

本文整理自 37 手游技术主管彭佳铭和高级算法工程师左伟健在 OpenMLDB Meetup No.6 中的分享 ——《OpenMLDB 在 37 手游特征计算场景中的应用》。
37 手游介绍
37 手游成立于 2013 年,是上市公司三七互娱旗下的独立子公司,专注于移动游戏的运营,致力于手游游戏发行业务。在中国大陆地区,37 手游以 10% 的市场占有率,位居行业前 3,仅次于腾讯和网易。在非中国大陆地区,37 手游也成功进入了 “月入过亿” 俱乐部。

迄今为止,我们成功发行过很多优秀的作品,包括《永恒纪元》、《一刀传世》、《云上城之歌》(在韩国颇受关注和好评)、《谜题大陆》、《斗罗大陆:魂师对决》等等。也邀请到了很多颇具影响力的形象代言人,成龙、李连杰、黎明、王宝强、金馆长等均是/曾是 37 手游旗下的作品的形象代言人。

目前,37 手游累计为超过四亿游戏玩家提供过服务,用户量和数据量比较庞大。 我们着重强化自身的游戏运营能力、市场推广能力和广告设计能力,并结合这三种核心能力提出了立体化、AI 智能化营销的 “流量经营” 策略。
37 手游算法应用场景
基于这一打法策略,37 手游的算法团队主要服务于公司 “智能风控”、“智能投放”、“智能运营” 三大智能业务模块。

第一模块的智能风控是我们公司业务的护城河。目前,37 手游围绕算法团队内部构建的审判系统 ——“神探”,构建了一个立体风控体系。主要解决游戏发行厂商常见的风控问题,比如说防拉人或者刷号(资源号、初始号)的黑产对抗。
第二模块是智能投放。作为一家头部的游戏公司,在投放领域也投入了较大的时间精力人力去构建算法的相关应用。最近几年,不仅是抖音、快手这类视频产品的广告平台在尝试构建自动化智能化的投放策略,头部的游戏公司也在着手构建自己的智能投放平台。这一块也是我们正在尝试构建的一个核心竞争力,目前 37 手游已经基于内部的 “量子” 搭建了一站式智能投放系统。
第三模块即智能运营模块,主要服务于智能化营销以及智能化客服。接下来将会以此模块为例,为大家做一个详细的应用场景介绍。
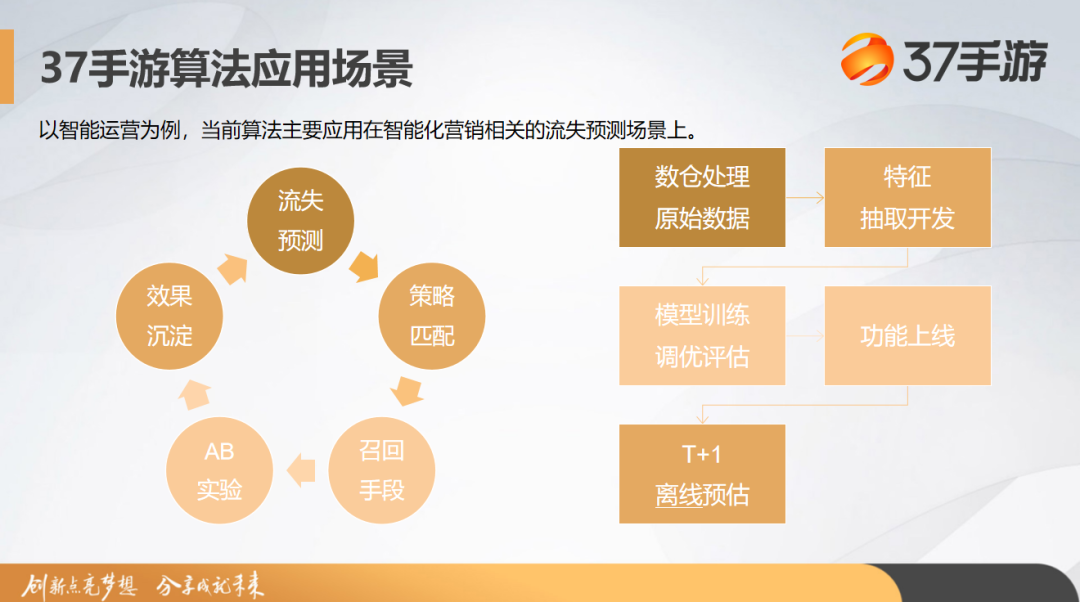
当前算法主要是应用在智能化营销相关的流失预测场景上。
其实大家也有了解,互联网公司已经不再处于用户快速增长的一个红利期,用户增长成本也在逐渐提高。那对于产品来说,如果能服务好存量用户并避免或减少用户流失的话,实际上的收益将远远超过开发同等量级新用户。所以流失用户的召回成为了后续产品发展的一个关键。
过去的经验也告诉我们,留住用户最好的时机是在用户即将流失前。
如何在及时的时间点预估用户的一个流失倾向,是我们需要解决的一个关键业务问题。
37 手游最开始的方案是一个 T+1 数据的一个离线预估处理,但这意味着我们召回时机的错失。所以当时我们提出要做在时间线上更提前的节点做出拦截召回,完成更及时的流失预警。同时我们以此做到根据用户的行为特征或属性特征去有效识别流失风险,智能配置多元化的召回策略,再通过一些实验提出一些比较好的召回方案,最终达到留住用户的目的。这个时候就需要我们在技术层面上做到更快的预估,所以我们开始了技术调研。
下面展示的是流失预测场景的流程图。一开始的话,我们是按照左图以 T+1 维度进行的一个预估。后续我们按照右图,提出了一个演化后的流程。
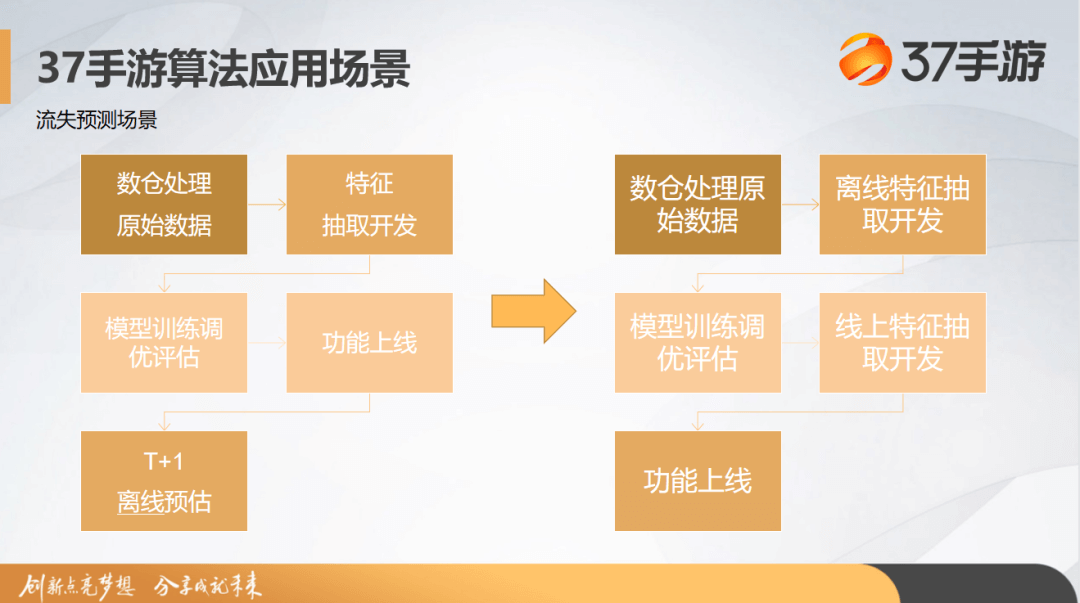
在日志数据进入后,我们会做一个原始的处理,接着进行离线特征的抽取。 抽取完之后,我们会开始着手进行一个模型的预估和训练并且调优,最终评估模型的效果能否满足上线需求。 在达到上限效果的时候,我们会给开发团队提出线上特征的开发需求。 最终通过和后端的结合,完成功能的上线。 在实际推进的过程中,我们会面临很多问题,比如 PPT 中提到的线上线下不一致带来的一些问题。在开发过程中,离线算法团队会编写离线特征,开发团队会帮助完成线上特征,这时候就带来了一个口径对齐的问题。在开发完成之后,我们还有一个比较漫长的对数过程。最后,在开发周期上也导致了困扰。
OpenMLDB 引入历程

刚才提到我们做了一些技术方案上的调研,了解了 feature store 的相关技术。因为我们和阿里有合作关系,所以也了解到了阿里的一些闭源解决方案。但是因为阿里的项目还处于内部阶段,并且也不是特别贴合我们的业务,所以我们决定另寻其他方案。
今年五月份的时候,我们接触到了 OpenMLDB,加入了微信社群,联系到社区运营负责人,通过一些案例讲解和技术分享了解到了这样一个组件的存在。在 5 月 26 日约了线上会议,做了深入的了解之后,发现 OpenMLDB 正好是切中我们的业务痛点。当时我们是提了很多问题的,包括:
- OpenMLDB 的特性是什么?
- OpenMLDB 和其他特征仓库的对比表现如何?
- OpenMLDB 在特征方面能不能做到共享跟复用?
- OpenMLDB 有没有运维的难点,要如何解决?
- OpenMLDB 怎么去保证大量数据的流转?
- 如果真正上线后出现数据错误,怎么去做处理?
在那天的会议中,我们还聊到了一些成本相关的话题,以及后续使用能不能给到一些技术支持。并且在会后我们也建立了一个交流群,并且有开始有计划地去进行一些部署跟测试。
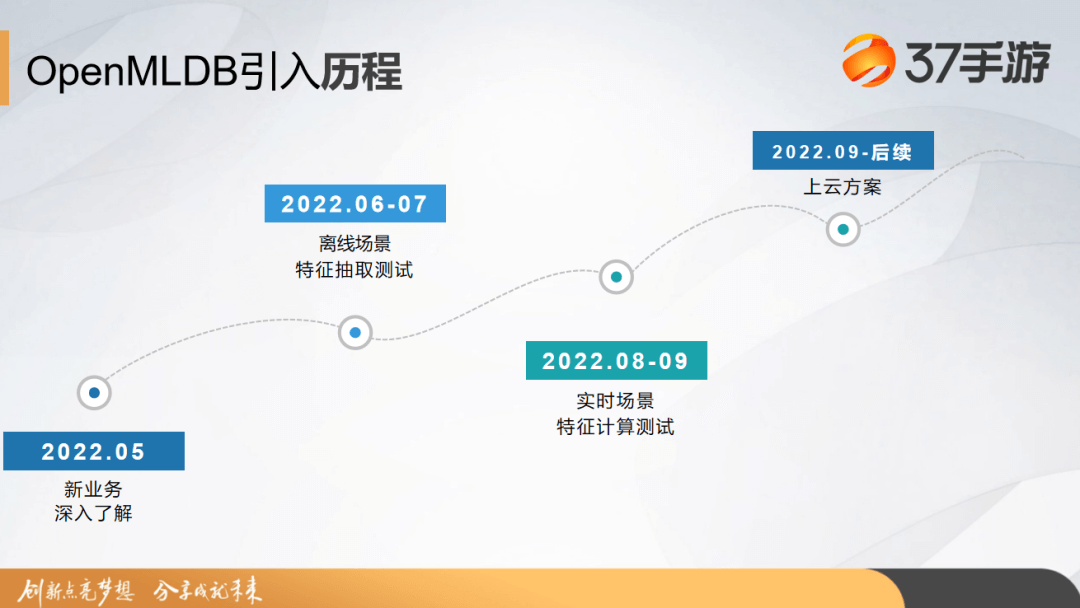
于是在六七月份,37 手游使用 OpenMLDB 进行了离线特征场景的特征抽取测试,并且在八九月份我们尝试在线上场景做一些特征计算测试。
在未来的话,我们和 OpenMLDB 团队讨论后规划了后续的议程,有在着手一些上云的方案,并希望在这一块比较深入的合作。
这就是我们的业务背景以及逐渐引入 OpenMLDB 的过程,接下来会由伟健去讲解我们在接触和引入 OpenMLDB 期间做的相对完整的测试以及得到的一些结论。
业务场景介绍

左伟健:
在接下来的分享中我会先简单介绍一下我们的业务场景和整体的部署流程。在讲解在引入过程中我们遇到的问题和对应的解决方案。第三部分,我会展示在整个业务落地过程中实践得出来的结论,包括我们所期望的功能是否被 OpenMLDB 满足。最后,我会在未来展望部分讨论如果 OpenMLDB 要在公司业务场景中大规模落地还需要做哪些准备工作?还有哪些功能点是希望得到满足的?

刚才佳铭也有提到,采用了用户流失这样的业务场景去做试用,主要是想借助 OpenMLDB 更快更实时对用户的流失意向形成预估。预估完成之后,根据业务配置的策略将用户召回,比如说提供礼包、设置活动将玩家重新拉回到游戏里面。
简单来说,我们想要在用户触发登录时候,计算出用户的当时的特征,进而预测用户是否会在最近七天中流失。因为整体业务的用户量级达到了百万级,所以数据量也比较庞大,这是我们引入 OpenMLDB 的业务背景。

整体部署与问题解决
接下来我会介绍整体部署流程和问题解决,主要分为组件部署、特征设计、数据导入和问题解决四部分。

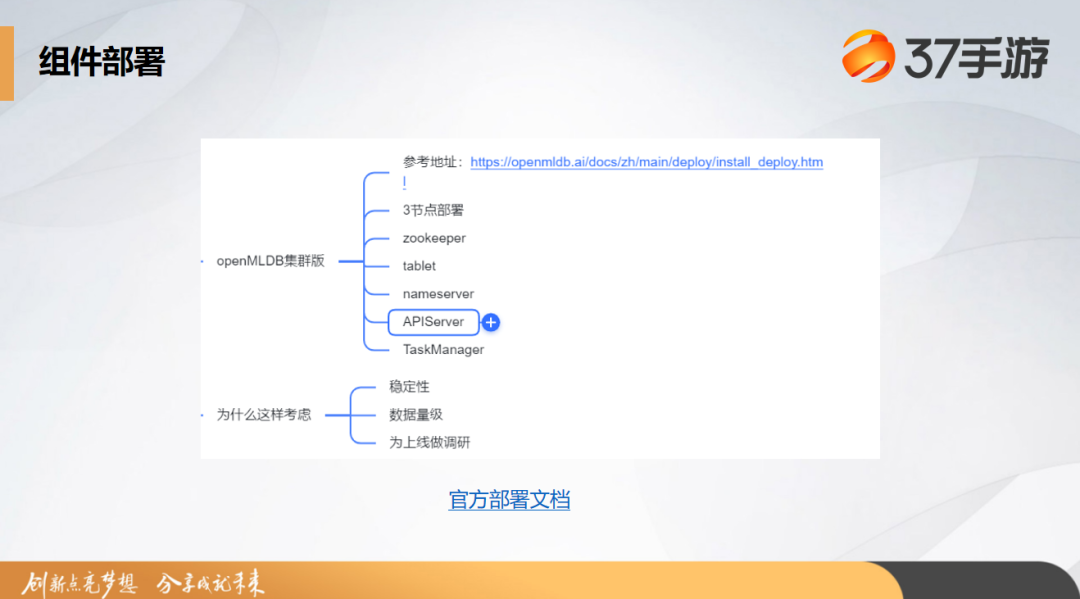
组件部署方面,考虑到数据量级和稳定性的要求,担心单机版不能满足需要,我们部署了 OpenMLDB 的一个集群版。同时,部署集群版也能为我们其他业务大规模实践提前做调研。整体上也部署了 zookeeper、tablet、nameserver、APIServer 和 TaskManager 这些必要组件。
在 SQL 和数据表方面,我们主要用到三张表,一张是登录表,一张是支付表,最后一张是行为表。
然后下图中列举了三张表格的必要字段,像登陆表的登录 ID、游戏 ID、用户 ID、登录的时间;支付表的用户 ID、支付时间、支付金额、支付物品等;行为表中则是对应的行为数据。这里列了一个简略版的结构。

特征设计方面,下图展示一个简化版的特征。其中包括,三天、七天、十五天、三十天的登录次数、行为次数、支付次数和支付金额。这一部分不做详解,因为我们想把重点放到接下来的部署流程。

在登录次数方面,实际上它是一个主表的窗口特征,这是参考官网的 SQL 设计文档编辑的特征。支付次数,支付金额的也是类似的特征,但它们实际上归属一个不同的类别,是副表的聚合特征。行为次数也是副表的一个聚合特征,所以实际上它们 SQL 的结构上面实际上差不多的。以上就是我们在特征方面的设计。

特征设计完成之后,我们去对这个数据进行导入。
我们在离线和在线部分采用了不同的一个方案,离线方面我们通过 HDFS 的文件导入,主要是因为我们离线部分使用了大数据的组件,然后离线的一些日志主要存储在 HDFS 上面,所以采用了 HDFS 文件直接导入的方案。
在线方面,我们没有采用 SDK 导入的方式,而是采用了 Kafka Connector 这一个方案,因为我们实际业务的在线部分已经有实时数据流已经导入到 Kafka 中了,就可以直接用 Kafka Connector 对现有的一个数据流进行消费,导入到在线的表里面。

在这个过程中我们可能主要遇到了三个问题。
第一个问题是,我们要在建表时注意索引的建立。这样有利于我们后续多个场景对表格进行复用,而不需要在业务上线后,再去修改索引。因为像之前提到的副表聚合等,实际上会走一个索引键,一个是组件,像 UID 和时间键 TTL 需要去走。我们在一开始的时候,没有覆盖到索引,然后发现我们需要反复修改索引,导致组建任务的加重。任务加重,进而容易带来我们的组件重启、下线等等。
第二个问题存在于在线数据流格式方面。实际上原版的 Kafka Connector 的数据格式和我们线上的 Kafka 数据流格式不同,这导致了我们不能直接使用原来的 Kafka connector 把数据拉到我们的在线环境里。这里我们专门请教了 OpenMLDB 的开发团队,最终 OpenMLDB 研发同学协助我们开发了一个比较通用的格式。
第三个需要关注的是组件运行状态。比如说我们的组件是否重启,然后节点的存活状态等等。为什么特意提到这个问题呢?其实是我们在试用的过程中建立索引、修改索引的时候呢,就会经常会导致那个组件进入重启或者审核状态。我们会发现因为当整体组件的运行状态不对的时候,服务的稳定性是不够的。有时候会出现请求响应较慢或请求数据和导入数据不一致,但实际上是受我们组件运行状态导致的问题。所以这一块也是比较需要关注。如果后续大规模上线使用 OpenMLDB,在监控方面我们也一定会去做这方面的安排。

实验结论
整体实验的结论是:OpenMLDB 可以满足我们对功能点的期待和业务场景的需求。
在离线导出方面,接口开发完后,我们就可以说对特征展开比较快速的导出和计算了。还有就是因为 OpenMLDB 天然保障线上线下一致性,像 TTS 的时间设计等我们无需担心数据泄露方面的问题。
在线上服务方面,我们发现 OpenMLDB 能帮我们去减少比较多的新特征上线工作量,缩短上线周期,在业务上有比较大的提升。现在我们可以从原来的 15 / 人 / 日降到 1.5 / 人 / 日左右的工作量,能够比较快地将线上业务或模型进行迭代。

未来展望
如果后续还要去推动 OpenMLDB 大规模落地,我们还需要对两部分工作做进一步的展开。
其中一个就是监控。
组件服务的状态会导致我们整体服务质量或者说数据计算的一些小问题,所以我们需要去对组件状态进行监控,然后再监控上层服务整体状态。再者是数据一致性还需要做比对,保证我们提供给线上服务的特征所计算出来的数据不存在偏差。
另一个值得关注的问题是落地成本预估。
成本预估方面,我们也请教了 OpenMLDB 的技术团队,主要思考了两个方面,第一是线上方面,需要衡量 TTL 时间范围内的存储数据量,因为这关系到内存方面的资源要求。第二是在离线方面需要考虑离线存储所需要的存储空间,如果是云的话,可以忽略不计。还要注意的是我们抽取离线特征需要用到的计算资源,这也会关乎到落地成本。

期待
在实践的过程中,我们发现 OpenMLDB 特征管理这一块的功能比较少。我们希望 OpenMLDB 未来能开发特征元信息管理功能。比如说可以帮助我们对整体特征进行一些梳理等等,方便我们快速地复用先前构造特征的经验以及快速开展其他的一个业务。
还有一个期待更靠近性能上的优化升级。现版本的 OpenMLDB 在线上特征计算时是对每一个部署的 SQL 分开计算当时的特征值,我们认为这里可以使用的计算资源可以进一步优化。第二点是离线计算依赖的主要是特征计算始末时间,从理论上来说,也是可以对离线特征也进行计算复用的。

总体而言,OpenMLDB 对我们业务需求的功能覆盖还是很不错的。








