Introduction
Contents
![]()
Introduction#
OpenMLDB is an open-source machine learning database that provides a feature platform enabling consistent features for training and inference.
Our Philosophy#
For the artificial intelligence (AI) engineering, 95% of the time and effort is consumed by data related workloads. In order to tackle this challenge, tech giants spend thousands of hours on building in-house data and feature platforms to address engineering issues such as data leakage, feature backfilling, and efficiency. The other small and medium-sized enterprises have to purchase expensive SaaS tools and data governance services.
OpenMLDB is an open-source machine learning database that is committed to solving the data and feature challenges. OpenMLDB has been deployed in hundreds of real-world enterprise applications. It prioritizes the capability of feature engineering using SQL for open-source, which offers a feature platform enabling consistent features for training and inference.
A Feature Platform for ML Applications#
Real-time features are essential for many machine learning applications, such as real-time personalized recommendation and risk analytics. However, a feature engineering script developed by data scientists (Python scripts in most cases) cannot be directly deployed into production for online inference because it usually cannot meet the engineering requirements, such as low latency, high throughput and high availability. Therefore, a engineering team needs to be involved to refactor and optimize the source code using database or C++ to ensure its efficiency and robustness. As there are two teams and two toolchains involved for the development and deployment life cycle, the verification for consistency is essential, which usually costs a lot of time and human power.
OpenMLDB is particularly designed as a feature platform for ML applications to accomplish the mission of Development equals Deployment, to significantly reduce the cost from the offline training to online inference. Based on OpenMLDB, there are three steps only for the entire life cycle:
Step 1: Offline development of feature engineering script based on SQL
Step 2: SQL online deployment using just one command
Step 3: Online data source configuration to import real-time data for model inference
With those three steps done, the system is ready to serve real-time features, and is highly optimized to achieve low latency and high throughput for production.
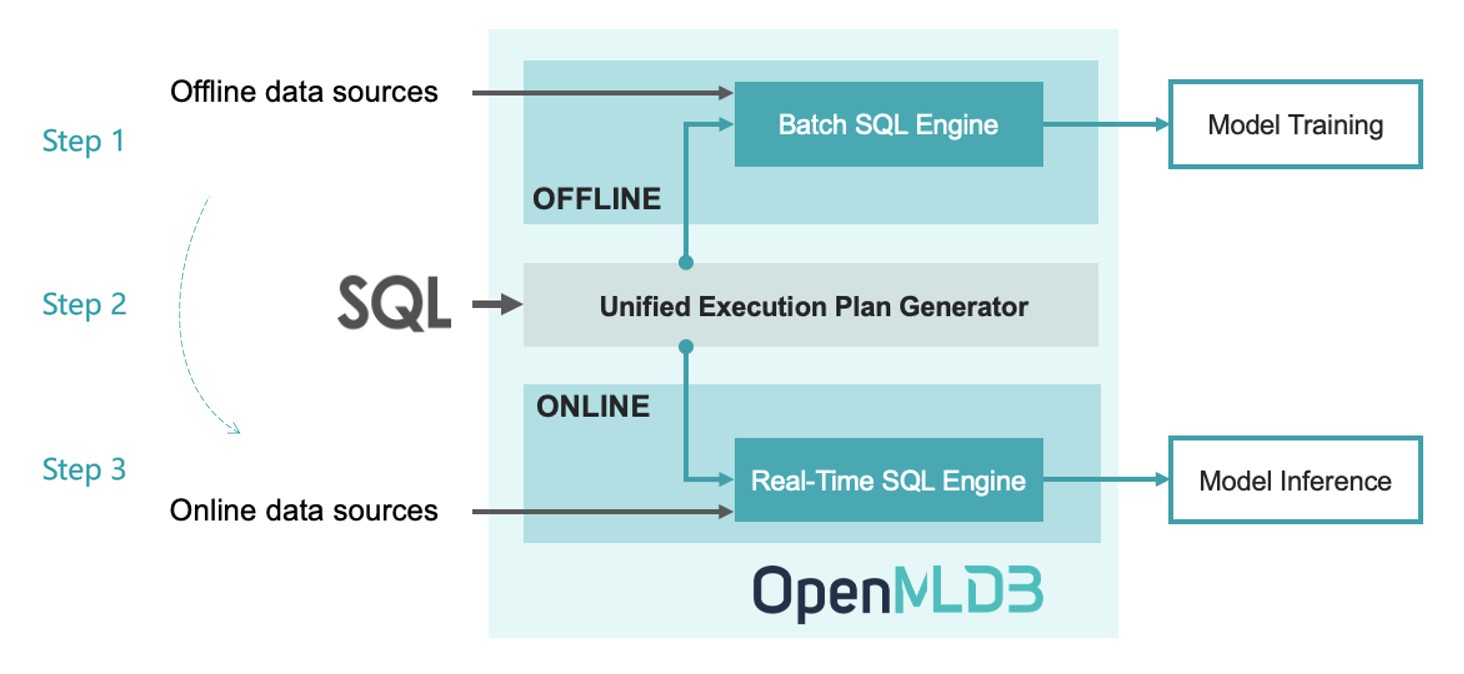
In order to achieve the goal of Development as Deployment, OpenMLDB is designed to provide consistent features for training and inference. The figure above shows the high-level architecture of OpenMLDB, which consists of four key components:
SQL as the unified programming language
The real-time SQL engine for extra-low latency services
The batch SQL engine based on a tailored Spark distribution
The unified execution plan generator to bridge the batch and real-time SQL engines to guarantee the consistency.
Highlights#
Consistent Features for Training and Inference: With the unified execution plan generator, consistent features are guaranteed for offline training and online inference.
Real-Time Features with Ultra-Low Latency: The real-time SQL engine is built from scratch and particularly optimized for time series data. It can achieve the response time of a few milliseconds only to produce real-time features, which significantly outperforms other commercial in-memory database systems (Figures 9 & 10, the VLDB 2021 paper).
Define Features as SQL: SQL is used as the unified programming language to define and manage features. SQL is further enhanced for feature engineering, such as the extended syntax LAST JOIN and WINDOW UNION.
Production-Ready for ML Applications: Production features are seamlessly integrated to support enterprise-grade ML applications, including distributed storage and computing, fault recovery, high availability, seamless scale-out, smooth upgrade, monitoring, heterogeneous memory support, and so on.
FAQ#
What are use cases of OpenMLDB?
At present, it is mainly positioned as a feature platform for ML applications, with the strength of low-latency real-time features. It provides the capability of Development as Deployment to significantly reduce the cost for machine learning applications. On the other hand, OpenMLDB contains an efficient and fully functional time-series database, which is used in finance, IoT and other fields.
How does OpenMLDB evolve?
OpenMLDB originated from the commercial product of 4Paradigm (a leading artificial intelligence service provider). In 2021, the core team has abstracted, enhanced and developed community-friendly features based on the commercial product; and then makes it publicly available as an open-source project to benefit more enterprises to achieve successful digital transformations at low cost. Before the open-source, it had been successfully deployed in hundreds of real-world ML applications together with 4Paradigm’s other commercial products.
Is OpenMLDB a feature store?
OpenMLDB is more than a feature store to provide features for ML applications. OpenMLDB is capable of producing real-time features in a few milliseconds. Nowadays, most feature stores in the market serve online features by syncing features pre-computed at offline. But they are unable to produce low latency real-time features. By comparison, OpenMLDB is taking advantage of its optimized online SQL engine, to efficiently produce real-time features in a few milliseconds.
Why does OpenMLDB choose SQL to define and manage features?
SQL (with extension) has the elegant syntax but yet powerful expression ability. SQL based programming experience flattens the learning curve of using OpenMLDB, and further makes it easier for collaboration and sharing.
Publications#
PECJ: Stream Window Join on Disorder Data Streams with Proactive Error Compensation. Xianzhi Zeng, Shuhao Zhang, Hongbin Zhong, Hao Zhang, Mian Lu, Zhao Zheng, and Yuqiang Chen. International Conference on Management of Data (SIGMOD/PODS) 2024.
Principles and Practices of Real-Time Feature Computing Platforms for ML. Hao Zhang, Jun Yang, Cheng Chen, Siqi Wang, Jiashu Li, and Mian Lu. 2023. Communications of the ACM 66, 7 (July 2023), 77–78.
Scalable Online Interval Join on Modern Multicore Processors in OpenMLDB. Hao Zhang, Xianzhi Zeng, Shuhao Zhang, Xinyi Liu, Mian Lu, and Zhao Zheng. In 2023 IEEE 39rd International Conference on Data Engineering (ICDE) 2023. [code]
FEBench: A Benchmark for Real-Time Relational Data Feature Extraction. Xuanhe Zhou, Cheng Chen, Kunyi Li, Bingsheng He, Mian Lu, Qiaosheng Liu, Wei Huang, Guoliang Li, Zhao Zheng, Yuqiang Chen. International Conference on Very Large Data Bases (VLDB) 2023. [code].
A System for Time Series Feature Extraction in Federated Learning. Siqi Wang, Jiashu Li, Mian Lu, Zhao Zheng, Yuqiang Chen, and Bingsheng He. 2022. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management (CIKM) 2022. [code].
Optimizing in-memory database engine for AI-powered on-line decision augmentation using persistent memory. Cheng Chen, Jun Yang, Mian Lu, Taize Wang, Zhao Zheng, Yuqiang Chen, Wenyuan Dai, Bingsheng He, Weng-Fai Wong, Guoan Wu, Yuping Zhao, and Andy Rudoff. International Conference on Very Large Data Bases (VLDB) 2021.