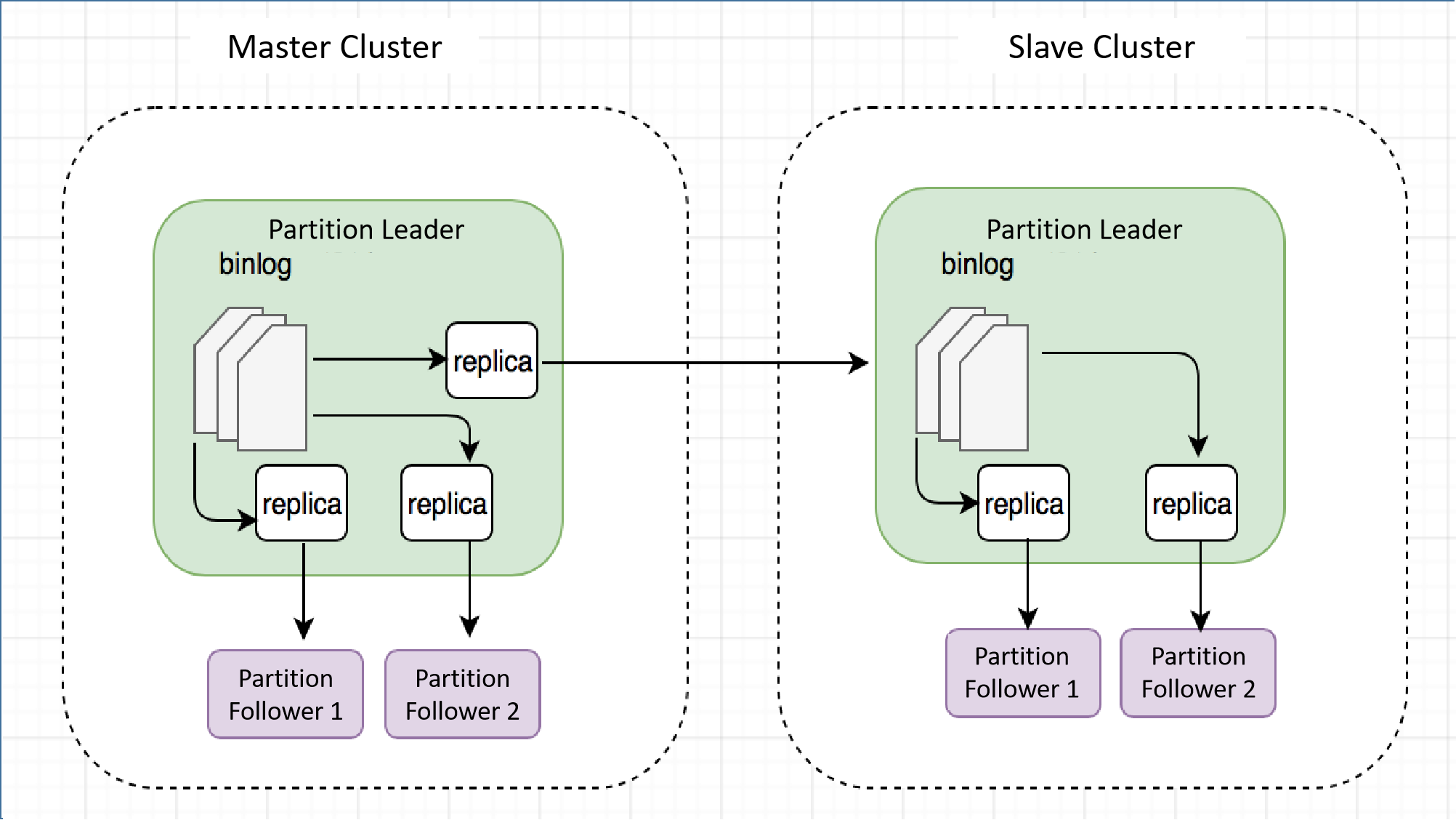
Assuming a slave cluster comprises three replicas of a table, the specific process unfolds as follows: The leader of the master cluster partition initiates the creation of two replicator threads responsible for intra-cluster data synchronization, along with one replicator thread dedicated to synchronizing data to the leader of the slave cluster. Furthermore, two replicator threads are generated from the leader of the slave cluster to synchronize data with the followers within that slave cluster.
The replicator operates based on the following synchronization logic:
It reads the binlog and forwards the data to the follower.
The follower receives the data, appends it to the local binlog, and simultaneously writes it to the local partition table.
By default, the replicator continuously reads the most recent binlog. If no recent data is available, it waits for a brief period (default is 100ms) before attempting to read. In scenarios with stringent synchronization timeliness requirements, adjusting the default configuration (parameter binlog_sync_wait_time, see documentation Configuration File) can reduce latency but may lead to increased CPU resource consumption.
Automatic Failover Within a Cluster
Master cluster’s nameserver offline situation:
If the primary nameserver goes offline in the master cluster, the secondary nameserver will be promoted to become the new primary nameserver. The topology information from the slave cluster’s tables is updated to the new primary nameserver.
No operations if the secondary nameserver goes offline in the master cluster.
Slave cluster’s nameserver offline situation:
If the primary nameserver goes offline in the slave cluster, the secondary nameserver will be promoted to the new primary nameserver. When the master cluster attempts to acquire table topology information from the slave cluster, an error will be returned. Subsequently, the master cluster will retrieve ZooKeeper information from the slave cluster, to get the latest primary nameserver and update the table topology details accordingly.
No operations if the secondary nameserver goes offline in the slave cluster.
Master cluster’s tablet offline situation:
Failover within the master cluster. A new leader will be selected for the corresponding partition.
A data synchronization is established between the new leader and the tablet where the partition resides within the slave cluster.
Slave cluster’s tablet offline situation:
Failover within the slave cluster. A new leader will be selected for the corresponding partitions.
Changes will be noticed when the master cluster’s nameserver acquires topology information from the slave master. Consequently, data synchronization related to altered partitions will be deleted and re-established.
Manual Failover between Master and Slave Clusters
When the master cluster is unavailable: With operations commands, elevate the slave cluster to the master cluster status. Simultaneously, the read and write traffic from the business side needs to be redirected to the new master cluster. This traffic redirection process should be managed by the business-side systems.
When the slave cluster is unavailable: Any existing read traffic from the business side that was directed to the slave cluster (if applicable) needs to be entirely switched to the master cluster. The process of redirecting this traffic should be managed by the business-side systems.
Master-Slave Cluster-Related Commands#
Once the cluster is up and running, it defaults to the master cluster state. Additional clusters can be introduced as slave clusters to existing ones, and manipulation such as switching or removal can be carried out via commands.
Start NS client
Management of the master-slave cluster is handled through the NS (Nameserver) client, which can be initiated using the provided command.
$ ./bin/openmldb --zk_cluster=172.27.2.52:12200 --zk_root_path=/onebox --role=ns_client
zk_Cluster represents the ZooKeeper address, zk_root_path corresponds to the root path of the cluster in ZooKeeper, and role specifies the starting role as ns_client.
For more comprehensive details about the NS client, please see Operations in CLI documentation.
Adding a Slave Cluster
The addrepcluster command is used to include a slave cluster:
addrepcluster $zk_cluster_follower $zk_root_path_follower $cluster_alias
For instance, if you intend to add a slave cluster with the ZooKeeper address 10.1.1.1:2181 and the OpenMLDB root path on ZooKeeper being 10.1.1.2:2181 /openmldb_cluster, and you want to assign the alias prod_dc01 to the slave cluster, execute the following command within the NS client of the master cluster:
addrepcluster 10.1.1.1:2181,10.1.1.2:2181 /openmldb_cluster prod_dc01
This operation integrates the designated slave cluster into the master-slave cluster configuration.
Removing a Slave Cluster
To remove a slave cluster, you can use the removerepcluster command. For instance, to delete the previously added slave cluster named prod_dc01, execute:
removerepcluster prod_dc01
Switching Cluster Roles
The switchmode command is utilized to alter a cluster’s role. The parameter options are leader or normal. To promote a slave cluster to the master cluster, set the parameter as leader. To change it to a regular cluster, set the parameter to normal.
switchmode leader
Query the Slave Cluster
To retrieve information about all slave clusters, use the showrepcluster command. The output provides results in a similar format:

FAQ#
Resolving the Distributed “Brain Split” Issue
In distributed environments, encountering the “brain split” problem is not uncommon. This phenomenon arises when two clusters independently elect different leaders due to certain abnormal conditions, often related to network congestion. Consistency protocols like Raft effectively address similar challenges by enforcing conditions such as the requirement for leaders to garner over half of the votes. OpenMLDB’s approach to host selection, guided by ZooKeeper and nameserver, differs from these protocols. Offline node detection is achieved through ZooKeeper’s ephemeral node mechanism. When choosing a nameserver master, the one with the highest offset among all followers within the cluster is selected as the new leader. Consequently, the fundamental design of OpenMLDB’s master-slave cluster solution eliminates the potential for brain-splitting issues.
Determining Master Cluster Unavailability and the Need for Master-Slave Switching
Currently, OpenMLDB does not autonomously ascertain or perform master-slave switching based on overall cluster unavailability. The master-slave cluster scheme primarily addresses major disruptions such as data center power outages. Therefore, the decision to switch between master and slave clusters depends on subjective evaluation. Common indicators of master cluster unavailability include uncontrolled access issues across the entire cluster, unrecoverable ZooKeeper instances, unresponsive tablets, or extended recovery durations.
Possible Data Loss Scenarios
While the master-slave cluster scheme enhances high availability, it does not guarantee absolute data preservation. Potential data loss scenarios exist, and related matters are slated for resolution or optimization in subsequent versions:
After an internal master cluster tablet failover, if the newly elected leader’s offset is smaller than that of the slave cluster’s leader, data loss may occur within the offset difference.
During master-slave switching, ongoing write traffic in the master cluster might lead to untimely data loss, particularly if synchronization to the slave cluster has not yet taken place.
When changes to the topology of a slave cluster table have not been captured by the master cluster, performing a master-slave switch could result in data loss from the moment of topology alteration to a successful switch.
Support for Multiple Slave Clusters
A master cluster can indeed support multiple slave clusters by executing the addrepcluster command on the master cluster.
Comparison with Other Master-Slave Cluster Solutions in the Industry
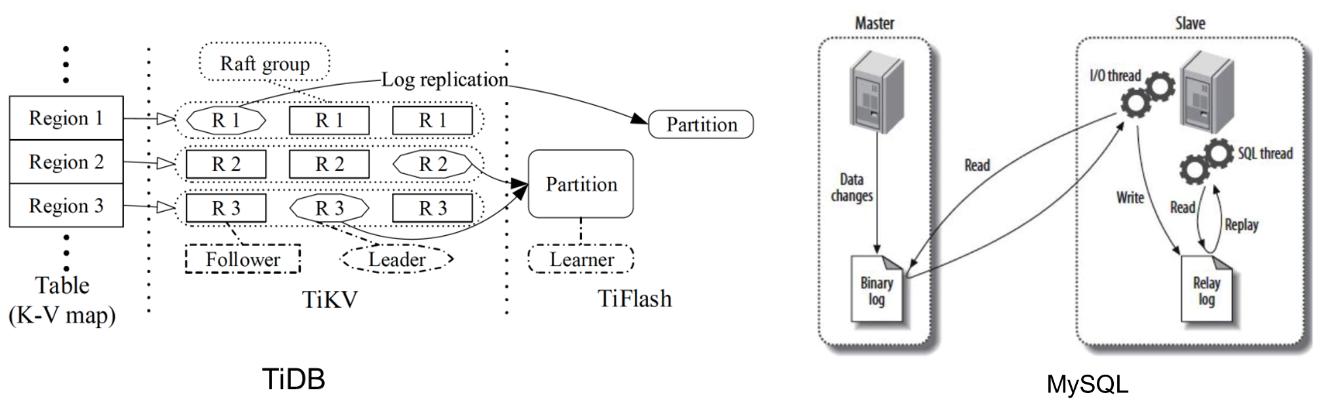
For comparison, two widely used databases in the industry, TiDB and MySQL, are presented. OpenMLDB’s architecture bears similarities to both. TiDB transfers data from TiKV to TiFlash in a similar manner to OpenMLDB’s leader of the slave cluster concept. TiFlash’s Learner parallels this role, synchronizing data from TiKV and performing in-cluster data synchronization. MySQL’s master-slave replication shares similarities, periodically synchronizing data to slave clusters through binlogs and subsequently propagating the synchronization within the cluster via binlogs.
Development Progress#
Currently, the alpha version of the master-slave cluster solution is in the experimental phase, with its core functionalities fully developed and thoroughly tested. The primary outstanding issues are as follows:
Only table creation, table deletion, and data insertion operations in SQL commands can be automatically synchronized between the master and slave clusters. Other commands (such as SQL updates, modifying TTL) are not yet supported for automatic synchronization. They require manual execution separately on both the master and slave clusters.