

Continuing our discussion Here, OpenMLDB provides a millisecond-level real-time feature computation platform within the end-to-end machine learning process, ensuring consistency between offline development and online deployment. In this article, we will revisit the key features of OpenMLDB, introducing some existing business use cases as examples, and how to integrate OpenMLDB into your existing system.
OpenMLDB for Hard Real Time
One of OpenMLDB's key features is the ability to do millisecond-level real-time feature computation. This is because we identify that only millisecond-level hard real-time computation can truly meet the needs of AI and maximize real-time decision-making business effects.
Real-time computation mainly has two dimensions. On the one hand, we need to use the freshest real-time data, such as the pattern of clicks in the past minute or a few minutes. On the other hand, real-time computation requires very short response times. Today, we see that in the market, there are indeed many computing frameworks for batch processing and stream processing, but they do not truly meet the hard real-time millisecond-level demands of AI. Most stream processing is designed for big data and business intelligence. In contrast, millisecond-level demands are very common, and urgently needed in applications such as AI-driven autonomous vehicles, anti-fraud scenarios, and many more. For instance, a bank's real-time anti-fraud scenario might require extremely high-speed real-time feature computation within twenty milliseconds to meet business needs. The hard real-time scenario holds significant commercial value, yet there are few universally applicable commercial products available for it.
Let's revisit the architecture of OpenMLDB to see how OpenMLDB can achieve millisecond-level real-time feature computation, as well as provide inherent consistency.
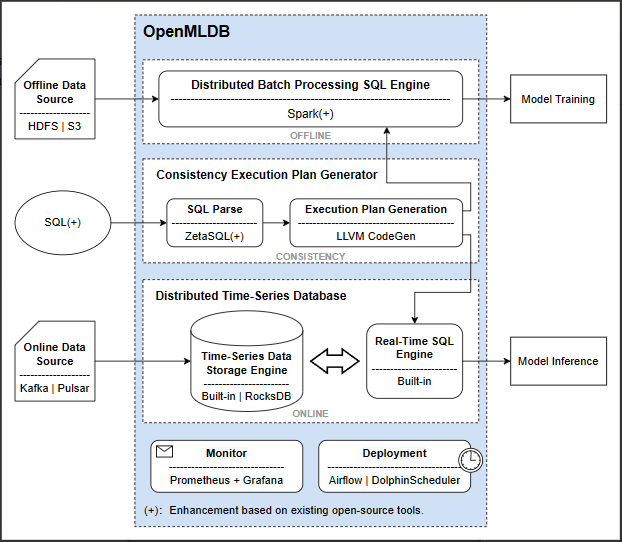
Internally, OpenMLDB consists of two processing engines.
-
One engine is dedicated to batch processing, optimized at the source code level based on Spark, specifically tailored to enhance performance for feature computation scenarios.
-
The second engine is the real-time SQL engine, a self-developed time-series database by the OpenMLDB team, serving as the core engine ensuring millisecond-level real-time feature computation within OpenMLDB.
-
Between these two offline and online engines, there exists a consistent execution plan generator, ensuring the generated execution plans are consistent, naturally guaranteeing consistency between online and offline operations.
With this architecture, data scientists use the batch-processing SQL engine to write batch feature computation scripts for offline development. After development, these scripts can be directly deployed with a single command. At this point, the computing mode of the entire OpenMLDB switches from offline to online. By integrating real-time data, it can be deployed to production straightaway. Within the entire process, data scientists only need to write SQL scripts. They can easily deploy services with a single command, eliminating the need for engineering teams for optimization or manual logic validation. This approach saves a significant amount of AI implementation costs.
OpenMLDB Business Use-Cases
We introduce some of the existing adopters of OpenMLDB in different business scenarios, and hopefully, you can be inspired and see OpenMLDB's potential in your existing systems.
Akulaku - FinTech
Firstly, let's discuss our initial community user - Akulaku, a leading online financial technology company targeting the Indonesian market.
Akulaku has built an intelligent computing platform within its overall architecture. At the top layer of this intelligent computing platform are smart applications, primarily associated with risk control and anti-fraud measures. Below are the two underlying layers of Akulaku's technology architecture. The online engine of OpenMLDB is deployed at the model computing layer, while the offline engine is deployed at the feature computing layer, providing feature computation capabilities.

Akulaku's requirements align closely with the features of OpenMLDB. They require low-latency, high-time-sensitive calculations online to reflect real-time changes in data. Hence, they need OpenMLDB to perform real-time calculations using real-time data. Offline, they aim for high-throughput data analysis. Crucially, they need to ensure complete consistency between online and offline deployments. This aligns with OpenMLDB's provision of online-offline consistency. Therefore, Akulaku ultimately opted for OpenMLDB's solution, utilizing SQL as a bridge between offline and online computations. This allowed them to handle nearly 1 billion order data within a day, ensuring timely updates, and performing real-time sliding window calculations within a 4-millisecond delay.
VIPShop - Personalized Recommendation
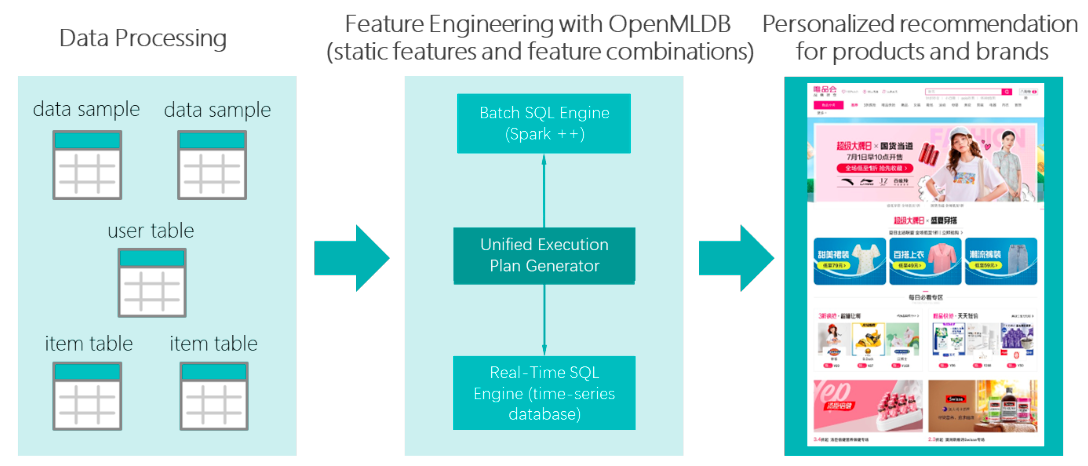
Another prominent community user is VIPShop for the use case of personalized recommendations. VIPShop is China's top e-commerce platform. Vipshop has utilized OpenMLDB in its overseas business for personalized product and brand recommendations, achieving recommendation delays within 10 milliseconds. In addition, the ease of use of OpenMLDB also results in a 60% increase in feature development speed.
VMALL - Personalized Recommendation
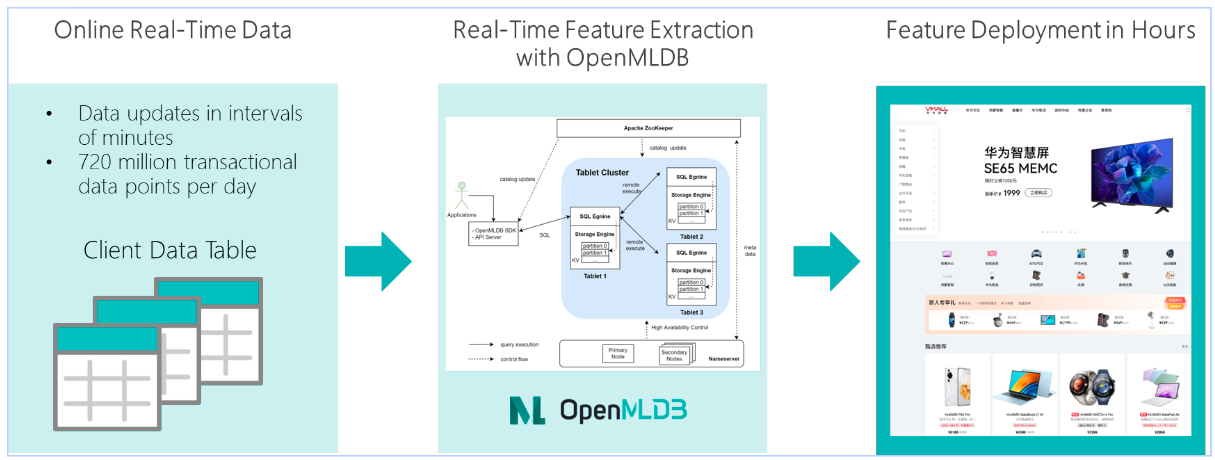
VMALL is the official e-commerce platform under Huawei Company, providing a full range of smart lifestyle products and services including smartphones, laptops, tablets, wearables, and smart home devices. VMALL adopts OpenMLDB in their real-time feature extraction pipeline, and achieved feature deployment in hours.
Telecommunication Operator - Integrated Customer Service with Marketing through Hotline
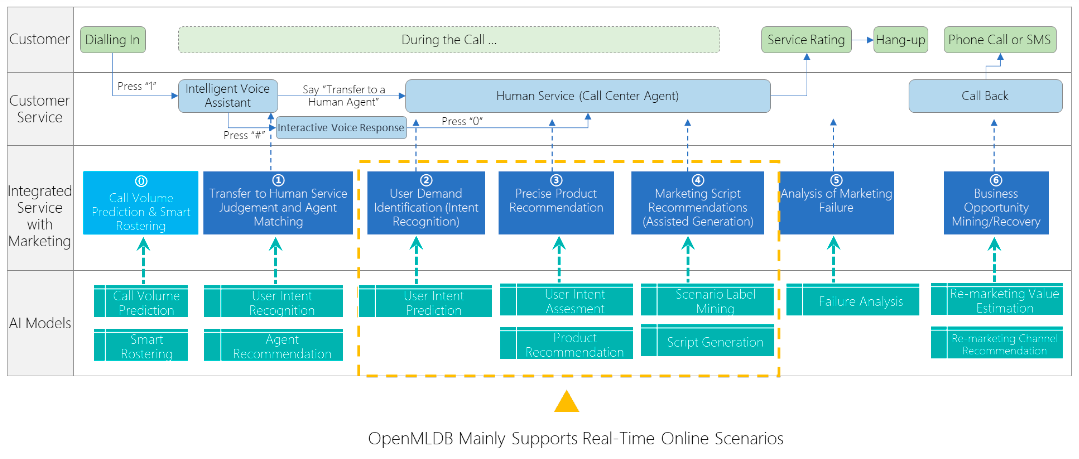
In an application within a major telecommunications operator in China, the primary scenario integrates intelligent customer service with marketing. The diagram below outlines the entire process of the user's online hotline channel. This process encompasses intelligent voice assistant and Interactive voice responses upon user hotline calls, real-time user intent identification and recognition, product recommendations, generation of marketing scripts, and ultimately service analysis and re-marketing evaluation. In this process, OpenMLDB is utilized to support key real-time online scenarios, including user demand identification and assessment, product recommendations, scenario label mining, as well as marketing script generation. OpenMLDB provides offline feature storage, real-time data storage, and SQL-based online feature processing, and offers millisecond-level latency while supporting consistency between online and offline calculations. This significantly enhances the marketing efficiency of the telecommunications operator.
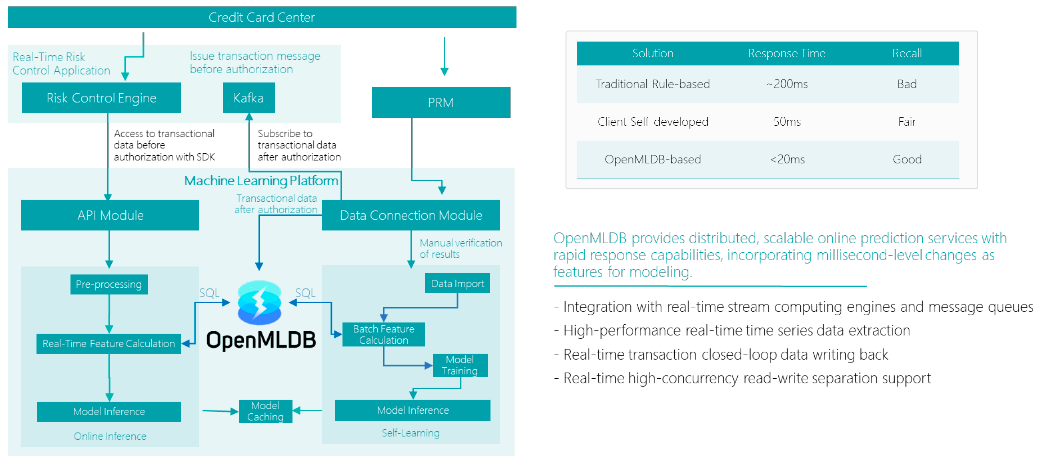
Bank - Real-Time Anti-Fraud
In the real-time anti-fraud scenario, the bank has extremely high-performance requirements for the feature computation module. To counter the numerous fraud methods prevalent today, they need to generate efficient real-time responses swiftly. The bank demands to complete the feature computation process within 20 milliseconds. However, both the traditional rule-based systems and the customer's self-developed systems failed to meet these stringent requirements.
Ultimately, they adopted OpenMLDB's solution, leveraging its distributed and scalable capabilities to achieve real-time feature computation in less than 20 milliseconds. In particular, OpenMLDB integrates real-time feature computation and batch feature computation within the risk control system architecture, connecting the online modules with the self-learning modules to ensure consistency between online and offline components.
OpenMLDB Integration
OpenMLDB Ecosystem
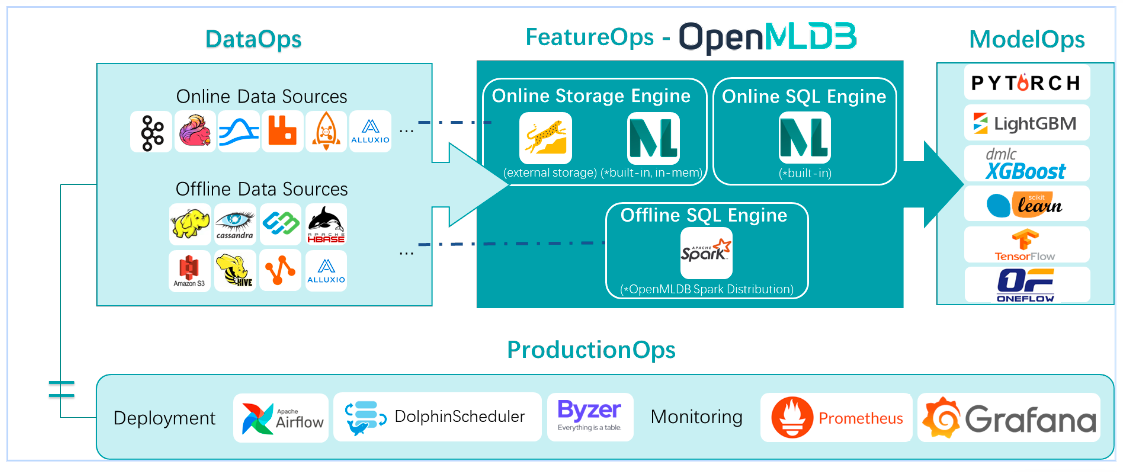
OpenMLDB has been integrated with various upstream and downstream ecosystems. The internal offline engine of OpenMLDB is based on Spark. Regarding online engines, we offer two modes: one is an in-memory engine that provides millisecond-level computation, and the other is a mode aimed at cost-sensitive users, utilizing a third-party storage engine based on RockDB, which helps reduce costs.
For upstream integration, OpenMLDB has connected with many online data sources like Kafka and Pulsar, making it more convenient to record real-time data. Currently, the offline data sources mainly involve HDFS and S3, with further expansions planned for the future.
For downstream integration, regarding models, there's currently a loosely coupled integration method mainly involving the output of standard file formats, enabling them to be read by subsequent ModelOps software.
In the deployment and monitoring aspects, OpenMLDB has integrated with various third-party software. For deployment, integrations have been established with Airflow, Dolphinscheduler, and Byzer. As for monitoring, it is based on Prometheus and Grafana.
Common Ways to Use OpenMLDB
OpenMLDB as a full-stack featureOps tool, provides the functionality for end-to-end feature engineering. However, we understand that any adaptation requires significant effort. Here we recommend several ways that you can start transitioning into OpenMLDB:
- As an offline development tool. OpenMLDB offers a distributed batch engine that can process SQL at very good performance. Data scientists can therefore use this engine for feature script development.
- As a real-time online engine. As OpenMLDB offers a unified execution plan generator, the feature scripts developed by data scientists in SQL can therefore be deployed online to provide real-time performance as well as fulfill operational requirements, saving the cost for engineering transformation and consistency checks. Note that your SQL might need certain modifications to be processed by OpenMLDB.
- Full adoption. Use OpenMLDB at its full scale from development to deployment to enjoy the full benefit. In any way, you can reach out to the community for discussions or seeking help.
In the next blog, we will discuss in more technical detail about the integration methods of OpenMLDB in real-time decision-making systems. Stay tuned!
For more information on OpenMLDB:
- Official website: https://openmldb.ai/
- GitHub: https://github.com/4paradigm/OpenMLDB
- Documentation: https://openmldb.ai/docs/en/
- Join us on Slack !




