

Application of OpenMLDB in AKULAKU Real-Time Feature Calculation Scene
Yuxiang Ma, AKULAKU Algorithm Director
This presentation mainly focuses on the following four points:
- AKULAKU Introduction
- Get To Know OpenMLDB
- Business Scenario Applications
- Evolution Suggestions
【01 | AKULAKU Introduction】
About Akulaku
Founded in 2016, Akulaku is a financial technology company focusing on the Southeast Asian market. The remarkable feature of fintech companies is that all businesses are directly related to money.

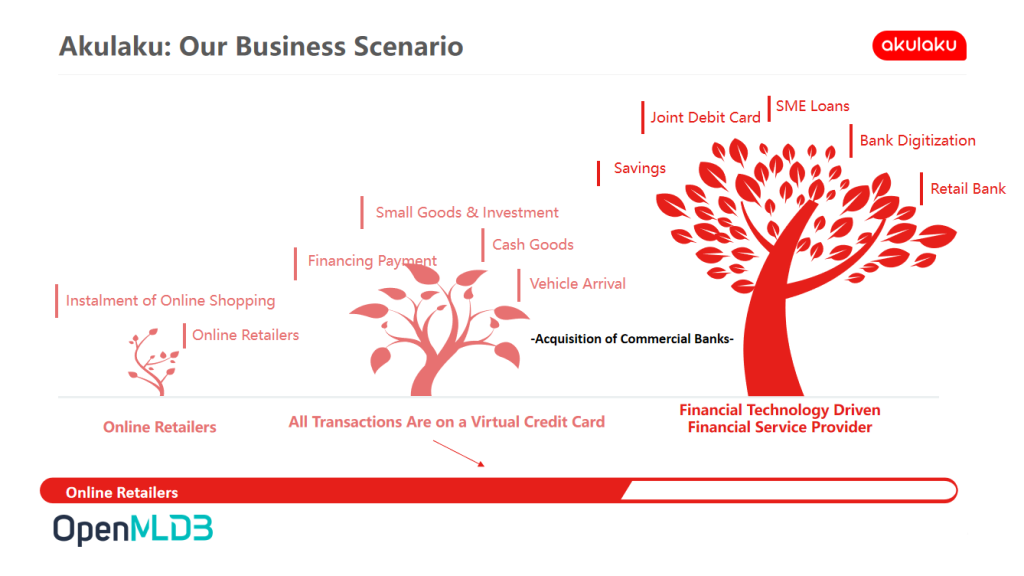
Akulaku's Business Scenario
From the perspective of business scenario, the team first started from a scenario similar to Ant Credit Pay(花呗). With the gradual growth of the business, the team began to get involved in the virtual credit card business. At present, Akulaku has commercial bank and financial investment business, and all businesses involve huge transaction volume.
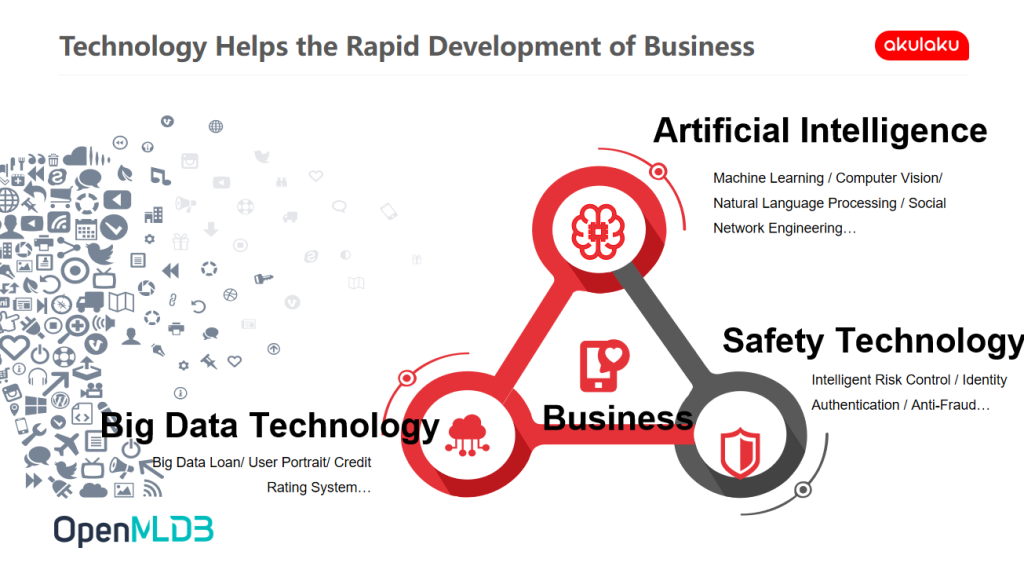
Technology Helps the Rapid Development of Business
The growing number of users and transactions has brought great pressure to the risk control system. The team first needs to ensure the high-level state of the company's risk control, which mainly depends on artificial intelligence technologies such as machine learning, CV, NLP and Graph. At the same time, it uses the huge amount of data collected to promote business development.
The above is a general introduction of Akulaku's business scenario. If you are a peer in the industry, you should already understand why Akulaku started OpenMLDB very quickly.
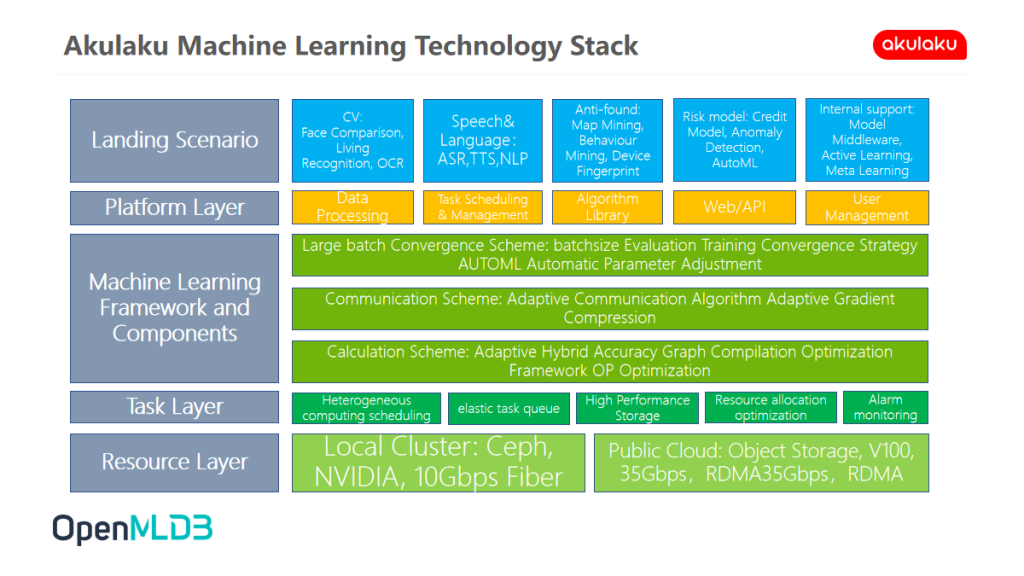
Akulaku Machine Learning Technology Stack
The following figure shows the current technology stack of Akulaku. At present, each layer of the technology stack is planned independently.
- Scenario Layer: It involves various algorithms such as CV, NLP, Speech, Graph Mining and AutoML, which are used to solve the problems faced by many business scenarios. At the same time, various models are developed to fill various possible risks and vulnerabilities.
- Platform Layer: In all links, data processing accounts for more than 80% of resources and time-consumption. The service layer and algorithm library basically adopt the mainstream solutions in the industry.
【02 | First Acquaintance to OpenMLDB】
Akulaku's Experience of Getting to Know OpenMLDB
The first time I get in contact with OpenMLDB was in April 2021. At that time, I was exploring the optimization of Spark and learned about the Spark distribution of the predecessor of OpenMLDB offline computing. In June, I attended the technology conference of the 4Paradigm and learned about OpenMLDB. That’s when I found that it hit a business pain point of Akulaku. Based on this pain point, I began to study the source code of OpenMLDB. We have tried Alibaba's closed source flow batch integrated real-time data warehouse solution in the past, but because it is closed source and mainly serves Alibaba's internal business, its features do not fit the business needs very well, but they cannot be changed. I was very curious about an open-source integrated solution for the first time, so I tested it in a specific scenario based on OpenMLDB. In August, I saw the performance optimization paper published by OpenMLDB in the VLDB 2021. In September, OpenMLDB was used to solve specific business problems. In December, on a relatively new scene, based on OpenMLDB, the offline feature was developed into an online real-time environment, and OpenMLDB was applied to the production environment.

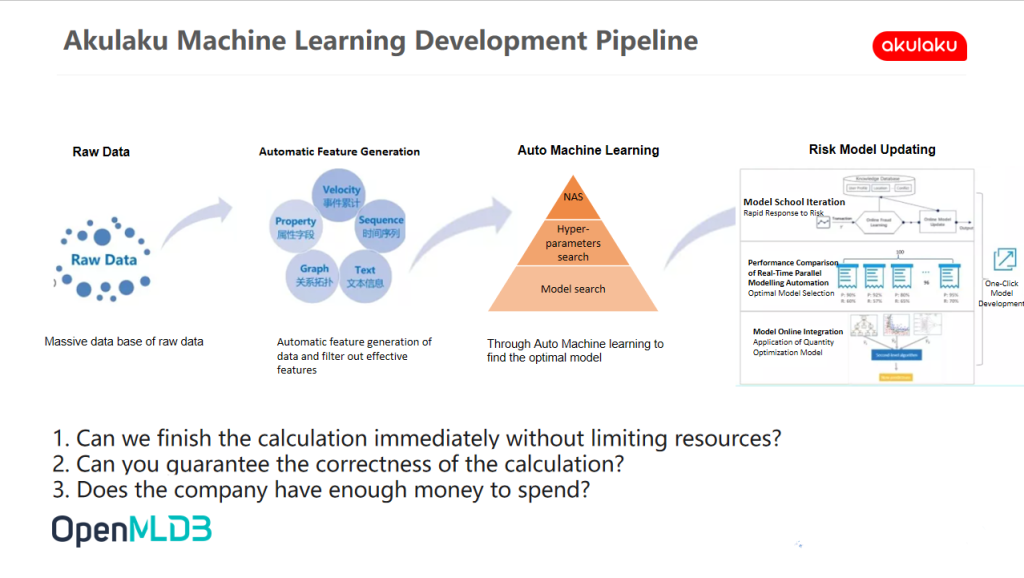
Akulaku Machine Learning Development Pipeline
The following figure is a general Akulaku structured data modelling scenario, which is usually composed of raw data, feature engineering, machine learning, risk control model update and other links. Based on the massive original data, according to the basic attributes of the data, carry out manual or automatic feature engineering, extract the attribute, text, time series and other feature attributes, complete the model construction through super parameter optimization and model selection, and finally realize the application online. The team used to update models based on KubeFlow, but feature updating has always been the biggest pain point in machine learning development. Then, can feature updating be realized simply by stacking computing resources?
- Can we finish the calculation immediately without limiting resources? Even in the case of unlimited resources, it is difficult to effectively ensure the computing speed in the face of PB structured data generated every day.
- Is it accurate to finish the calculation? Even if the calculation can be completed, the correctness of the calculation results cannot be guaranteed. In the actual business scenario of Akulaku, data warehouse and real-time data belong to two completely independent systems with completely different structures, definitions, development tools and logic. In this case, it is difficult to ensure the consistency of the calculation results of the two systems only through hundreds or even hundreds of lines of complex SQL.
- Does the company have enough money to spend? If you want to meet the needs of fast and accurate calculation at the same time, you need to recruit a team of thousands of people, a large number of experts and a huge investment of machine resources, which can only be deterred by ordinary companies
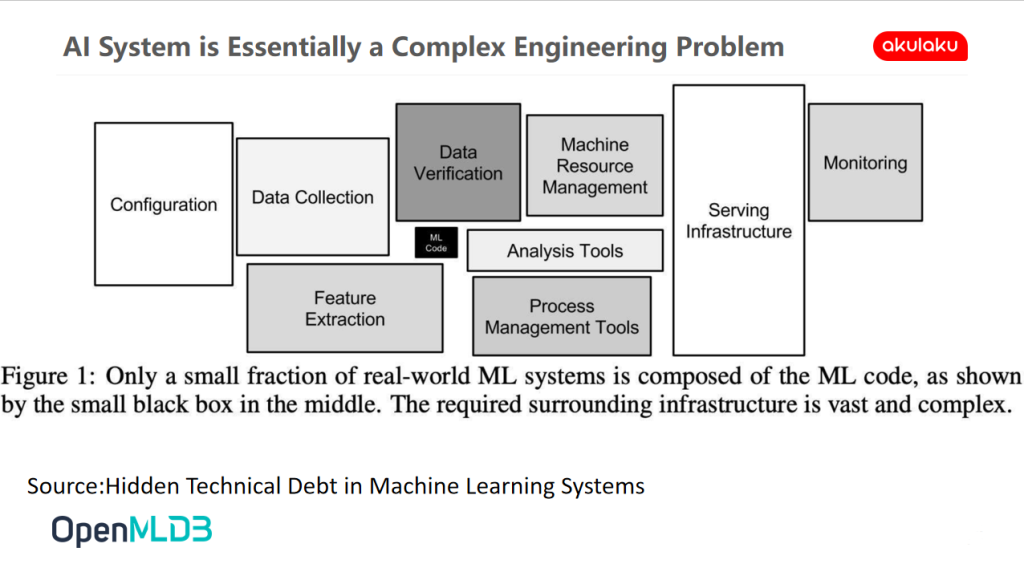
AI System is Essentially a Complex Engineering Problem
The construction of AI system is a complex engineering problem in essence. Most of the time is used for massive data processing and system construction. The construction of machine learning model can even be said to be the least energy-consuming link. Developers in the industry should feel the same way.
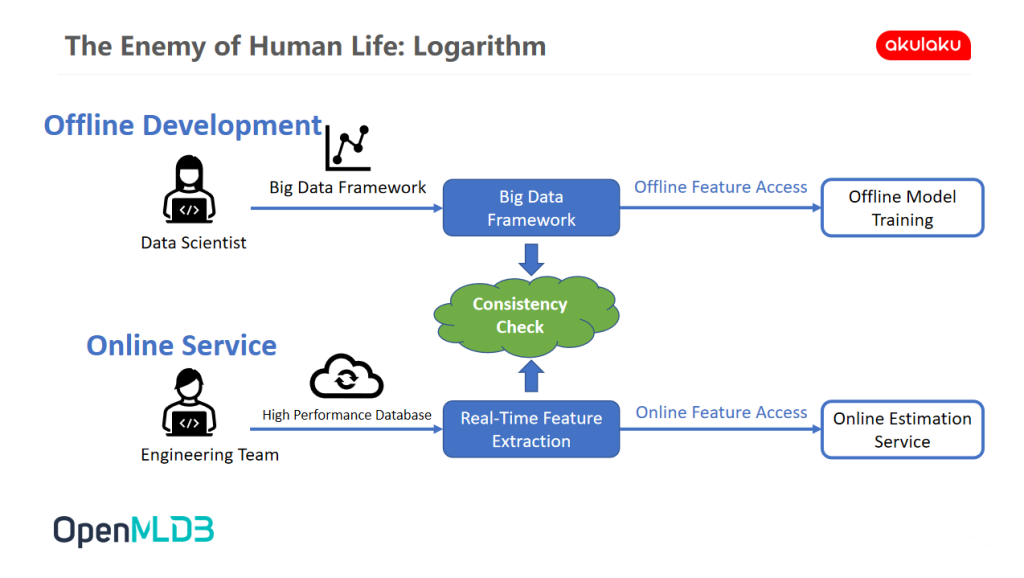
The Enemy of Human Life: Logarithm
The following figure comes from the product introduction of OpenMLDB, which very well summarizes our previous daily work status.
- Offline Development of Data Scientists: Akulaku's data scientists use the big data framework on the data platform to extract offline data features through data warehouse and data lake. After feature extraction, it is used to train the model and define all kinds of SQL.
- Online Service of Data Development Engineer: After the data scientist completes the model effect verification, he will hand over the defined feature file to the online data development engineer. Data development engineers use a set of methods to ensure real-time, stability and availability to develop real-time features and complete the service launch.
Neither team even uses a standard SQL statement. For offline, there may be a variety of implementation methods, even using native code directly. But for online, hard code must be used to solve the problem of real-time guarantee. There are many logical inconsistencies between offline development and online service. This inconsistency is very difficult to solve in the financial industry because the training goal of our model is the user's repayment bill, which is usually counted in months. Which means that if the data cannot be effectively aligned, it takes at least one month to judge whether the results of offline and online models are consistent, and the cost of that one month's time consumption is terribly high.
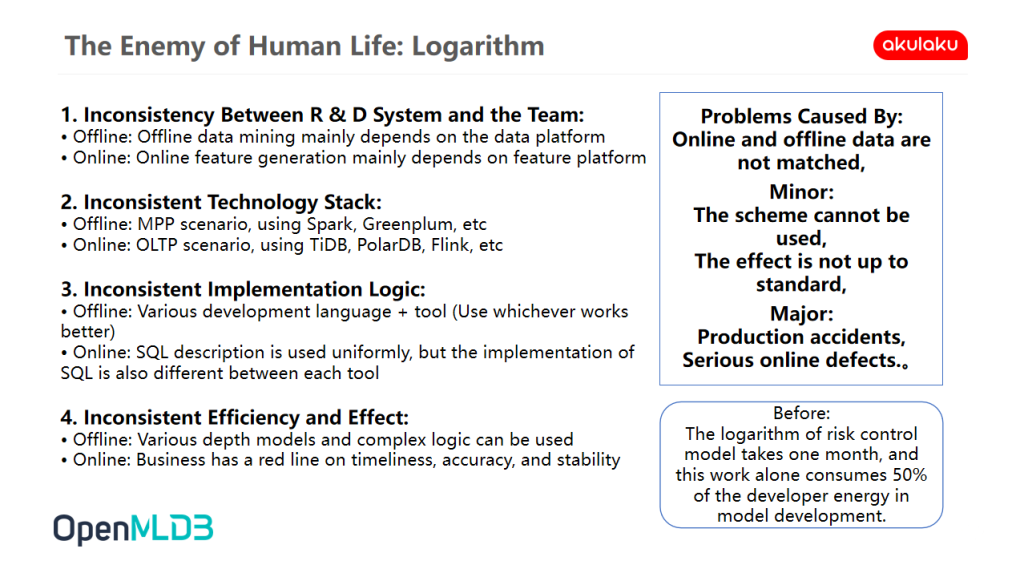
Therefore, the main problems we are facing at present can be divided into four dimensions: Inconsistency of R & D System and the Team, Technology Stack, Implementation Logic, Efficiency and Effect:
- The R & D System is Inconsistent with the Team. Offline and online are two systems, two different tools and platforms, and two different types of users. Offline data mining is mainly realized by data scientists relying on the data platform, and online feature generation is mainly realized by data development engineers relying on the feature platform.
- Inconsistent Technology Stack. Offline scenes are mainly MPP scenes, with Spark as the main tool. At the same time, some real-time warehouse tools are also used, such as hive. Online scenes are mainly OLTP scenes, and many schemes have been tried, such as TiDB, PolarDB, Flink etc. Flink may be divided into many kinds, such as sliding time window or CDC, and each method is different.
- Inconsistent Implementation Logic. Offline takes the model effect as the goal, and various tools and languages will be used to ensure the effect. Online requires the use of the same feature. Since the requirements of using model A and model B at the same time are difficult to meet, to solve this problem, it is necessary to use a unified SQL description. However, the support of each big data tool for SQL is also different, and there are differences in the underlying implementation, so the running data cannot be effectively corresponding.
- Efficiency and Effect are Inconsistent. For offline tasks, the computing power and time are relatively abundant, and more depth models or complex logic can be made. However, for online businesses, such as anti-fraud in the order setting, it demand high requirements for timeliness, accuracy, and stability.
These inconsistencies have brought many problems to the business realization. The mismatch between online and offline data may lead to the scheme not being used and the effect not reaching the standard, or production accidents or serious online defects. At the business level, if the feature calculation task cannot be completed quickly, users need to spend one minute waiting for the verification of fraudulent transactions, which will cause great loss of users. The reality we often face is that we spend a lot of time making an effective offline scheme, but it can't be used online. However, if the timeliness and accuracy of online applications are compromised, the effect will decline. The most terrible thing is that if this problem is not even found in the logarithm link, it must be a production accident or some kind of online problem that has not been solved after going online, which is a very painful point in the financial field. If each feature is a few hundred lines of SQL statements, it cannot be solved in a few days. Even if it is a conservative estimation, the logarithm of the risk control model often consumes more than half of the time and energy of the model development engineers, even the time consumption in a monthly cycle.
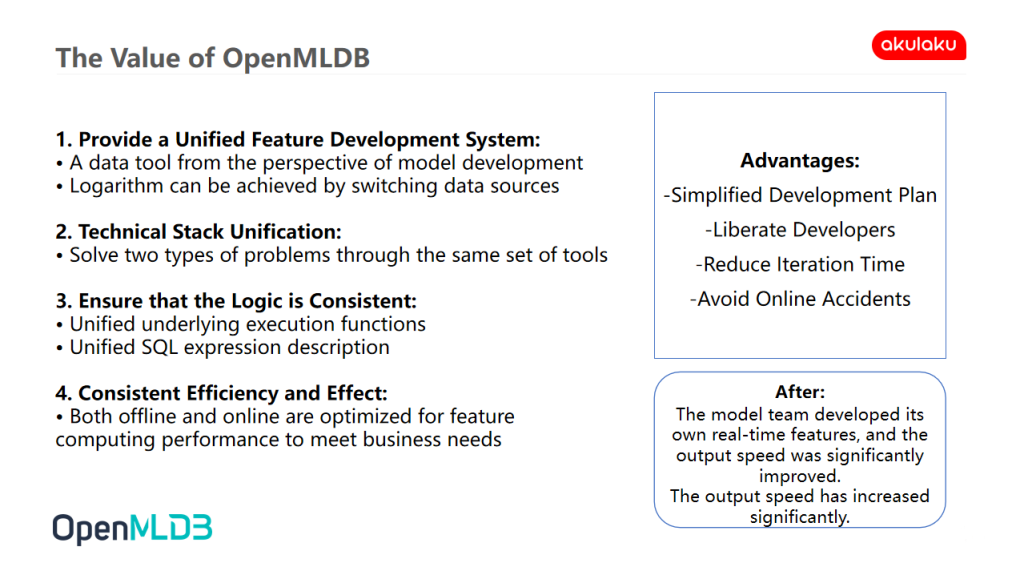
The Value of OpenMLDB
OpenMLDB provides a unified feature development system, a unified technology stack, a unified logic implementation, and a unified efficiency and effectiveness
- OpenMLDB Provides a Unified Feature Development System: OpenMLDB is indeed a data tool from the perspective of model development. For us, the use of OpenMLDB in feature development can truly enable data scientists to write SQL. For data scientists, they will not have to hand over the real-time feature development work because the performance of the tools they use is poor or cannot meet the online requirements, to avoid the inconsistency caused by the development of two different teams.
- OpenMLDB Provides a Unified Technology Stack: OpenMLDB provides a unified technology stack online and offline. Data scientists do not need to learn Spark and PolarDB while learning Flink, which can effectively reduce the threshold of learning and the difficulty of getting started.
- OpenMLDB Ensures Consistent Logical Implementation: We have tested that the results of each underlying execution function of OpenMLDB are consistent. The SQL expression at the top level of OpenMLDB is the same when changing offline to online. Only some prefixed statements need to be changed.
- OpenMLDB Provides Consistent Efficiency and Effectiveness: OpenMLDB can basically ensure that the speed of online execution is consistent with that of offline calculation without great deviation. We have tested the offline data calculation, and the speed is basically the same after pushing to the online.
In the past, using the traditional Kafka + Flink method, the speed of offline version and online version cannot be guaranteed to be consistent. In case of sudden increase of data, external memory explosion or data dispersion back on the line, the calculation speed will be greatly affected.
These consistency capabilities of OpenMLDB are of great value to us.
- First, Simplify the Development Scheme. Some of Akulaku's models began to let algorithm students write SQL directly and deploy online directly.
- Secondly, Liberate Developers. Because of this advantage, some developers can be liberated to do more in-depth and less repetitive work.
- Third, Shorten the Iteration Time. The iteration time is shortened, and there is no need to check for the model consistency in months.
- Fourth, Avoid Online Accidents. Based on the above three points, some online accidents have been avoided.
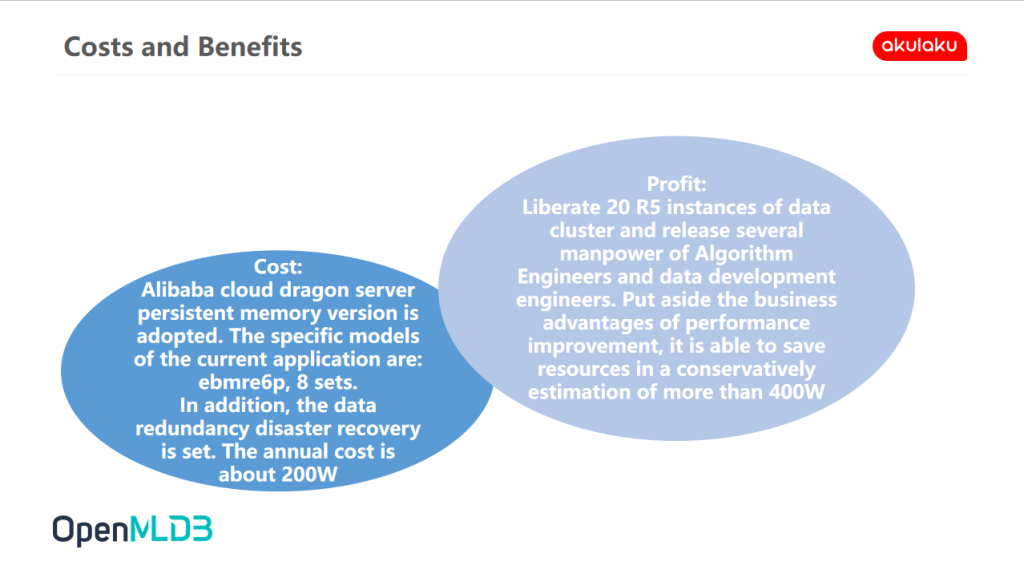
Costs and Benefits
The following figure shows the statistics of costs and benefits after we use OpenMLDB.
- Cost: The annual cost is about 2 million. At present, we are trying to use Alibaba cloud's DPCA bare metal server persistent memory version, which is about 20000 RMB / set / month, and the annual cost of eight machines is less than 2 million.
- Revenue: Save resources, conservatively estimated at more than 4 million. In terms of revenue, after using the persistent memory version of Alibaba cloud dragon server, some previous big data tool clusters based on timing or Spark have been liberated, and about 20 128G machines have been released, which is also about 2 million machine costs. In addition, the energy of many algorithm and data development engineers is also released. Data development engineers do not need to repeat hundreds of features. Algorithm engineers are liberated and do not need to participate in logarithm. It is conservatively estimated that the savings of labour and machine costs are more than 4 million.
Here's a supplement. Eight machines are our current temporary usage. We still need to configure appropriate resources according to the amount of data within our enterprise and the usage scenario.
【03 | Business Scenario Application】
Business scenarios are the focus of my introduction this time. We have tried many scenarios. This time, we show the key business scenarios of our company, such as risk control scenario and several scenarios with the best effect of OpenMLDB in actual combat. Let's get started.
Scenario 1 | RTP System Case
RTP service is a sorting service for general scenarios. If the sorting service wants to be universal, it will face the challenge of various types of characteristics.
Our previous practice is to first make a real-time data warehouse of the original data and generate features through independent feature services based on real-time data warehouse. Then put the generated vectors into the model, and put the vectors or scores produced by the model into the pure sorting mechanism, which is our previous sorting system.
There are some problems in this system. Firstly, the segmentation of each component will be obvious, and the segmentation has clear benefits, such as decoupling. But the key to the sorting system is speed. If all functions are vertical for the final result, we will tend to do a cohesive thing.
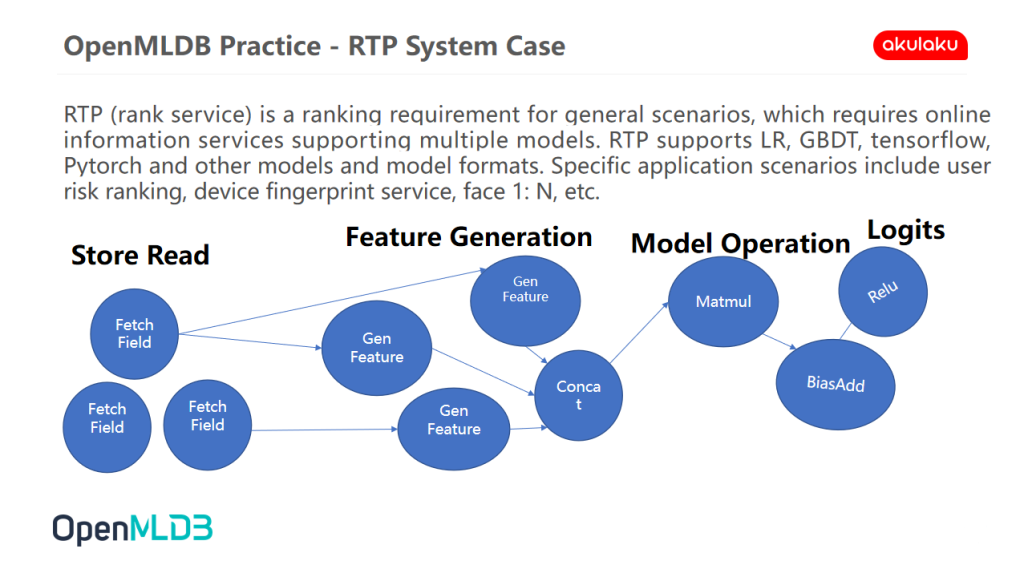
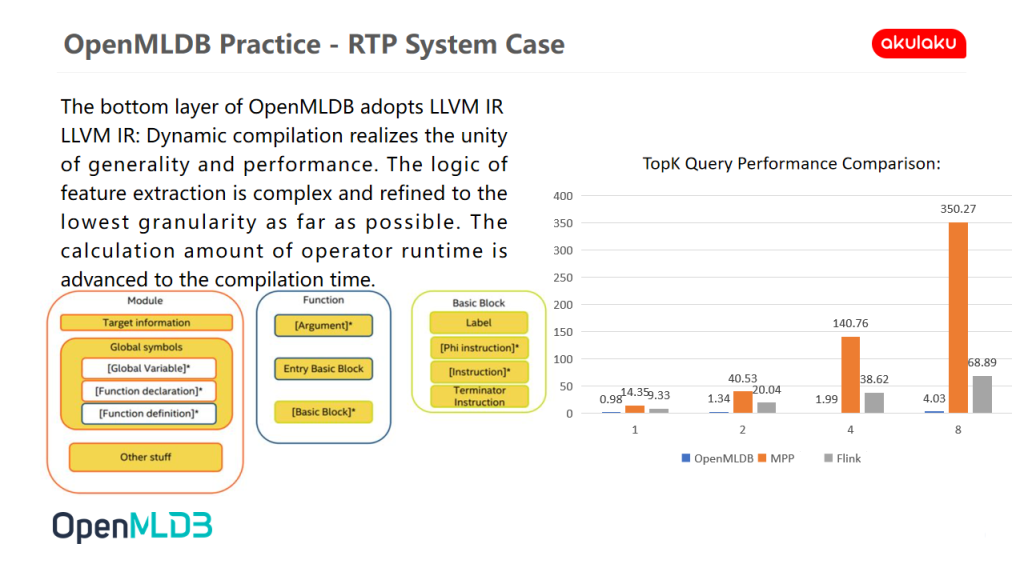
In this scenario, we use OpenMLDB. After writing the data from Kafka, we directly generate features and sort them in OpenMLDB. The following figure shows the performance after use.
From the perspective of performance, OpenMLDB, MPP scheme and Flink scheme are compared. Every time TopK queries, real-time data comes in. The corresponding MPP scheme has problems. Each time a piece of data is entered, it needs to complete a full amount of calculation, resulting in serious time-consumption. Flink's time window scheme has excellent performance, but it is not a TopK sorting tool after all. As can be seen from the histogram, the effect of OpenMLDB is almost linear.
- In the query of Top1, the query speed of OpenMLDB is only single digits, which is 9.8 milliseconds here.
- In the query of Top8, Flink can achieve the performance of less than 100 milliseconds, while OpenMLDB still grows linearly at this time, and the query speed is about 20 milliseconds.
From the principle of OpenMLDB, it should use the technology of real-time compilation to turn TopK into a query with parameters, which is directly optimized to the executed machine code, so that the query speed will increases rapidly.
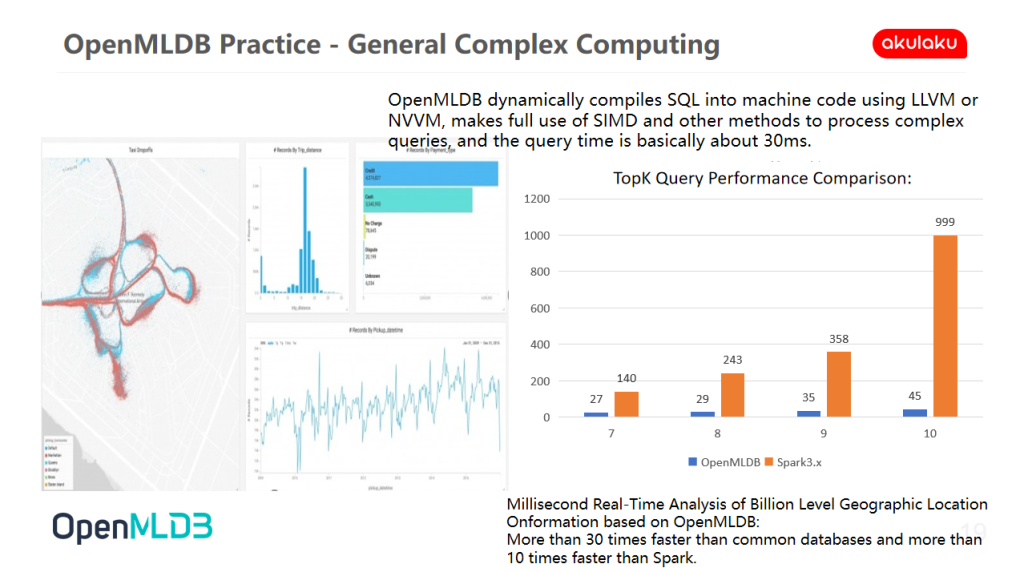
Scenario 2 | General Complex Computing
Complex calculation is difficult to express directly using various common calculation formulas in SQL, such as the query of geographical location. Because each query must pay attention to the relative relationship between all GPS, each query must be based on the full amount of data.
From the perspective of performance, OpenMLDB is compared with Spark scheme
- OpenMLDB dynamically compiles SQL into machine code using LLVM or NVVM and makes full use of SIMD and other methods to process complex queries. The query time is basically about 30ms
- Billion level geographic location information is based on the millisecond real-time analysis of OpenMLDB, which is more than 30 times faster than common databases and more than 10 times faster than Spark
If the full data query of 1 billion level data is based on Spark, the return time in the figure is not the upper limit of 1000 milliseconds, but direct OOM. In addition, there is a big pain point. First, Spark's external memory structure may be problematic. It is unable to optimize the structure of homogenization and single task completion, resulting in poor external memory storage performance.
To sum up, this is the second scenario I recommend you, such as tag propagation, graph clustering, GPS real-time analysis and other tasks, or other scenarios that require full data but perform relatively single tasks.
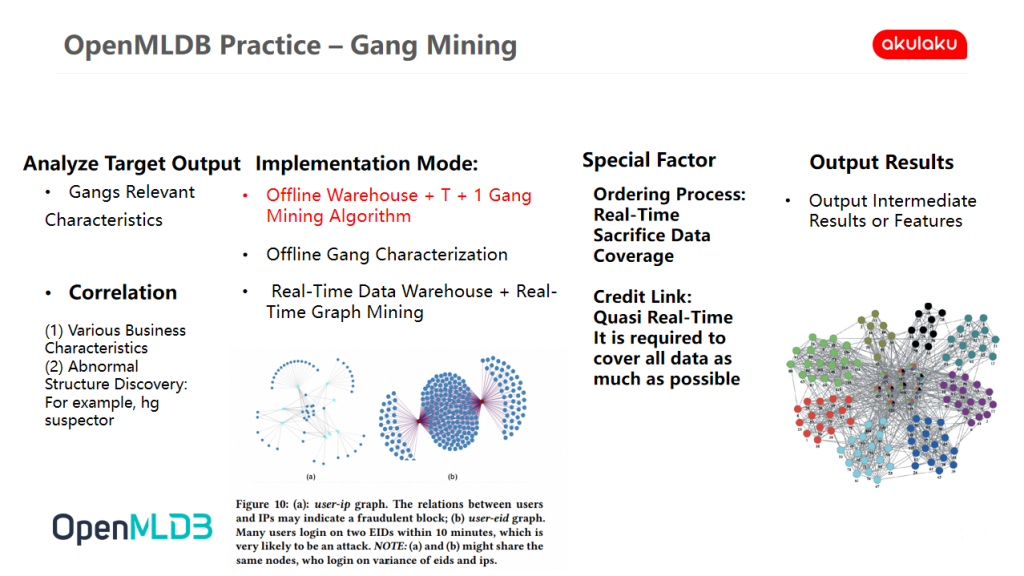
Scene 3 | Gang Mining
The third scene is our latest attempt, gang mining scene. Gangs are a key scenario within us or in the risk control model of any financial enterprise.
The characteristic of gang mining is that the features are relatively complex, and each feature needs to be associated with everyone's attributes. As a result, there are almost hundreds of lines in each round of SQL calculation, and generally there are hundreds of features.
We need to start from the single link and cover all data in real-time. This will bring the second problem. For example, the credit link can be done in minutes, and all the data can be pulled in for a calculation. However, the ordering process is basically millisecond. If you sacrifice the data coverage, you will lose the model effect. If you want to ensure the accuracy of the data as much as possible, you can't give real-time feedback in the ordering process. You can only make prediction after the user completes the order, which will have a big problem. OpenMLDB can handle a large number of real-time processing very well.
The Past Implementation Methods Cannot Meet the Real-Time and Hard Real-Time Requirements of Gang Mining Business Scenarios:
- Offline Warehouse + T + 1 Gang Mining Algorithm Cannot Meet the Real-Time Requirements: Our previous implementation method was to use offline warehouse and T + 1 Gang mining algorithm, such as HG suspector or some tag propagation methods. The biggest pain point is that the feature cannot complete the calculation in hard real-time. Gang scenarios have high requirements for real-time, because abnormal fraud gangs basically run after rolling, which will not give risk control a lot of reaction time. It is possible that a day's activities can be collected on the same day. If one group of people is found to be conducting a fraud only the next day, it has almost no significance to the business by then.
- Real-Time Data Warehouse + Real-Time Graph Mining Cannot Achieve Hard Real-Time Effect: Real-time graph mining can be solved by incremental method, but the consistency between real-time data warehouse and online streaming features has become a bottleneck. We haven't found a good solution before. At that time, we tried Kafka + Flink CDC, which is relatively barely available and can achieve asynchronous real-time. However, due to the performance of external storage, we can't fully achieve the effect of hard real-time.
OpenMLDB is Applied to Gang Mining Scenarios to Meet the Hard Real-Time Requirements of Business and Realize the Computing Speed of Tens of Milliseconds to 200 Milliseconds
It can be said that the previous schemes are not available under the hard real-time requirements. Recently, we used OpenMLDB to solve the real-time feature calculation. Through the SQL syntax currently supported by OpenMLDB, we reproduced the features of the graph, and pushed it online for streaming real-time calculation. The test found that OpenMLDB is available, and the time consumption is basically tens of milliseconds to meet the business requirements to no more than 200 milliseconds.
We also did some research and compared OpenMLDB with some time series databases. At present, the advantage of time series database is the universality of any time series scenario, including the coverage of SQL. However, for a specific scenario, especially if we need a partial modeling and less strict time series scenario, there will be some problems. For example, some join operations may not be supported. Because the time series database pays more attention to the performance of single table with only timeline, OpenMLDB is targeted at this point, and the development difficulty of OpenMLDB is significantly lower than that of time series database, so we finally chose the scheme of OpenMLDB. In the past, some intermediate results will be made and sorted in combination with the sorting service. Because OpenMLDB has good sorting performance, and it can directly output the final results without intermediate links.
【04 | Evolution Suggestions】
Part 4 introduces our suggestions on the evolution of OpenMLDB after use and includes some points that requires attention in the current version.

From the Perspective of Model Development Engineer
- SQL Statement Method Support and the Multi-Table Joint Query can be Further Improved: The current SQL statement syntax and specific function support are expected to be further improved. Multi-table joint query sometimes has some defects
- Some Statistical or Model Methods can be Integrated into the Call Form of SQL Statement to Expand the Space of Feature Development: Some statistical or model methods can be integrated into the call form of SQL statement, which is somewhat similar to SQLflow. PC or onehot can be integrated into the function of SQL statement, which can be called by writing the implementation of SQL. All the work of machine learning feature engineering can be completed in OpenMLDB in a pure closed loop. At present, OpenMLDB supports SQL syntax and can almost complete 90% of the business feature development
Data Development Engineer Perspective
- Each Cold Boot of the Current Version is Still Relatively Complex, Which Simplifies the Preparation of Unified Data: Due to our frequent experiments, we found that each cold boot is relatively complex. We have eight machines. Each time, we need to make the offline data into a table with similar structure of online data flow, fill in the data first, and then access the online real-time data. This is actually a bit like beast. Beast has the same characteristics when we tried it before. It only manages itself and sorts all the data according to a certain sequence, but it does not really simplify the data preparation. Users need to be familiar with the structure of beast feature store in order to use it well. I hope OpenMLDB can be optimized from the perspective of users.
- Support a Longer Time Window to Meet Larger Task Applications: On the time window, we hope to support a longer time range. At present, 90% of the features of Flink can be solved through a time window within 24 hours. However, there are some features, such as device fraud cases and the fingerprint ID of the same device, which may be associated with multiple devices within one year, and Flink's effect on such needs is not particularly good. I think this is also a breakthrough.
From the Perspective of Operation and Maintenance Engineer
- Embrace Cloud Native, Provide Cloud Native Version, and Reduce Operation and Maintenance Costs: At present, data tends to directly use cloud native database, because as an organization that relies heavily on stability, cloud native will bring us great advantages. Small and medium-sized companies like ours will not develop a cloud system by themselves.
- As a Database Product, Provide More Supporting Tools, Such as Better Audit, Log, Permission Management and Other Support: As a database product, it still needs more supporting tools to smoothly hand over it to the operation and maintenance team, such as better audit, log and permission management. At present, due to the problem of permission management, we have built two sets of OpenMLDB internally, developed and used the test environment offline, and then copied the SQL to the online environment, because we are worried that the lack of permission management will lead to mis-operation and confuse some data or information online.




