

导读:人工智能工程化落地的关键点之一,在于解决真实业务场景的实时批量预估和实时模型更新问题。更好更快地将线上实时数据转化为AI可用的特征,将加速AI应用落地的效率及效果。为此,OpenMLDB 和 Apache Pulsar 合作推出OpenMLDB Pulsar Connector,实现稳定的流式集成,为高效打通实时数据到特征工程提供一条值得期待的清晰路径。
我是黄威,目前是第四范式研发架构师,也是OpenMLDB的核心研发。今天主要为大家介绍三个方面的内容:
1. 定位
OpenMLDB Pulsar Connector,高效打通实时数据到特征工程,大幅提升数据使用效率、助力开发者构建实时数据管道、使企业更专注和更高效的探索数据的商业价值。
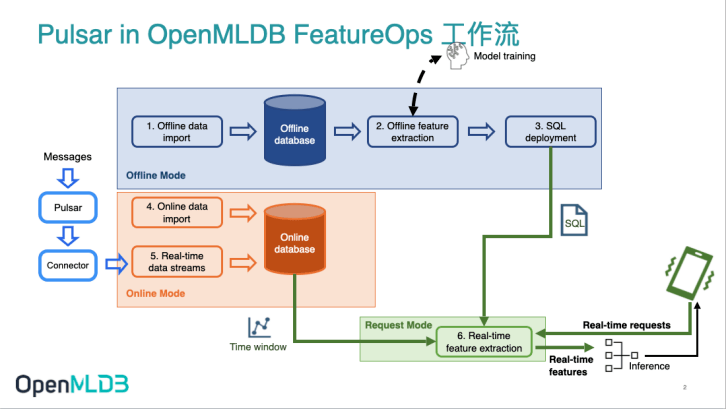
在OpenMLDB 的工作流中,Pulsar Connector(位置如下图所示)帮助开发者轻松地将消息系统Pulsar与开源机器学习数据库OpenMLDB连接起来,形成一条实时数据流。
- Pulsar Connector简介
- OpenMLDB Connector on Pulsar介绍
- OpenMLDB Connector on Pulsar演示
01 Pulsar Connector简介
Apache Pulsar 是一个云原生的,分布式消息流平台。它可以作为 OpenMLDB 的在线数据源,将实时的数据流导入到 OpenMLDB 在线。Pulsar 提供了Connector 框架,在此基础上可以与不同系统的对接。我们基于Connector框架,开发了 OpenMLDB JDBC Connector,通过它我们就可以无障碍地连接 Pulsar与OpenMLDB,Pulsar的消息将自动地写入OpenMLDB。02 OpenMLDB-Pulsar Connector介绍
1. 定位
OpenMLDB Pulsar Connector,高效打通实时数据到特征工程,大幅提升数据使用效率、助力开发者构建实时数据管道、使企业更专注和更高效的探索数据的商业价值。
在OpenMLDB 的工作流中,Pulsar Connector(位置如下图所示)帮助开发者轻松地将消息系统Pulsar与开源机器学习数据库OpenMLDB连接起来,形成一条实时数据流。
2. 功能
Pulsar可以使用connector来连接其他系统。Source connector可以使其他系统的数据流入Pulsar,sink connector可以将消息流出至其他系统。
OpenMLDB Pulsar Connector支持了sink功能,使Pulsar消息可以写入到OpenMLDB在线存储中。
可以通过 Connector Admin CLI并结合 sinks 子命令来管理 Pulsar connector(例如,创建、更新、启动、停止、重启、重载、删除以及其他操作)。
3. 优势
想要使OpenMLDB与Pulsar拥有稳定的流式集成,我们推荐直接使用Pulsar OpenMLDB connector 。它具备诸多优势,包括但不限于:
- 易上手。无需编写任何代码,只需进行简单配置,便可通过OpenMLDB Pulsar Connector 将Pulsar的消息流入 OpenMLDB 。简化的数据导入过程能大幅提升企业的数据使用效率。
- 易扩展。根据不同的业务需求,可以选择在单机或集群上运行 OpenMLDB Pulsar Connector ,助力企业构建实时数据管道。
- 可持续。OpenMLDB Pulsar Connector 简单的安装和部署过程,使企业能更专注和更高效地探索数据的商业价值。
4.Connector下载地址
OpenMLDB Pulsar Connector:
https://github.com/4paradigm/OpenMLDB/releases/download/v0.4.4/pulsar-io-jdbc-openmldb-2.11.0-SNAPSHOT.nar
03 Connector演示
1. 流程介绍
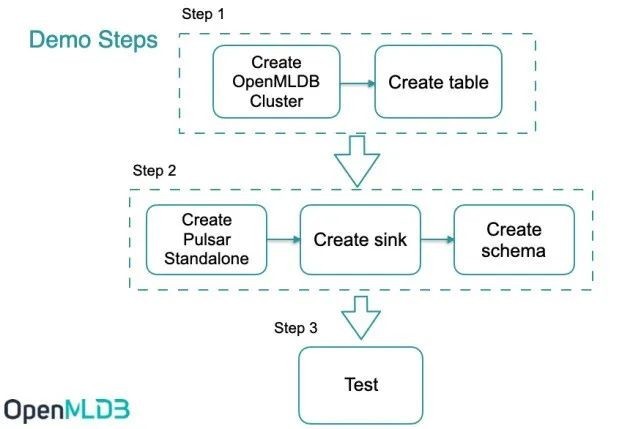
Pulsar OpenMLDB connector 用于 OpenMLDB 线上模式的实时数据流接入。使用connector的简要流程,如下图所示。我们接下来将详细介绍每一步。
整体上,使用流程可以概括为三步:
- 创建connector前需要启动OpenMLDB集群,并创建表。
- 创建Pulsar standalone,创建sink,sink配置中使用OpenMLDB集群的JDBC地址。并且,创建用于解析消息的schema。
- 向Pulsar发送消息,来测试消息是否能自动写入到OpenMLDB。
2. 关键步骤
注意,为了使演示更简单,本文中将使用Pulsar Standalone,OpenMLDB集群和一个简单JSON消息生产者程序,来演示OpenMLDB JDBC Connector是如何工作的。该connector是完全可以在Pulsar Cluster中正常使用的。
步骤1 | 在 OpenMLDB 创建数据库和数据表
① 启动 OpenMLDB 集群
使用Docker可以快速启动OpenMLDB,除此之外,我们还需要创建测试用的表。
提醒:目前只有OpenMLDB集群版可以作为sink的接收端,数据只会sink到集群的在线存储中。
我们更推荐你使用host network模式运行docker,以及绑定文件目录files,sql脚本在该目录中。
docker run -dit --network host -v `pwd`/files:/work/taxi-trip/files --name openmldb 4pdosc/openmldb:0.4.4 bash
在OpenMLDB容器中,启动集群:
./init.sh
需要注意的是,在macOS平台上,即使使用host网络,也不支持从容器外部去连接容器内的 OpenMLDB 服务器。但从容器内,去连接别的容器内的OpenMLDB服务,是可行的。
② 创建表
我们使用一个脚本快速创建表,脚本内容如下:
create database pulsar_test;
use pulsar_test;
create table connector_test(id string, vendor_id int, pickup_datetime bigint, dropoff_datetime bigint, passenger_count int, pickup_longitude double, pickup_latitude double, dropoff_longitude double, dropoff_latitude double, store_and_fwd_flag string, trip_duration int);
desc connector_test;
执行脚本:
../openmldb/bin/openmldb --zk_cluster=127.0.0.1:2181 --zk_root_path=/openmldb --role=sql_client < files/create.sql
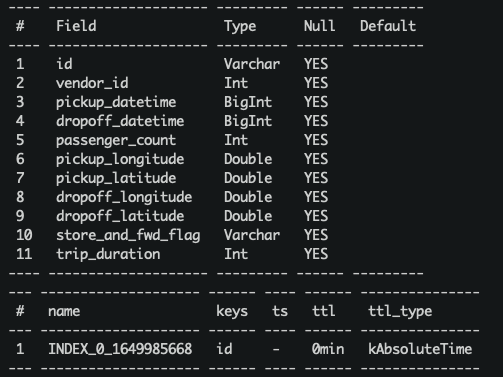 目前,Pulsar中JSONSchema和JDBC base connector都不支java.sql.Timestamp。所以我们使用long作为timestamp列的数据类型(在OpenMLDB可以使用long作为时间戳)。
步骤2 | 启动Pulsar,创建sink和schem
① 启动 Pulsar Standalone
使用docker,可以更简单快速地启动Pulsar。我们推荐你使用host network来运行docker,这样可以避免诸多容器相关的网络连接问题。而且,我们需要使用pulsar-admin来进行sink创建,这个程序在Pulsar镜像内。所以,我们使用bash运行容器,在容器内部逐一执行命令。此处,也需要绑定files文件目录。
目前,Pulsar中JSONSchema和JDBC base connector都不支java.sql.Timestamp。所以我们使用long作为timestamp列的数据类型(在OpenMLDB可以使用long作为时间戳)。
步骤2 | 启动Pulsar,创建sink和schem
① 启动 Pulsar Standalone
使用docker,可以更简单快速地启动Pulsar。我们推荐你使用host network来运行docker,这样可以避免诸多容器相关的网络连接问题。而且,我们需要使用pulsar-admin来进行sink创建,这个程序在Pulsar镜像内。所以,我们使用bash运行容器,在容器内部逐一执行命令。此处,也需要绑定files文件目录。
docker run -dit --network host -v `pwd`/files:/pulsar/files --name pulsar apachepulsar/pulsar:2.9.1 bash
在Pulsar容器中,启动standalone服务端。
bin/pulsar-daemon start standalone --zookeeper-port 5181
OpenMLDB服务已经使用了端口2181,所以此处我们为Pulsar重新设置一个zk端口。我们将使用端口2181来连接OpenMLDB,但Pulsar standalone内的zk端口不会对外造成影响。
你可以检查一下Pulsar是否正常运行,可以使用ps或者检查日志。
ps axu|grep pulsar
当你启动一个本地standalone集群,会自动创建pulic/default namesapce。这个namespace用于开发,我们将在此namespace中创建sink。
如果你想要在本地直接启动Pulsar,可以参考Set up a standalone Pulsar locally。
链接:https://pulsar.apache.org/docs/en/standalone/
Q&A
Q1: 碰到以下问题是什么原因
2022-04-07T03:15:59,289+0000 [main] INFO org.apache.zookeeper.server.NIOServerCnxnFactory - binding to port 0.0.0.0/0.0.0.0:5181
2022-04-07T03:15:59,289+0000 [main] ERROR org.apache.pulsar.zookeeper.LocalBookkeeperEnsemble - Exception while instantiating ZooKeeper
java.net.BindException: Address already in use
A: Pulsar需要一个未被使用的端口来启动zk,端口5181页已经被使用,需要再更改一下–zookeeper-port的端口号。
Q2: 8080端口已被使用?
A: 8080是webServicePort默认配置端口,在conf/standalone.conf中,可以更换这个端口。但注意,pulsar-admin会使用conf/client.conf中的webServiceUrl进行连接,也需要同步更改。
Q3: 6650端口已被使用?
A: 需要同步更改conf/standalone.conf中的brokerServicePort和conf/client.conf中的brokerServiceUrl配置项。
② Connector安装(Optional)
前面的步骤中我们绑定了files目录,里面已经提供了connector的nar包。我们可以使用“非内建connector”模式来设置connector(即在sink配置中指定archive配置项,将在下一个步骤中描述)。
但如果你希望将OpenMLDB connector作为内建的connector,你需要创建connectors目录,并拷贝nar文件到connectors目录。
mkdir connectors
cp files/pulsar-io-jdbc-openmldb-2.11.0-SNAPSHOT.nar connectors
如果在Pulsar运行时,你想改变或增加connector,你可以通知Pulsar更新信息:
bin/pulsar-admin sinks reload
当OpenMLDB connector成为内建connector时,它的sink类型名为jdbc-openmldb,你可以直接使用这个类型名来指定使用OpenMLDB connector。
③ 创建sink
我们使用public/default这个namespace来创建sink, 我们需要一个sink的配置文件, 它在files/pulsar-openmldb-jdbc-sink.yaml,内容如下:
tenant: "public"
namespace: "default"
name: "openmldb-test-sink"
archive: "files/pulsar-io-jdbc-openmldb-2.11.0-SNAPSHOT.nar"
inputs: ["test_openmldb"]
configs:
jdbcUrl: "jdbc:openmldb:///pulsar_test?zk=localhost:2181&zkPath=/openmldb"
tableName: "connector_test"
其中:
- name:sink名。
- archive:我们使用archive来指定sink connector, 所以这里我们是将OpenMLDB connector当作非内建connector使用。
- input:可以是多个topic的名字,本文只使用一个。
- config:用于连接OpenMLDB集群的jdbc配置。
接下来,创建这个sink并检查。注意,我们设置的输入topic是‘test_openmldb’,后续步骤需要使用到。
./bin/pulsar-admin sinks create --sink-config-file files/pulsar-openmldb-jdbc-sink.yaml
./bin/pulsar-admin sinks status --name openmldb-test-sink
 ④ 创建 Schema
上传schema到topic test_openmldb,schema类型是JSON格式。后续步骤中,我们将生产一样schema的JSON消息。schema文件是files/openmldb-table-schema,内容如下:
④ 创建 Schema
上传schema到topic test_openmldb,schema类型是JSON格式。后续步骤中,我们将生产一样schema的JSON消息。schema文件是files/openmldb-table-schema,内容如下:
{
"type": "JSON",
"schema":"{\"type\":\"record\",\"name\":\"OpenMLDBSchema\",\"namespace\":\"com.foo\",\"fields\":[{\"name\":\"id\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"vendor_id\",\"type\":\"int\"},{\"name\":\"pickup_datetime\",\"type\":\"long\"},{\"name\":\"dropoff_datetime\",\"type\":\"long\"},{\"name\":\"passenger_count\",\"type\":\"int\"},{\"name\":\"pickup_longitude\",\"type\":\"double\"},{\"name\":\"pickup_latitude\",\"type\":\"double\"},{\"name\":\"dropoff_longitude\",\"type\":\"double\"},{\"name\":\"dropoff_latitude\",\"type\":\"double\"},{\"name\":\"store_and_fwd_flag\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"trip_duration\",\"type\":\"int\"}]}",
"properties": {}
}
上传并检查schema的命令,如下所示:
./bin/pulsar-admin schemas upload test_openmldb -f ./files/openmldb-table-schema
./bin/pulsar-admin schemas get test_openmldb
 步骤3 | 测试
① 发送消息
我们使用两条OpenMLDB镜像中data/taxi_tour_table_train_simple.csv的样本数据,作为测试用的消息。数据如下图所示:
测试用Producer关键代码如下:
可以看到,producer将发送两条消息到topic test_openmldb。这之后,Pulsar将读到消息,并将其写入OpenMLDB集群的在线存储中。
程序包在files中,你可以直接运行它:
步骤3 | 测试
① 发送消息
我们使用两条OpenMLDB镜像中data/taxi_tour_table_train_simple.csv的样本数据,作为测试用的消息。数据如下图所示:
测试用Producer关键代码如下:
可以看到,producer将发送两条消息到topic test_openmldb。这之后,Pulsar将读到消息,并将其写入OpenMLDB集群的在线存储中。
程序包在files中,你可以直接运行它:
java -cp files/pulsar-client-java-1.0-SNAPSHOT-jar-with-dependencies.jar org.example.Client
② 检查
我们可以检查Pulsar中的sink状态:
./bin/pulsar-admin sinks status --name openmldb-test-sink
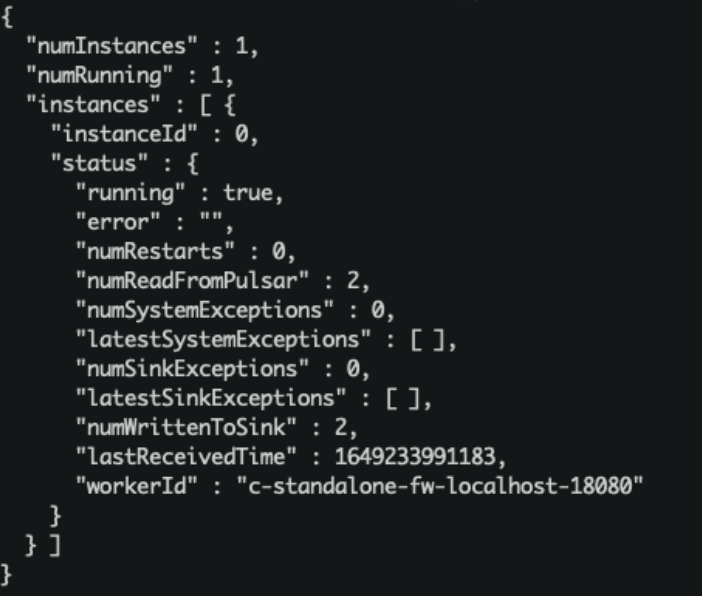 “numReadFromPulsar”: pulsar发送了2条message到sink实例中。
“numWrittenToSink”: sink实例向OpenMLDB写入2条message。
同样,我们可以在OpenMLDB在线存储中查询到这些消息数据。查询脚本select.sql内容如下:
“numReadFromPulsar”: pulsar发送了2条message到sink实例中。
“numWrittenToSink”: sink实例向OpenMLDB写入2条message。
同样,我们可以在OpenMLDB在线存储中查询到这些消息数据。查询脚本select.sql内容如下:
set @@execute_mode='online';
use pulsar_test;
select *, string(timestamp(pickup_datetime)), string(timestamp(dropoff_datetime)) from connector_test;
在OpenMLDB容器中执行脚本:
../openmldb/bin/openmldb --zk_cluster=127.0.0.1:2181 --zk_root_path=/openmldb --role=sql_client < files/select.sq
04 写在最后
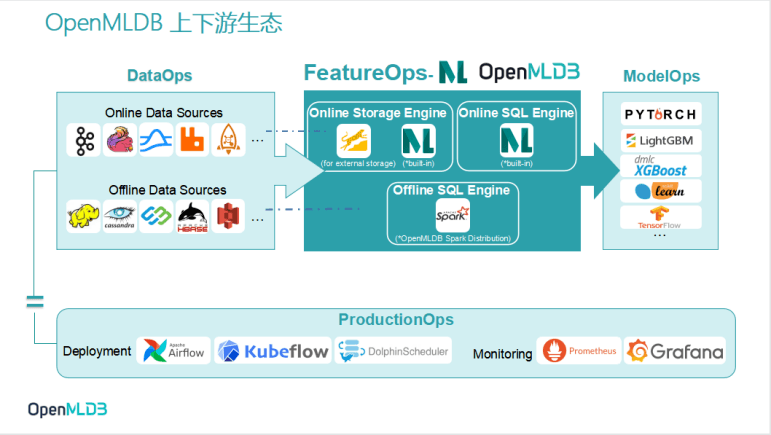
1.OpenMLDB上下游生态体系
为更好降低开发者使用OpenMLDB的门槛,OpenMLDB社区将持续打造面向上下游技术组件的生态圈,为开发者提供更多简单易用的生态Connector(如下图所示):
- 面向线上数据生态,如Kafka, Flin, RabbitMQ, RocketMQ等
- 面向离线数据生态,如HDFS, HBase, Cassandra, S3等
- 面向模型构建的算法、框架,例如XGBoost, LightGBM, TensorFlow, PyTorch, Scikit Learn等
- 面向机器学习建模全流程的调度框架、部署工具,例如Airflow,Kubeflow,DolphinScheduler,Prometheus,Grafana等
2. OpenMLDB Roadmap v0.5.0
OpenMLDB社区将于4月底发布v0.5.0版本
(链接:https://github.com/4paradigm/OpenMLDB/issues/1506),届时OpenMLDB将具备新特性如下:
- 窗口预聚合技术,指数级提升长窗口聚合性能
- 完善的监控, trace 和 profiling 能力,在企业级应用环境中大幅提升稳定性、可观测性、和可分析性
- 线上存储引擎可插拔以适配不同业务需求,既可以支持基于内存的高性能存储引擎,也可以支持基于外存的大容量低成本存储引擎,还可以支持基于持久内存的存储引擎以在性能和成本间保持平衡
- 用户自定义函数(UDF)支持,大幅提升易用性和适用性
- 上下游数据源生态整合,提供线上数据源的 Kafka, Pulsar connectors
05 相关阅读
① https://github.com/4paradigm/OpenMLDB/issues/1506
(OpenMLDB Pulsar Connector)
② https://openmldb.ai/docs/zh/v0.4/about/index.html
(OpenMLDB文档)
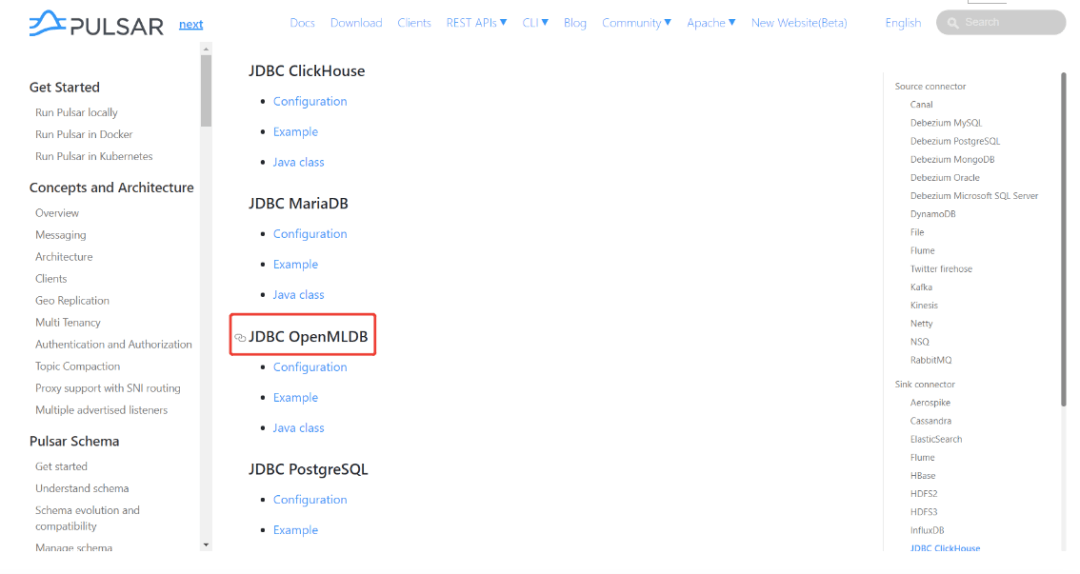
③ https://pulsar.apache.org/docs/en/next/io-connectors/
(Apache Pulsar connector文档, OpenMLDB Pulsar Connector位置如图所示)
 希望这篇文章能够帮助大家认识Pulsar Connector的开发流程,理解OpenMLDB Connector on Pulsar是什么样的,了解Pulsar如何接入OpenMLDB。
最后,AI 的进步需要付出多方面的努力,而开放式协作是其中的关键环节,我们期待来自开发者的交流讨论。欢迎大家加入OpenMLDB社区,通过下图渠道可加入社区技术交流微信群。
希望这篇文章能够帮助大家认识Pulsar Connector的开发流程,理解OpenMLDB Connector on Pulsar是什么样的,了解Pulsar如何接入OpenMLDB。
最后,AI 的进步需要付出多方面的努力,而开放式协作是其中的关键环节,我们期待来自开发者的交流讨论。欢迎大家加入OpenMLDB社区,通过下图渠道可加入社区技术交流微信群。
 今天的分享就到这里,谢谢大家。
今天的分享就到这里,谢谢大家。
3. 优势
想要使OpenMLDB与Pulsar拥有稳定的流式集成,我们推荐直接使用Pulsar OpenMLDB connector 。它具备诸多优势,包括但不限于:
- 易上手。无需编写任何代码,只需进行简单配置,便可通过OpenMLDB Pulsar Connector 将Pulsar的消息流入 OpenMLDB 。简化的数据导入过程能大幅提升企业的数据使用效率。
- 易扩展。根据不同的业务需求,可以选择在单机或集群上运行 OpenMLDB Pulsar Connector ,助力企业构建实时数据管道。
- 可持续。OpenMLDB Pulsar Connector 简单的安装和部署过程,使企业能更专注和更高效地探索数据的商业价值。
4.Connector下载地址
OpenMLDB Pulsar Connector:
https://github.com/4paradigm/OpenMLDB/releases/download/v0.4.4/pulsar-io-jdbc-openmldb-2.11.0-SNAPSHOT.nar
03 Connector演示
1. 流程介绍
Pulsar OpenMLDB connector 用于 OpenMLDB 线上模式的实时数据流接入。使用connector的简要流程,如下图所示。我们接下来将详细介绍每一步。
整体上,使用流程可以概括为三步:
- 创建connector前需要启动OpenMLDB集群,并创建表。
- 创建Pulsar standalone,创建sink,sink配置中使用OpenMLDB集群的JDBC地址。并且,创建用于解析消息的schema。
- 向Pulsar发送消息,来测试消息是否能自动写入到OpenMLDB。
2. 关键步骤
注意,为了使演示更简单,本文中将使用Pulsar Standalone,OpenMLDB集群和一个简单JSON消息生产者程序,来演示OpenMLDB JDBC Connector是如何工作的。该connector是完全可以在Pulsar Cluster中正常使用的。
步骤1 | 在 OpenMLDB 创建数据库和数据表
① 启动 OpenMLDB 集群
使用Docker可以快速启动OpenMLDB,除此之外,我们还需要创建测试用的表。
提醒:目前只有OpenMLDB集群版可以作为sink的接收端,数据只会sink到集群的在线存储中。
我们更推荐你使用host network模式运行docker,以及绑定文件目录files,sql脚本在该目录中。
docker run -dit --network host -v `pwd`/files:/work/taxi-trip/files --name openmldb 4pdosc/openmldb:0.4.4 bash
在OpenMLDB容器中,启动集群:
./init.sh
需要注意的是,在macOS平台上,即使使用host网络,也不支持从容器外部去连接容器内的 OpenMLDB 服务器。但从容器内,去连接别的容器内的OpenMLDB服务,是可行的。
② 创建表
我们使用一个脚本快速创建表,脚本内容如下:
create database pulsar_test;
use pulsar_test;
create table connector_test(id string, vendor_id int, pickup_datetime bigint, dropoff_datetime bigint, passenger_count int, pickup_longitude double, pickup_latitude double, dropoff_longitude double, dropoff_latitude double, store_and_fwd_flag string, trip_duration int);
desc connector_test;
执行脚本:
../openmldb/bin/openmldb --zk_cluster=127.0.0.1:2181 --zk_root_path=/openmldb --role=sql_client < files/create.sql
目前,Pulsar中JSONSchema和JDBC base connector都不支java.sql.Timestamp。所以我们使用long作为timestamp列的数据类型(在OpenMLDB可以使用long作为时间戳)。
步骤2 | 启动Pulsar,创建sink和schem
① 启动 Pulsar Standalone
使用docker,可以更简单快速地启动Pulsar。我们推荐你使用host network来运行docker,这样可以避免诸多容器相关的网络连接问题。而且,我们需要使用pulsar-admin来进行sink创建,这个程序在Pulsar镜像内。所以,我们使用bash运行容器,在容器内部逐一执行命令。此处,也需要绑定files文件目录。
docker run -dit --network host -v `pwd`/files:/pulsar/files --name pulsar apachepulsar/pulsar:2.9.1 bash
在Pulsar容器中,启动standalone服务端。
bin/pulsar-daemon start standalone --zookeeper-port 5181
OpenMLDB服务已经使用了端口2181,所以此处我们为Pulsar重新设置一个zk端口。我们将使用端口2181来连接OpenMLDB,但Pulsar standalone内的zk端口不会对外造成影响。
你可以检查一下Pulsar是否正常运行,可以使用ps或者检查日志。
ps axu|grep pulsar
当你启动一个本地standalone集群,会自动创建pulic/default namesapce。这个namespace用于开发,我们将在此namespace中创建sink。
如果你想要在本地直接启动Pulsar,可以参考Set up a standalone Pulsar locally。
链接:https://pulsar.apache.org/docs/en/standalone/
Q&A
Q1: 碰到以下问题是什么原因
2022-04-07T03:15:59,289+0000 [main] INFO org.apache.zookeeper.server.NIOServerCnxnFactory - binding to port 0.0.0.0/0.0.0.0:5181
2022-04-07T03:15:59,289+0000 [main] ERROR org.apache.pulsar.zookeeper.LocalBookkeeperEnsemble - Exception while instantiating ZooKeeper
java.net.BindException: Address already in use
A: Pulsar需要一个未被使用的端口来启动zk,端口5181页已经被使用,需要再更改一下–zookeeper-port的端口号。
Q2: 8080端口已被使用?
A: 8080是webServicePort默认配置端口,在conf/standalone.conf中,可以更换这个端口。但注意,pulsar-admin会使用conf/client.conf中的webServiceUrl进行连接,也需要同步更改。
Q3: 6650端口已被使用?
A: 需要同步更改conf/standalone.conf中的brokerServicePort和conf/client.conf中的brokerServiceUrl配置项。
② Connector安装(Optional)
前面的步骤中我们绑定了files目录,里面已经提供了connector的nar包。我们可以使用“非内建connector”模式来设置connector(即在sink配置中指定archive配置项,将在下一个步骤中描述)。
但如果你希望将OpenMLDB connector作为内建的connector,你需要创建connectors目录,并拷贝nar文件到connectors目录。
mkdir connectors
cp files/pulsar-io-jdbc-openmldb-2.11.0-SNAPSHOT.nar connectors
如果在Pulsar运行时,你想改变或增加connector,你可以通知Pulsar更新信息:
bin/pulsar-admin sinks reload
当OpenMLDB connector成为内建connector时,它的sink类型名为jdbc-openmldb,你可以直接使用这个类型名来指定使用OpenMLDB connector。
③ 创建sink
我们使用public/default这个namespace来创建sink, 我们需要一个sink的配置文件, 它在files/pulsar-openmldb-jdbc-sink.yaml,内容如下:
tenant: "public"
namespace: "default"
name: "openmldb-test-sink"
archive: "files/pulsar-io-jdbc-openmldb-2.11.0-SNAPSHOT.nar"
inputs: ["test_openmldb"]
configs:
jdbcUrl: "jdbc:openmldb:///pulsar_test?zk=localhost:2181&zkPath=/openmldb"
tableName: "connector_test"
其中:
- name:sink名。
- archive:我们使用archive来指定sink connector, 所以这里我们是将OpenMLDB connector当作非内建connector使用。
- input:可以是多个topic的名字,本文只使用一个。
- config:用于连接OpenMLDB集群的jdbc配置。
接下来,创建这个sink并检查。注意,我们设置的输入topic是‘test_openmldb’,后续步骤需要使用到。
./bin/pulsar-admin sinks create --sink-config-file files/pulsar-openmldb-jdbc-sink.yaml
./bin/pulsar-admin sinks status --name openmldb-test-sink
④ 创建 Schema
上传schema到topic test_openmldb,schema类型是JSON格式。后续步骤中,我们将生产一样schema的JSON消息。schema文件是files/openmldb-table-schema,内容如下:
{
"type": "JSON",
"schema":"{\"type\":\"record\",\"name\":\"OpenMLDBSchema\",\"namespace\":\"com.foo\",\"fields\":[{\"name\":\"id\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"vendor_id\",\"type\":\"int\"},{\"name\":\"pickup_datetime\",\"type\":\"long\"},{\"name\":\"dropoff_datetime\",\"type\":\"long\"},{\"name\":\"passenger_count\",\"type\":\"int\"},{\"name\":\"pickup_longitude\",\"type\":\"double\"},{\"name\":\"pickup_latitude\",\"type\":\"double\"},{\"name\":\"dropoff_longitude\",\"type\":\"double\"},{\"name\":\"dropoff_latitude\",\"type\":\"double\"},{\"name\":\"store_and_fwd_flag\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"trip_duration\",\"type\":\"int\"}]}",
"properties": {}
}
上传并检查schema的命令,如下所示:
./bin/pulsar-admin schemas upload test_openmldb -f ./files/openmldb-table-schema
./bin/pulsar-admin schemas get test_openmldb
步骤3 | 测试
① 发送消息
我们使用两条OpenMLDB镜像中data/taxi_tour_table_train_simple.csv的样本数据,作为测试用的消息。数据如下图所示:
测试用Producer关键代码如下:
可以看到,producer将发送两条消息到topic test_openmldb。这之后,Pulsar将读到消息,并将其写入OpenMLDB集群的在线存储中。
程序包在files中,你可以直接运行它:
java -cp files/pulsar-client-java-1.0-SNAPSHOT-jar-with-dependencies.jar org.example.Client
② 检查
我们可以检查Pulsar中的sink状态:
./bin/pulsar-admin sinks status --name openmldb-test-sink
“numReadFromPulsar”: pulsar发送了2条message到sink实例中。
“numWrittenToSink”: sink实例向OpenMLDB写入2条message。
同样,我们可以在OpenMLDB在线存储中查询到这些消息数据。查询脚本select.sql内容如下:
set @@execute_mode='online';
use pulsar_test;
select *, string(timestamp(pickup_datetime)), string(timestamp(dropoff_datetime)) from connector_test;
在OpenMLDB容器中执行脚本:
../openmldb/bin/openmldb --zk_cluster=127.0.0.1:2181 --zk_root_path=/openmldb --role=sql_client < files/select.sq
04 写在最后
1.OpenMLDB上下游生态体系
为更好降低开发者使用OpenMLDB的门槛,OpenMLDB社区将持续打造面向上下游技术组件的生态圈,为开发者提供更多简单易用的生态Connector(如下图所示):
- 面向线上数据生态,如Kafka, Flin, RabbitMQ, RocketMQ等
- 面向离线数据生态,如HDFS, HBase, Cassandra, S3等
- 面向模型构建的算法、框架,例如XGBoost, LightGBM, TensorFlow, PyTorch, Scikit Learn等
- 面向机器学习建模全流程的调度框架、部署工具,例如Airflow,Kubeflow,DolphinScheduler,Prometheus,Grafana等
2. OpenMLDB Roadmap v0.5.0
OpenMLDB社区将于4月底发布v0.5.0版本
(链接:https://github.com/4paradigm/OpenMLDB/issues/1506),届时OpenMLDB将具备新特性如下:
- 窗口预聚合技术,指数级提升长窗口聚合性能
- 完善的监控, trace 和 profiling 能力,在企业级应用环境中大幅提升稳定性、可观测性、和可分析性
- 线上存储引擎可插拔以适配不同业务需求,既可以支持基于内存的高性能存储引擎,也可以支持基于外存的大容量低成本存储引擎,还可以支持基于持久内存的存储引擎以在性能和成本间保持平衡
- 用户自定义函数(UDF)支持,大幅提升易用性和适用性
- 上下游数据源生态整合,提供线上数据源的 Kafka, Pulsar connectors
05 相关阅读
① https://github.com/4paradigm/OpenMLDB/issues/1506
(OpenMLDB Pulsar Connector)
② https://openmldb.ai/docs/zh/v0.4/about/index.html
(OpenMLDB文档)
③ https://pulsar.apache.org/docs/en/next/io-connectors/
(Apache Pulsar connector文档, OpenMLDB Pulsar Connector位置如图所示)
希望这篇文章能够帮助大家认识Pulsar Connector的开发流程,理解OpenMLDB Connector on Pulsar是什么样的,了解Pulsar如何接入OpenMLDB。
最后,AI 的进步需要付出多方面的努力,而开放式协作是其中的关键环节,我们期待来自开发者的交流讨论。欢迎大家加入OpenMLDB社区,通过下图渠道可加入社区技术交流微信群。
今天的分享就到这里,谢谢大家。
03 Connector演示
1. 流程介绍
Pulsar OpenMLDB connector 用于 OpenMLDB 线上模式的实时数据流接入。使用connector的简要流程,如下图所示。我们接下来将详细介绍每一步。
整体上,使用流程可以概括为三步:
- 创建connector前需要启动OpenMLDB集群,并创建表。
- 创建Pulsar standalone,创建sink,sink配置中使用OpenMLDB集群的JDBC地址。并且,创建用于解析消息的schema。
- 向Pulsar发送消息,来测试消息是否能自动写入到OpenMLDB。
2. 关键步骤
注意,为了使演示更简单,本文中将使用Pulsar Standalone,OpenMLDB集群和一个简单JSON消息生产者程序,来演示OpenMLDB JDBC Connector是如何工作的。该connector是完全可以在Pulsar Cluster中正常使用的。
步骤1 | 在 OpenMLDB 创建数据库和数据表
① 启动 OpenMLDB 集群
使用Docker可以快速启动OpenMLDB,除此之外,我们还需要创建测试用的表。
提醒:目前只有OpenMLDB集群版可以作为sink的接收端,数据只会sink到集群的在线存储中。
我们更推荐你使用host network模式运行docker,以及绑定文件目录files,sql脚本在该目录中。
docker run -dit --network host -v `pwd`/files:/work/taxi-trip/files --name openmldb 4pdosc/openmldb:0.4.4 bash
在OpenMLDB容器中,启动集群:
./init.sh
需要注意的是,在macOS平台上,即使使用host网络,也不支持从容器外部去连接容器内的 OpenMLDB 服务器。但从容器内,去连接别的容器内的OpenMLDB服务,是可行的。
② 创建表
我们使用一个脚本快速创建表,脚本内容如下:
create database pulsar_test;
use pulsar_test;
create table connector_test(id string, vendor_id int, pickup_datetime bigint, dropoff_datetime bigint, passenger_count int, pickup_longitude double, pickup_latitude double, dropoff_longitude double, dropoff_latitude double, store_and_fwd_flag string, trip_duration int);
desc connector_test;
执行脚本:
../openmldb/bin/openmldb --zk_cluster=127.0.0.1:2181 --zk_root_path=/openmldb --role=sql_client < files/create.sql
目前,Pulsar中JSONSchema和JDBC base connector都不支java.sql.Timestamp。所以我们使用long作为timestamp列的数据类型(在OpenMLDB可以使用long作为时间戳)。
步骤2 | 启动Pulsar,创建sink和schem
① 启动 Pulsar Standalone
使用docker,可以更简单快速地启动Pulsar。我们推荐你使用host network来运行docker,这样可以避免诸多容器相关的网络连接问题。而且,我们需要使用pulsar-admin来进行sink创建,这个程序在Pulsar镜像内。所以,我们使用bash运行容器,在容器内部逐一执行命令。此处,也需要绑定files文件目录。
docker run -dit --network host -v `pwd`/files:/pulsar/files --name pulsar apachepulsar/pulsar:2.9.1 bash
在Pulsar容器中,启动standalone服务端。
bin/pulsar-daemon start standalone --zookeeper-port 5181
OpenMLDB服务已经使用了端口2181,所以此处我们为Pulsar重新设置一个zk端口。我们将使用端口2181来连接OpenMLDB,但Pulsar standalone内的zk端口不会对外造成影响。
你可以检查一下Pulsar是否正常运行,可以使用ps或者检查日志。
ps axu|grep pulsar
当你启动一个本地standalone集群,会自动创建pulic/default namesapce。这个namespace用于开发,我们将在此namespace中创建sink。
如果你想要在本地直接启动Pulsar,可以参考Set up a standalone Pulsar locally。
链接:https://pulsar.apache.org/docs/en/standalone/
Q&A
Q1: 碰到以下问题是什么原因
2022-04-07T03:15:59,289+0000 [main] INFO org.apache.zookeeper.server.NIOServerCnxnFactory - binding to port 0.0.0.0/0.0.0.0:5181
2022-04-07T03:15:59,289+0000 [main] ERROR org.apache.pulsar.zookeeper.LocalBookkeeperEnsemble - Exception while instantiating ZooKeeper
java.net.BindException: Address already in use
A: Pulsar需要一个未被使用的端口来启动zk,端口5181页已经被使用,需要再更改一下–zookeeper-port的端口号。
Q2: 8080端口已被使用?
A: 8080是webServicePort默认配置端口,在conf/standalone.conf中,可以更换这个端口。但注意,pulsar-admin会使用conf/client.conf中的webServiceUrl进行连接,也需要同步更改。
Q3: 6650端口已被使用?
A: 需要同步更改conf/standalone.conf中的brokerServicePort和conf/client.conf中的brokerServiceUrl配置项。
② Connector安装(Optional)
前面的步骤中我们绑定了files目录,里面已经提供了connector的nar包。我们可以使用“非内建connector”模式来设置connector(即在sink配置中指定archive配置项,将在下一个步骤中描述)。
但如果你希望将OpenMLDB connector作为内建的connector,你需要创建connectors目录,并拷贝nar文件到connectors目录。
mkdir connectors
cp files/pulsar-io-jdbc-openmldb-2.11.0-SNAPSHOT.nar connectors
如果在Pulsar运行时,你想改变或增加connector,你可以通知Pulsar更新信息:
bin/pulsar-admin sinks reload
当OpenMLDB connector成为内建connector时,它的sink类型名为jdbc-openmldb,你可以直接使用这个类型名来指定使用OpenMLDB connector。
③ 创建sink
我们使用public/default这个namespace来创建sink, 我们需要一个sink的配置文件, 它在files/pulsar-openmldb-jdbc-sink.yaml,内容如下:
tenant: "public"
namespace: "default"
name: "openmldb-test-sink"
archive: "files/pulsar-io-jdbc-openmldb-2.11.0-SNAPSHOT.nar"
inputs: ["test_openmldb"]
configs:
jdbcUrl: "jdbc:openmldb:///pulsar_test?zk=localhost:2181&zkPath=/openmldb"
tableName: "connector_test"
其中:
- name:sink名。
- archive:我们使用archive来指定sink connector, 所以这里我们是将OpenMLDB connector当作非内建connector使用。
- input:可以是多个topic的名字,本文只使用一个。
- config:用于连接OpenMLDB集群的jdbc配置。
接下来,创建这个sink并检查。注意,我们设置的输入topic是‘test_openmldb’,后续步骤需要使用到。
./bin/pulsar-admin sinks create --sink-config-file files/pulsar-openmldb-jdbc-sink.yaml
./bin/pulsar-admin sinks status --name openmldb-test-sink
④ 创建 Schema
上传schema到topic test_openmldb,schema类型是JSON格式。后续步骤中,我们将生产一样schema的JSON消息。schema文件是files/openmldb-table-schema,内容如下:
{
"type": "JSON",
"schema":"{\"type\":\"record\",\"name\":\"OpenMLDBSchema\",\"namespace\":\"com.foo\",\"fields\":[{\"name\":\"id\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"vendor_id\",\"type\":\"int\"},{\"name\":\"pickup_datetime\",\"type\":\"long\"},{\"name\":\"dropoff_datetime\",\"type\":\"long\"},{\"name\":\"passenger_count\",\"type\":\"int\"},{\"name\":\"pickup_longitude\",\"type\":\"double\"},{\"name\":\"pickup_latitude\",\"type\":\"double\"},{\"name\":\"dropoff_longitude\",\"type\":\"double\"},{\"name\":\"dropoff_latitude\",\"type\":\"double\"},{\"name\":\"store_and_fwd_flag\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"trip_duration\",\"type\":\"int\"}]}",
"properties": {}
}
上传并检查schema的命令,如下所示:
./bin/pulsar-admin schemas upload test_openmldb -f ./files/openmldb-table-schema
./bin/pulsar-admin schemas get test_openmldb
步骤3 | 测试
① 发送消息
我们使用两条OpenMLDB镜像中data/taxi_tour_table_train_simple.csv的样本数据,作为测试用的消息。数据如下图所示:
测试用Producer关键代码如下:
可以看到,producer将发送两条消息到topic test_openmldb。这之后,Pulsar将读到消息,并将其写入OpenMLDB集群的在线存储中。
程序包在files中,你可以直接运行它:
java -cp files/pulsar-client-java-1.0-SNAPSHOT-jar-with-dependencies.jar org.example.Client
② 检查
我们可以检查Pulsar中的sink状态:
./bin/pulsar-admin sinks status --name openmldb-test-sink
“numReadFromPulsar”: pulsar发送了2条message到sink实例中。
“numWrittenToSink”: sink实例向OpenMLDB写入2条message。
同样,我们可以在OpenMLDB在线存储中查询到这些消息数据。查询脚本select.sql内容如下:
set @@execute_mode='online';
use pulsar_test;
select *, string(timestamp(pickup_datetime)), string(timestamp(dropoff_datetime)) from connector_test;
在OpenMLDB容器中执行脚本:
../openmldb/bin/openmldb --zk_cluster=127.0.0.1:2181 --zk_root_path=/openmldb --role=sql_client < files/select.sq
04 写在最后
1.OpenMLDB上下游生态体系
为更好降低开发者使用OpenMLDB的门槛,OpenMLDB社区将持续打造面向上下游技术组件的生态圈,为开发者提供更多简单易用的生态Connector(如下图所示):
- 面向线上数据生态,如Kafka, Flin, RabbitMQ, RocketMQ等
- 面向离线数据生态,如HDFS, HBase, Cassandra, S3等
- 面向模型构建的算法、框架,例如XGBoost, LightGBM, TensorFlow, PyTorch, Scikit Learn等
- 面向机器学习建模全流程的调度框架、部署工具,例如Airflow,Kubeflow,DolphinScheduler,Prometheus,Grafana等
2. OpenMLDB Roadmap v0.5.0
OpenMLDB社区将于4月底发布v0.5.0版本
(链接:https://github.com/4paradigm/OpenMLDB/issues/1506),届时OpenMLDB将具备新特性如下:
- 窗口预聚合技术,指数级提升长窗口聚合性能
- 完善的监控, trace 和 profiling 能力,在企业级应用环境中大幅提升稳定性、可观测性、和可分析性
- 线上存储引擎可插拔以适配不同业务需求,既可以支持基于内存的高性能存储引擎,也可以支持基于外存的大容量低成本存储引擎,还可以支持基于持久内存的存储引擎以在性能和成本间保持平衡
- 用户自定义函数(UDF)支持,大幅提升易用性和适用性
- 上下游数据源生态整合,提供线上数据源的 Kafka, Pulsar connectors
05 相关阅读
① https://github.com/4paradigm/OpenMLDB/issues/1506
(OpenMLDB Pulsar Connector)
② https://openmldb.ai/docs/zh/v0.4/about/index.html
(OpenMLDB文档)
③ https://pulsar.apache.org/docs/en/next/io-connectors/
(Apache Pulsar connector文档, OpenMLDB Pulsar Connector位置如图所示)
希望这篇文章能够帮助大家认识Pulsar Connector的开发流程,理解OpenMLDB Connector on Pulsar是什么样的,了解Pulsar如何接入OpenMLDB。
最后,AI 的进步需要付出多方面的努力,而开放式协作是其中的关键环节,我们期待来自开发者的交流讨论。欢迎大家加入OpenMLDB社区,通过下图渠道可加入社区技术交流微信群。
今天的分享就到这里,谢谢大家。
docker run -dit --network host -v `pwd`/files:/work/taxi-trip/files --name openmldb 4pdosc/openmldb:0.4.4 bash./init.shcreate database pulsar_test;
use pulsar_test;
create table connector_test(id string, vendor_id int, pickup_datetime bigint, dropoff_datetime bigint, passenger_count int, pickup_longitude double, pickup_latitude double, dropoff_longitude double, dropoff_latitude double, store_and_fwd_flag string, trip_duration int);
desc connector_test;../openmldb/bin/openmldb --zk_cluster=127.0.0.1:2181 --zk_root_path=/openmldb --role=sql_client < files/create.sqldocker run -dit --network host -v `pwd`/files:/pulsar/files --name pulsar apachepulsar/pulsar:2.9.1 bashbin/pulsar-daemon start standalone --zookeeper-port 51812022-04-07T03:15:59,289+0000 [main] INFO org.apache.zookeeper.server.NIOServerCnxnFactory - binding to port 0.0.0.0/0.0.0.0:5181
2022-04-07T03:15:59,289+0000 [main] ERROR org.apache.pulsar.zookeeper.LocalBookkeeperEnsemble - Exception while instantiating ZooKeeper
java.net.BindException: Address already in usemkdir connectors
cp files/pulsar-io-jdbc-openmldb-2.11.0-SNAPSHOT.nar connectorsbin/pulsar-admin sinks reload
tenant: "public"
namespace: "default"
name: "openmldb-test-sink"
archive: "files/pulsar-io-jdbc-openmldb-2.11.0-SNAPSHOT.nar"
inputs: ["test_openmldb"]
configs:
jdbcUrl: "jdbc:openmldb:///pulsar_test?zk=localhost:2181&zkPath=/openmldb"
tableName: "connector_test"- name:sink名。
- archive:我们使用archive来指定sink connector, 所以这里我们是将OpenMLDB connector当作非内建connector使用。
- input:可以是多个topic的名字,本文只使用一个。
- config:用于连接OpenMLDB集群的jdbc配置。
./bin/pulsar-admin sinks create --sink-config-file files/pulsar-openmldb-jdbc-sink.yaml
./bin/pulsar-admin sinks status --name openmldb-test-sink
{
"type": "JSON",
"schema":"{\"type\":\"record\",\"name\":\"OpenMLDBSchema\",\"namespace\":\"com.foo\",\"fields\":[{\"name\":\"id\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"vendor_id\",\"type\":\"int\"},{\"name\":\"pickup_datetime\",\"type\":\"long\"},{\"name\":\"dropoff_datetime\",\"type\":\"long\"},{\"name\":\"passenger_count\",\"type\":\"int\"},{\"name\":\"pickup_longitude\",\"type\":\"double\"},{\"name\":\"pickup_latitude\",\"type\":\"double\"},{\"name\":\"dropoff_longitude\",\"type\":\"double\"},{\"name\":\"dropoff_latitude\",\"type\":\"double\"},{\"name\":\"store_and_fwd_flag\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"trip_duration\",\"type\":\"int\"}]}",
"properties": {}
}
./bin/pulsar-admin schemas upload test_openmldb -f ./files/openmldb-table-schema
./bin/pulsar-admin schemas get test_openmldbjava -cp files/pulsar-client-java-1.0-SNAPSHOT-jar-with-dependencies.jar org.example.Client./bin/pulsar-admin sinks status --name openmldb-test-sinkset @@execute_mode='online';
use pulsar_test;
select *, string(timestamp(pickup_datetime)), string(timestamp(dropoff_datetime)) from connector_test;../openmldb/bin/openmldb --zk_cluster=127.0.0.1:2181 --zk_root_path=/openmldb --role=sql_client < files/select.sq04 写在最后
1.OpenMLDB上下游生态体系
为更好降低开发者使用OpenMLDB的门槛,OpenMLDB社区将持续打造面向上下游技术组件的生态圈,为开发者提供更多简单易用的生态Connector(如下图所示):
- 面向线上数据生态,如Kafka, Flin, RabbitMQ, RocketMQ等
- 面向离线数据生态,如HDFS, HBase, Cassandra, S3等
- 面向模型构建的算法、框架,例如XGBoost, LightGBM, TensorFlow, PyTorch, Scikit Learn等
- 面向机器学习建模全流程的调度框架、部署工具,例如Airflow,Kubeflow,DolphinScheduler,Prometheus,Grafana等
2. OpenMLDB Roadmap v0.5.0
OpenMLDB社区将于4月底发布v0.5.0版本
(链接:https://github.com/4paradigm/OpenMLDB/issues/1506),届时OpenMLDB将具备新特性如下:
- 窗口预聚合技术,指数级提升长窗口聚合性能
- 完善的监控, trace 和 profiling 能力,在企业级应用环境中大幅提升稳定性、可观测性、和可分析性
- 线上存储引擎可插拔以适配不同业务需求,既可以支持基于内存的高性能存储引擎,也可以支持基于外存的大容量低成本存储引擎,还可以支持基于持久内存的存储引擎以在性能和成本间保持平衡
- 用户自定义函数(UDF)支持,大幅提升易用性和适用性
- 上下游数据源生态整合,提供线上数据源的 Kafka, Pulsar connectors
05 相关阅读
① https://github.com/4paradigm/OpenMLDB/issues/1506
(OpenMLDB Pulsar Connector)
② https://openmldb.ai/docs/zh/v0.4/about/index.html
(OpenMLDB文档)
③ https://pulsar.apache.org/docs/en/next/io-connectors/
(Apache Pulsar connector文档, OpenMLDB Pulsar Connector位置如图所示)
希望这篇文章能够帮助大家认识Pulsar Connector的开发流程,理解OpenMLDB Connector on Pulsar是什么样的,了解Pulsar如何接入OpenMLDB。
最后,AI 的进步需要付出多方面的努力,而开放式协作是其中的关键环节,我们期待来自开发者的交流讨论。欢迎大家加入OpenMLDB社区,通过下图渠道可加入社区技术交流微信群。
今天的分享就到这里,谢谢大家。
- 窗口预聚合技术,指数级提升长窗口聚合性能
- 完善的监控, trace 和 profiling 能力,在企业级应用环境中大幅提升稳定性、可观测性、和可分析性
- 线上存储引擎可插拔以适配不同业务需求,既可以支持基于内存的高性能存储引擎,也可以支持基于外存的大容量低成本存储引擎,还可以支持基于持久内存的存储引擎以在性能和成本间保持平衡
- 用户自定义函数(UDF)支持,大幅提升易用性和适用性
- 上下游数据源生态整合,提供线上数据源的 Kafka, Pulsar connectors
05 相关阅读
① https://github.com/4paradigm/OpenMLDB/issues/1506 (OpenMLDB Pulsar Connector) ② https://openmldb.ai/docs/zh/v0.4/about/index.html (OpenMLDB文档) ③ https://pulsar.apache.org/docs/en/next/io-connectors/ (Apache Pulsar connector文档, OpenMLDB Pulsar Connector位置如图所示)
希望这篇文章能够帮助大家认识Pulsar Connector的开发流程,理解OpenMLDB Connector on Pulsar是什么样的,了解Pulsar如何接入OpenMLDB。
最后,AI 的进步需要付出多方面的努力,而开放式协作是其中的关键环节,我们期待来自开发者的交流讨论。欢迎大家加入OpenMLDB社区,通过下图渠道可加入社区技术交流微信群。
今天的分享就到这里,谢谢大家。







