

Kubernetes is a widely adopted cloud-native container orchestration and management tool in the industry that has been extensively used in project implementations. Currently, both the offline and online engines of OpenMLDB have complete support for deployment based on Kubernetes, enabling more convenient management functionalities. This article will respectively introduce the deployment strategies of the offline and online engines based on Kubernetes.
It's important to note that the deployment of the offline engine and the online engine based on Kubernetes are entirely decoupled. Users have the flexibility to deploy either the offline or online engine based on their specific requirements.
Besides Kubernetes-based deployment, the offline engine also supports deployment in local mode and yarn mode. Similarly, the online engine supports a native deployment method that doesn't rely on containers. These deployment strategies can be flexibly mixed and matched in practical scenarios to meet the demands of production environments.
Offline Engine with Kubernetes Backend
Deployment of Kubernetes Operator for Apache Spark
Please refer to spark-on-k8s-operator official documentation. The following is the command to deploy to the default namespace using Helm. Modify the namespace and permission as required.
helm install my-release spark-operator/spark-operator --namespace default --create-namespace --set webhook.enable=true
kubectl create serviceaccount spark --namespace default
kubectl create clusterrolebinding binding --clusterrole=edit --serviceaccount=default:sparkAfter successful deployment, you can use the code examples provided by spark-operator to test whether Spark tasks can be submitted normally.
HDFS Support
If you need to configure Kubernetes tasks to read and write HDFS data, you need to prepare a Hadoop configuration file in advance and create a ConfigMap. You can modify the ConfigMap name and file path as needed. The creation command example is as follows:
kubectl create configmap hadoop-config --from-file=/tmp/hadoop/etc/Offline Engine Configurations for Kubernetes Support
The configuration file for TaskManager in the offline engine can be configured for Kubernetes support, respective settings are:
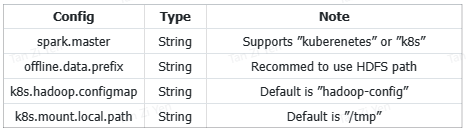
If Kubernetes is used to run the offline engine, the user's computation tasks will run on the cluster. Therefore, it's recommended to configure the offline storage path as an HDFS path; otherwise, it might lead to data read/write failures in tasks. Example configuration for the item is as follows:
offline.data.prefix=hdfs:///foo/bar/*Note: For a complete configuration file example for TaskManager in OpenMLDB offline engine, visit: https://openmldb.ai/docs/en/main/deploy/conf.html#he-configuration-file-for-taskmanager-conf-taskmanager-properties
Task Submission and Management
After configuring TaskManager and Kubernetes, you can submit offline tasks via the command line. The usage is similar to that of the local or YARN mode, allowing not only usage within the SQL command-line client but also via SDKs in various programming languages.
For instance, to submit a data import task:
LOAD DATA INFILE 'hdfs:///hosts' INTO TABLE db1.t1 OPTIONS(delimiter = ',', mode='overwrite');Check Hadoop ConfigMap:
kubectl get configmap hdfs-config -o yamlCheck Spark job and Pod log:
kubectl get SparkApplicationkubectl get podsOnline Engine Deployment with Kubernetes
Github
The deployment of online engine based on Kubernetes is supported as a separate tool for OpenMLDB. Its source code repository is located at: https://github.com/4paradigm/openmldb-k8s
Requirement
This deployment tool offers a Kubernetes-based deployment solution for the OpenMLDB online engine, implemented using Helm Charts. The tool has been tested and verified with the following versions:
- Kubernetes 1.19+
- Helm 3.2.0+
Additionally, for users who utilize pre-compiled OpenMLDB images from Docker Hub, only OpenMLDB versions >= 0.8.2 are supported. Users also have the option to create other versions of OpenMLDB images using the tool described in the last section of this article.
Preparation: Deploy ZooKeeper
If there is an available ZooKeeper instance, you can skip this step. Otherwise, proceed with the installation process:
helm install zookeeper oci://registry-1.docker.io/bitnamicharts/zookeeper --set persistence.enabled=falseYou can specify a previously created storage class for persistent storage:
helm install zookeeper oci://registry-1.docker.io/bitnamicharts/zookeeper --set persistence.storageClass=local-storageFor more parameter settings, refer to here
OpenMLDB Deployment
Download Source Code
Download the source code and set the working directory to the root directory of the repository.
git clone https://github.com/4paradigm/openmldb-k8s.git
cd openmldb-k8sConfigure ZooKeeper Address
Modify the zk_cluster in the charts/openmldb/conf/tablet.flags and charts/openmldb/conf/nameserver.flags files to the actual ZooKeeper address, with the default zk_root_path set to /openmldb.
Deploy OpenMLDB
You can achieve one-click deployment using Helm with the following commands:
helm install openmldb ./charts/openmldbUsers have the flexibility to configure additional deployment options using the --set command. Detailed information about supported options can be found in the OpenMLDB Chart Configuration.
Important configuration considerations include:
- By default, temporary files are used for data storage, which means that data may be lost if the pod restarts. It is recommended to associate a Persistent Volume Claim (PVC) with a specific storage class using the following method:
helm install openmldb ./charts/openmldb --set persistence.dataDir.enabled=true --set persistence.dataDir.storageClass=local-storage- By default, the
4pdosc/openmldb-onlineimage from Docker Hub is utilized (supporting OpenMLDB >= 0.8.2). If you prefer to use a custom image, you can specify the image name during installation with--set image.openmldbImage. For information on creating custom images, refer to the last section of this article.
helm install openmldb ./charts/openmldb --set image.openmldbImage=openmldb-online:0.8.4Note
- Deployed OpenMLDB services can only be accessed within the same namespace within Kubernetes.
- The OpenMLDB cluster deployed using this method does not include a TaskManager module. Consequently, statements such as LOAD DATA and SELECT INTO, and offline-related functions are not supported. If you need to import data into OpenMLDB, you can use OpenMLDB's Online Import Tool, OpenMLDB Connector, or SDK. For exporting table data, the Online Data Export Tool can be utilized.
- For production, it's necessary to disable Transparent Huge Pages (THP) on the physical node where Kubernetes deploys the tablet. Failure to do so may result in issues where deleted tables cannot be fully released. For instructions on disabling THP, please refer to this link.
Create Docker Image
The default deployment uses the OpenMLDB docker image from Docker Hub. Users can also create their local docker image. The creation tool is located in the repository (https://github.com/4paradigm/openmldb-k8s) as docker/build.sh.
This script supports two parameters:
- OpenMLDB version number.
- Source of the OpenMLDB package. By default, it pulls the package from a mirror in mainland China. If you want to pull it from GitHub, you can set the second parameter to
github.
cd docker
sh build.sh 0.8.4For more information on OpenMLDB:
- Official website: https://openmldb.ai/
- GitHub: https://github.com/4paradigm/OpenMLDB
- Documentation: https://openmldb.ai/docs/en/
- Join us on Slack !




