


This article is based on Lu Mian's speech in "OpenMLDB Meetup No.1".
Related speech videos
(Video)
Open-source Machine Learning Database OpenMLDB: Providing Full Stack FeatureOps Solutions for Enterprises
Today's speech focuses on the full stack FeatureOps solution provided by OpenMLDB to enterprises and introduces the main features of OpenMLDB and the new functions of the newly released version 0.4.0.
First of all, let me introduce myself. My name is Mian, Lu. I graduated from the Computer Department of Hong Kong University of Science and Technology. At present, I work as a System Architect in the 4Paradigm. I am mainly responsible for the database team and high-performance computing team. At the same time, I am also the main R & D director of the open-source project OpenMLDB. Currently, my main focus is on Database System and Heterogeneous Computing.

Today's sharing mainly includes three contents:
- Background Introduction: The challenge of data and characteristics of AI engineering landing.
- OpenMLDB Provides Enterprises with Full Stack FeatureOps Solutions: Why do you want to make FeatureOps, why do you want to have OpenMLDB, and what are some of the main features of OpenMLDB.
- OpenMLDB's Current Open-source Status, Development Status and Features of Version 0.4.0.

[01 | Challenge of Data and Characteristics of AI Engineering Landing]
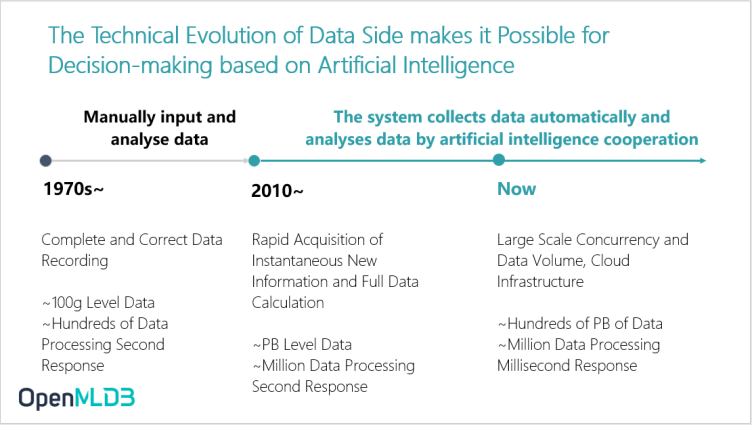
The Technical Evolution of Data Side makes it Possible for Decision-making based on Artificial Intelligence
Today, the large-scale and rapid evolution of data makes it possible for artificial intelligence decision-making. This is because 10 or 20 years ago, the amount of data may only be 100G for enterprises, where the data scale is considered very small in the present days which mainly depends on manual input for data analysis. However, the amount of data has greatly improved over the years, and it is now possible for us to make hundreds PB of data. This huge amount of data not only makes it possible for us to make artificial intelligence decisions, but also brings a very big challenge of how to do data governance.
Correct and Efficient AI Data and Feature Supply has Become a New Challenge on the Data Side
Enterprises spend up to 95% of their time and energy on data governance which includes data collection, data cleaning, data processing, data calculation and data supply. Today, there are many data governance schemes in the industry such as Hadoop, MySQL, MEMSAL, Oracle and DeltaLAKE. These infrastructure software plays a very important part in building AI systems. But, have these software solved the problem of AI engineering landing? In fact, many of the existing solutions we see today do not completely solve the data problem of AI engineering.

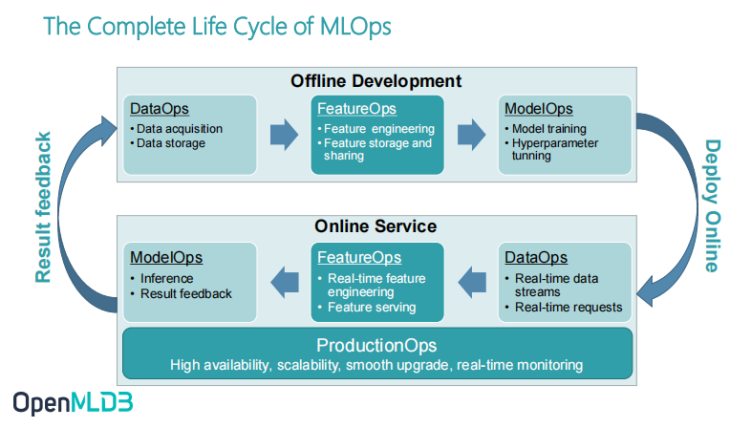
Complete Life Cycle of MLOps
In order to understand the problem of AI engineering landing data, let's first introduce some background information. Let's get started with a recently popular term called MLOps. MLOps covers all tool sets and, operation and maintenance mean of the whole life cycle of machine learning from development to launching, to operation and maintenance.
Take the MLOps apart to get this diagram. It is divided into two separate processes: Offline Development and Online Service. Why are there these two processes? We notice that the high-level components in the two processes are actually the same including DataOps, FeatureOps and ModelOps. However, the two processes are still very different itself.
The development process of artificial intelligence follows this figure. First, there must be an offline development and offline training process. When the model training has met the requirements, it will be converted to online services. This online service is also called inference, which is reasoning in ModelOps.
Although these two processes have some similarities, they are actually very different in the implementation of algorithms and the requirements of landing projects. When MLOps practice enterprises are truly implemented, these two processes are often viewed separately. In these two processes, we can see DataOps, FeatureOps and ModelOps. In offline development, DataOps is responsible for data collection and storage.
FeatureOps is the part I want to focus on today. It mainly includes feature engineering, feature storage, online real-time feature engineering and feature service. ModelOps covers offline model training and online reasoning.
In short, these six components constitute the overall closed loop of MLOps. There is another section of ProductionOps which is a very important section for enterprises to truly implement artificial intelligence engineering. When doing online services, we will attach great importance to these enterprise level cores, including highly available scalable capacity, upgrade, and monitoring which are very essential. Therefore, ProductionOps, as a sub module, is included in MLOps.
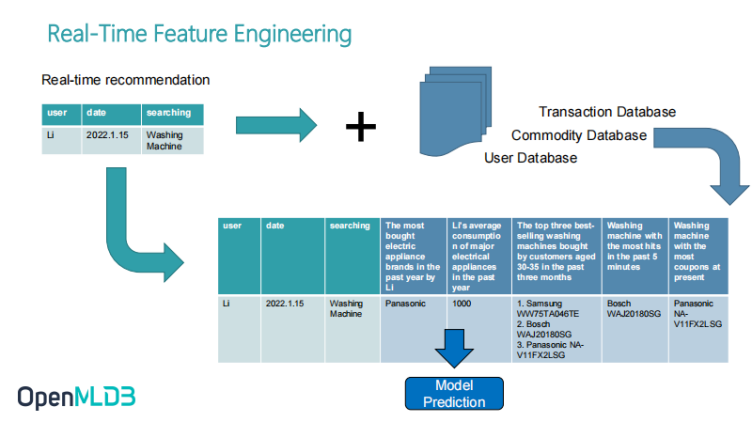
FeatureOps – Real-time Feature Engineering
What are the main functions of FeatureOps? Its main function is feature engineering. For example, real-time feature engineering which also includes an offline feature engineering. The main difference between the offline feature engineering and real-time feature engineering is that we focus on the overall characteristics of real-time computing.
Take an example of personalized search. For example, Li wants to buy a washing machine at a certain point of time and searches for the washing machine. After the search behaviour is triggered, what will the whole feature engineering do? The first real-time behaviour features that come in are just these three original features: User ID, data and what he is searching for. If we only use these three features for model training and reasoning, it cannot achieve a very good model accuracy.
At this time, we will need to do a feature engineering. The so-called feature engineering is that we further pull some historical data from the database. For example, we pull some historical data from the transaction database, commodity database and user database, and then combine and calculate to get some more complete and meaningful features.
At the far right of the picture is a real-time feature. For example, if an anchor is carrying goods, or TMall (Online Shopping APP) happens to have a batch of coupons being issued, it will reflect a real-time feature such as what is the model of the washing machine with the most coupons or the largest discount, or what is the washing machine with the most clicks in the past five minutes. It may also have some characteristics combined with Li's past consumption behaviour. For example, what is the most electronic brand Li bought in the past year, what is his average consumption level, and all these characteristics are combined. These new derived features are derived through feature engineering (or feature engineering). Finally, it is combined into a complete feature list, and then give it to the later model prediction. Therefore, doing feature engineering includes the highly important feature engineering steps.
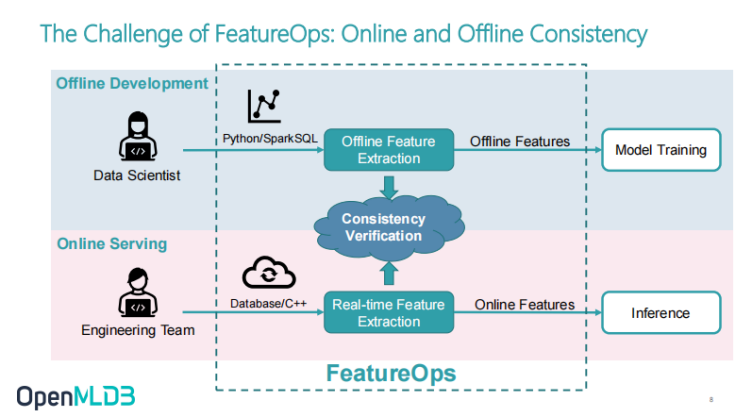
The Biggest Challenge of FeatureOps Engineering - Online and Offline Consistency Verification
Next, let's take you to understand how feature engineering is done in the actual landing process. The general process is that at the beginning of making AI models, data scientists first write feature scripts. The so-called feature scripts are mentioned above. How to extract these features and what features to define such as what features to extract and what features with the largest trading volume in the last three days.
The data scientist will first enter the field to write the feature script, and then followed by the model training. When the data scientist finishes this part and achieves satisfactory results, that is, after the feature script and model are adjusted, the data scientist will move on to the business online portion. Then, an engineering team will be responsible for the online portion of the business and further intervene.
Why can't we just take what the data scientists do online?
1. Data scientist focuses on the accuracy, precision, and quality of the model, but does not care much about the latency, QPS, etc. after the model goes online.
2. Most scientific data scientists uses Python, RSQL, which is easier to use for batch processing. This kind of batch-oriented framework can cause many problems when it is directly implemented online:
- The logic of online is different from that of data processing.
- In terms of performance, this batch processing framework cannot meet the needs of real-time processing.
Therefore, there will usually have an engineering team that will translate the script of feature engineering and the modelling method of model training done by scientists into a set of online things. The online engineering team will not use the framework of Python to go online. This is because they are very concerned about latency and QPS. Instead, they will use some high-performance databases, and even the language of C++ to build a set of feature extraction services, so as to get through the line of prediction services later.
The dotted line in the figure is the functional scope covered by FeatureOps. The following will focus on the functional scope covered by main feature extraction and feature engineering from offline development to online real-time feature engineering. This is because there are two sets of online and offline systems developed by two teams thus, consistency verification is inevitable. In fact, it is the most expensive section in the engineering of the whole FeatureOps. According to the experience of the 4Paradigm, the proportion of consistency verification in the whole project will be very high as it involves the alignment and joint debugging of many effects and the communication cost between people.
Possible Reasons for Online and Offline Inconsistencies
1. Inconsistency of Tool Capability. For offline development and online application, the tool stack and development stack may be completely different.
- Scientists who develop data offline prefer tools like Python and Spark; When making online applications, we should pay attention to high performance and low latency, so we need to use some high-performance programming languages or databases.
- When we have two sets of tools, they cover different functions. For example, when we do offline development, we use Python, which can realize highly complex functions, while the functions of online MySQL will be limited by SQL.
The inconsistency of tool capabilities will lead to some compromises and different effects.
2. Poor Cognition of Demand Communication. This is not a technical problem, but it is very important in the actual project implementation. Here we give an example. Varo, a very famous online banking company and has many users in the United States. Their engineers mentioned the problem of poor understanding of demand communication. They have a lesson on how to define account balance:
Obviously, the poor cognition between the two can lead to the inconsistency of the whole training effect, which leads to very serious online business problems in their applications. In fact, not only this bank, but also in the whole project practice cycle experience of the 4Paradigm. We have more or less encountered the problems caused by poor communication cognition. Once this problem occurs, the cost of troubleshooting is actually very high.
Of course, there are other reasons. Here are just two of the most important reasons listed.

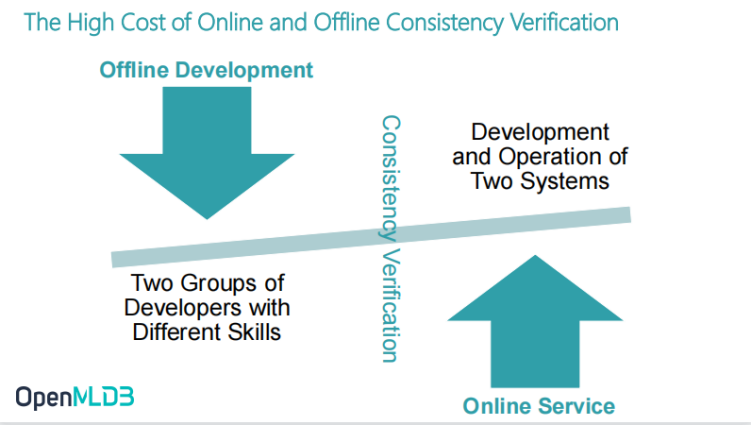
High Engineering Landing Cost brought by Online and Offline Consistency Verification
Because of the consistency problem between online and offline, verification is inevitable. One time verification brings many cost problems:
- It requires the input of two groups of developers with different skill stacks to complete the process of offline to online deployment.
- Development and operation of online and offline systems.
These two points have great costs in terms of engineering landing cost, development cost and labour cost.
[02 | OpenMLDB Provides Full Stack FeatureOps Solutions for Enterprises]
FeatureOps Engineering Solutions
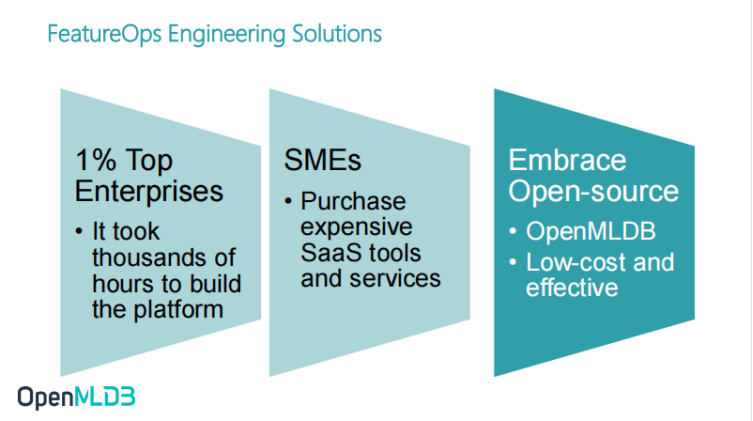
What Solutions does FeatureOps have?
Head enterprises will develop and build a platform to ensure the consistency of online and offline, but the cost they invest is also very high. In addition to these enterprises with strong R & D capabilities, the remaining enterprises will purchase more SaaS tools and services to solve this problem, because the cost of R & D may be higher than that of procurement.
OpenMLDB provides another solution. We provide open-source solutions to help enterprises solve problems at low cost and high efficiency and provide FeatureOps enterprise level solutions.
OpenMLDB is an Open-source Machine Learning Database that Provides a Full Stack Solution of Enterprise FeatureOps
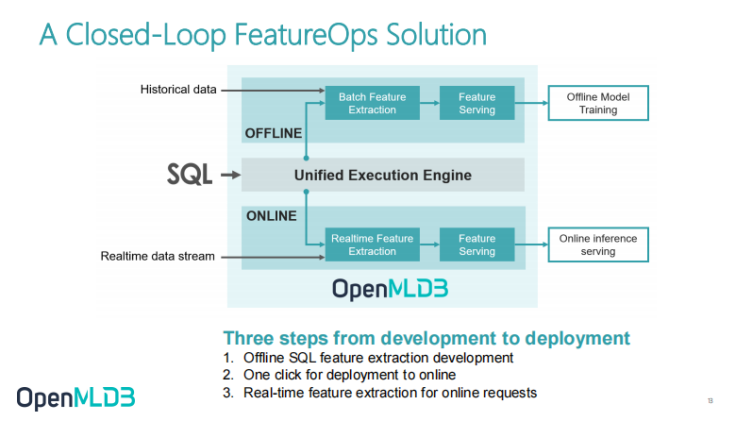
First of all, this diagram transforms the whole architecture into the architecture diagram of OpenMLDB. We can see that there are three significant differences between this picture and the previous picture:
1. In terms of exposed programming language APIs, we provide a unified SQL interface.
For developers, there is no need for two sets of development interfaces. The SQL written by data scientists in the offline development process is the last online SQL. The two are naturally unified. For external developers, it is the same language. SQL written by data scientists can be directly launch online without translation by the engineering team.
In order to ensure this feature, we have a unified computing execution engine to do unified underlying computing logic and the translation from logical plan to physical plan. Take the same SQL and translate it into an appropriate execution plan to ensure the consistency of the two to the online computing engine.
2. Here we can see that offline computing engines and online computing engines are actually separated. This is because as mentioned earlier, the performance requirements of online and offline are completely different.
When we do offline development offline, we value the efficiency of batch processing, so the offline module is essentially based on Spark thus, we have made some improvements on Spark.
3. Online services focus on the latency, concurrency and QPS of online services. Online services may only accept latency of the order of ten to tens of milliseconds. In order to achieve this goal, the whole online computing engine is a set of pure in-memory databased external memory index structure developed by our team from scratch.
It is a very efficient time series database based on external memory operation. This database was built by the OpenMLDB team from scratch without referring to the third-party database, mainly because some in-depth optimization can be better integrated and will not be constrained by some external restrictions. Because when doing feature engineering, there are some very special optimization points. In the example mentioned above, the feature engineering script may be very complex and has a strong correlation with the timing. I do a card swiping action and a search action. What we see may be the state in the first minute. This is a very strong computing engine related to persistence. Therefore, based on this point, we have developed a set of computing engine for timing feature engineering and optimization.
Based on such an architecture, the ultimate goal of OpenMLDB is to realize the development and to go online. The first step is the development of offline feature scripts, which bring offline data. After the development, the second step is to go online with one click and switch directly from offline to online. This process is basically insensitive to users, and it is control over with a command. Switch from offline to online mode, directly start a serving service, let the real-time data stream connect it, and you can directly do online services. This process eliminates the consistency verification. Without the operation and maintenance of the two systems, the cost of AI engineering will be greatly reduced.
OpenMLDB Product Feature 1: Online and Offline Consistency Execution Engine
OpenMLDB Product Feature 1: This article will not discuss the technical details of the online and offline features in detail. If you are interested, you can pay attention to our subsequent meetup. We can talk about the technical details inside. At the same time, you can also pay attention to our current OpenMLDB column, and we will continue to disclose some technical details.
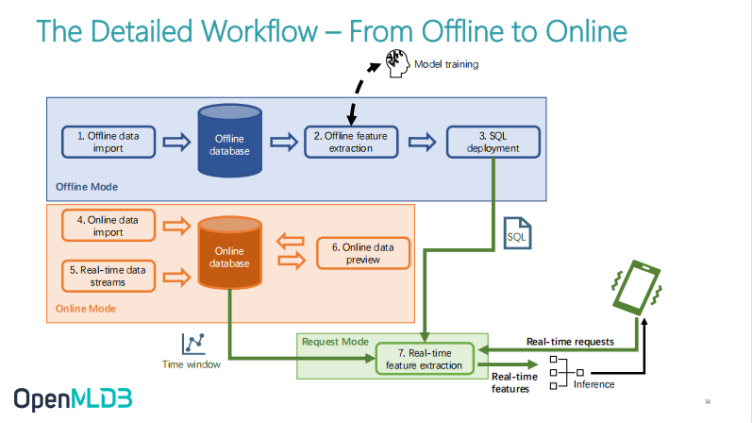
On the surface, the consistency execution engine takes a unified SQL which can be converted to Spark for offline batch processing, or to self-developed timing database for online high-performance SQL query. Some unified calculation functions will be shared online and offline. More importantly, there will be an adaptive online and offline execution mode from logical plan to physical plan. This is because the data form is very different between online and offline execution. When doing offline development, whether it is the sample table of label or the material table, they are both considered a table because these data are in batch processing mode. When online, the data come one by one, and we will pay more attention to the external memory data. Thus, some detailed conversion will be carried out to better meet the performance requirements. Therefore, through the intermediate execution engine, on the one hand, it can achieve the consistency between online and offline while on the other hand, it can meet the requirements of different execution efficiency between online and offline.
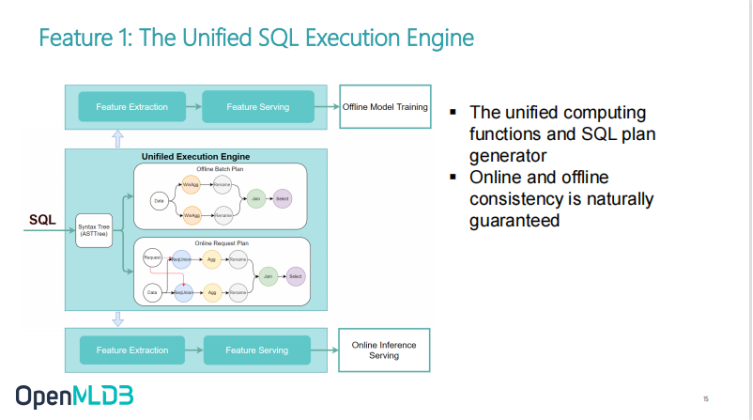
OpenMLDB Product Feature 2: SQL Centred Development and Management Experience
The second feature is the low-threshold development and management experience centred on SQL. This is very important to reduce the use cost. The figure shows our command line, which is very similar to the command line of MySQL. Then, develop the offline feature scheme in the CLI. After developing the offline feature engineering, you can switch to the SQL scheme online in one step, directly switch the offline scheme to the online with a deploy command, and then start a serving service directly. Then through the third step, you can make online requests directly.
This is to make online requests through an API, or through Python and Java SDKs. Different SDKs are provided to directly communicate and make online requests with serving servers. It can be seen that the development based on SQL and CLI is extremely low-threshold and convenient.

OpenMLDB Product Feature 3: Feature Oriented Computing Performance Optimization - Offline Computing Engine
The offline computing engine is an optimized version based on Spark. Instead of taking the original Spark directly, we have taken some measures for feature meter optimization. For example, the figure on the right is called parallel computing optimization of multiple windows. SQL defines two windows on different keys, one is group by name and the other is group by age. These are two experimental windows. In Spark 3.0, these two windows will be executed serially. Sometimes we can't make full use of the resources of the cluster thus, we changed the source code of Spark here and turned it into a generated plan, so that it can be executed in parallel.
This is one of the changes. Others include the optimization of data skew. Some optimizations are made based on modern hardware optimization technology. For example, the adaptation of the underlying CMD is based on some optimizations made in the Spark distribution. The figure in the lower left corner shows the performance comparison between our current version and the original version of Spark. It can be seen that we can still achieve a very significant performance improvement, especially for feature engineering and continuous related operations.
For detailed technical information can be found in the corresponding articles in the OpenMLDB column.

OpenMLDB Product Feature 3: Feature Oriented Computing Performance Optimization - Online Computing Engine
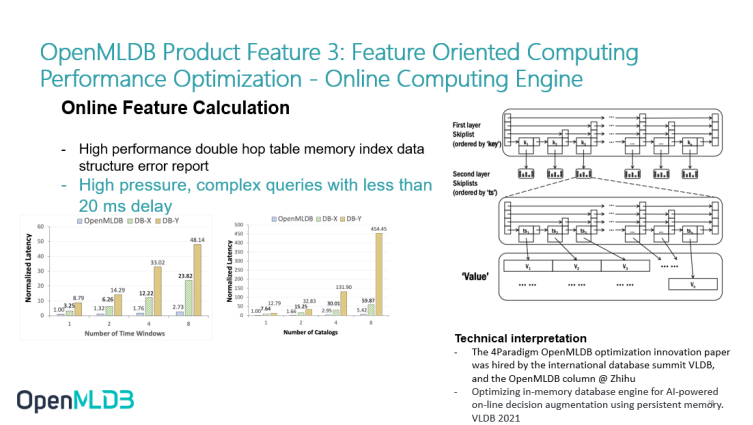
The online computing engine has built a set of time series feature database from scratch. It is essentially a double-layer jump table. The jump table structure has two layers: The first layer is to make a sort index of the jump table according to the key, and the second layer is to make a sort function according to the TS.
This structure is very friendly to continuous related queries. For example, if I want to find some consumption records of Li in the past three days, I can find them very quickly through index. Therefore, this part of the online index structure ensures that the latency can be less than 20 milliseconds under high pressure and complex queries.
Similarly, the figure in the lower left corner also shows the performance comparison between OpenMLDB and other commercial pure in-memory databases. Of course, it is based on the comparison in the case of calculating a specific workload according to the characteristics. We can see that after some optimization, especially for continuous query, our performance has great advantages. Especially when the query becomes complex such as when there are many windows, the performance latency growth of other databases will be very steep, while the latency growth of OpenMLDB is relatively stable, which can meet the needs of online business.
If you are interested in this technology, you can also go to a paper published on VLDB, in which the data structure is described in detail.
OpenMLDB Product Feature 3: Feature Oriented Computing Performance Optimization - Online Computing Engine
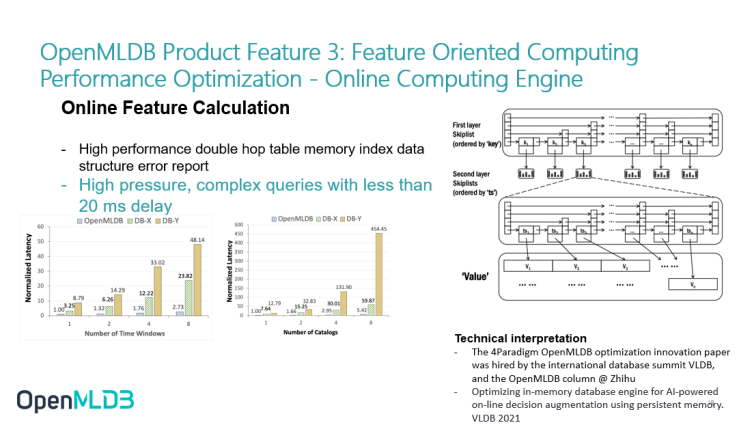
The online computing engine has built a set of time series feature database from scratch. It is essentially a double-layer jump table. The jump table structure has two layers: The first layer is to make a sort index of the jump table according to the key, and the second layer is to make a sort function according to the TS.
This structure is very friendly to continuous related queries. For example, if I want to find some consumption records of Li in the past three days, I can find them very quickly through index. Therefore, this part of the online index structure ensures that the latency can be less than 20 milliseconds under high pressure and complex queries.
Similarly, the figure in the lower left corner also shows the performance comparison between OpenMLDB and other commercial pure in-memory databases. Of course, it is based on the comparison in the case of calculating a specific workload according to the characteristics. We can see that after some optimization, especially for continuous query, our performance has great advantages. Especially when the query becomes complex such as when there are many windows, the performance latency growth of other databases will be very steep, while the latency growth of OpenMLDB is relatively stable, which can meet the needs of online business.
If you are interested in this technology, you can also go to a paper published on VLDB, in which the data structure is described in detail.
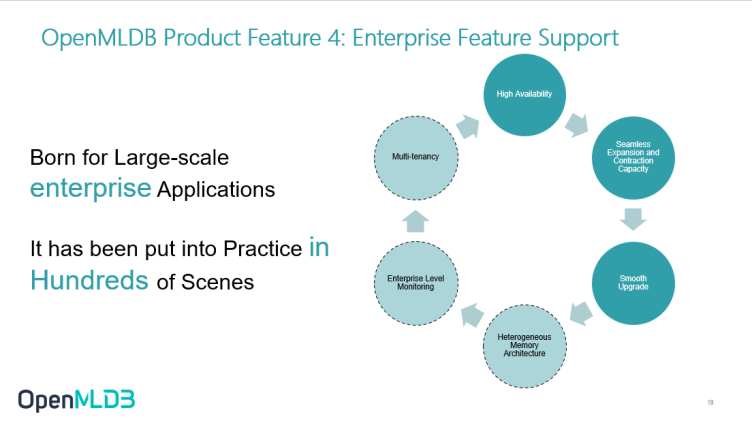
OpenMLDB Product Feature 4: Enterprise Feature Support
The fourth very important feature is some features related to ProductionOps. OpenMLDB has been applied to many large-scale enterprise applications before open-source and has been practiced in hundreds of scenarios. Therefore, we attach great importance to some features that really fall into large-scale enterprise applications such as high availability, expansion and contraction, smooth upgrade, multi-tenant, and enterprise level monitoring.
Some of the most important enterprise features have been listed in the open-source version such as multi-tenant, enterprise monitoring and heterogeneous memory architecture. Some are implemented in our internal version, and some are still under development. We will continue to improve this part of the function to better serve enterprise applications.
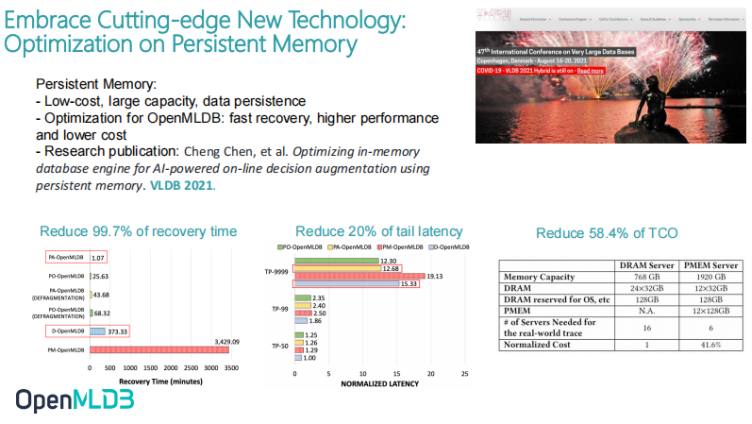
Embracing Cutting-edge New Hardware Technology: Optimization based on Persistent Memory
On the last page of technology, let's briefly mention our achievements in technological innovation. This is a paper of VLDB, which was hired last year. VLDB is the top academic conference in the international database industry. In the paper, we talked about two things:
- We have carefully described the whole implementation architecture of OpenMLDB. If you want to understand this architecture, you can also refer to the paper.
- It talks about how to combine with today's cutting-edge hardware technology. The cutting-edge hardware technology is persistent memory which was formerly called unconscious memory in academia.
Persistent memory is the first enterprise class persistent memory application in the real industry released by Intel in about 18 or 19 years ago. So, what are the advantages of persistent memory? First of all, its cost is low, and its unit price is about 1/3 ~ 1/4 of DRAM. Of course, DRAM is 1/2 ~ 1/3 slightly worse than SSD. Secondly, the capacity is large. One slot can be up to 512GB. We can insert up to 11 nodes on the server. In fact, it is easy to reach a server configuration of several TB. The other very revolutionary technology is persistent memory. The current DRAM has no data after power failure while the data of persistent memory is still after power failure. Thus, this is a very revolutionary technology.
We have combined the persistent memory with OpenMLDB online execution engine whereas the characteristics were mentioned previously. First of all, it is basically an execution engine based on pure external memory thus, the cost of running it is sometimes very high. If the scene is very large, it needs more than a dozen machines to meet the external memory demand. At the same time, it also has the problem of slow recovery time. This is because once it loses power, it needs to rebuild the external memory image from external storage which will take a long time.
So, we combined the persistent memory with the online engine of OpenMLDB to achieve three very good results:
- The recovery time has been reduced from the original 6-hour level to 1 minute. The significance of online business is actually very huge. Online business such as ordering system is not allowed to be disconnected for a long time, or it is not allowed to affect the service quality of the business after a node is disconnected. After the combination, the business can be pulled back in one minute without affecting the service quality.
- Due to some modifications of the underlying architecture, the long tail latency is also improved by 20%. In the case of TP9999, this is very significant.
- Reduced on total cost. Because the external memory of a single machine expands, the number of machines used have becomes lesser. Originally, 16 machines were used, but now only 6 machines are needed, and the cost is reduced at once. We haven't put this part into our open-source version yet, and we will consider doing part of the open-source work or part of the release function later.
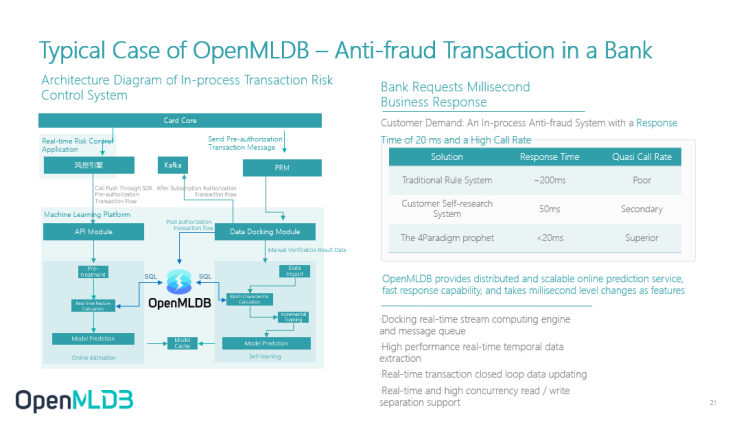
Typical Case of OpenMLDB – Anti-fraud Transaction in a Bank
Next, for a simple example in the case of a bank, OpenMLDB is actually in the position of FeatureOps. Then, in the view of customers of a bank, we can see that we have achieved a better efficiency than its original traditional rule system and customer self-developed system.
Technical Precipitation of OpenMLDB
Finally, summarize the technical precipitation. In fact, OpenMLDB has been working as a DB since the first day of the establishment of the 4Paradigm. It has not just started to develop open-source recently. In fact, it has gone through five years of research and development precipitation and has been verified by about hundreds of projects. In this process, it has applied for 8 patents, including an international top academic conference and a paper of VLDB. At the same time, we have first-class cooperation with universities at home and abroad. While paying attention to the commercialization of products, we also pay great attention to cutting-edge academic research. Therefore, if you are interested in the database research in the school, we are very open, and you are welcome to cooperate with us.

[03 | Embrace Open-source and Face the Community]
Finally, I will briefly introduce the current development status of OpenMLDB. I just mentioned that we have had a lot of precipitation in the past five years.

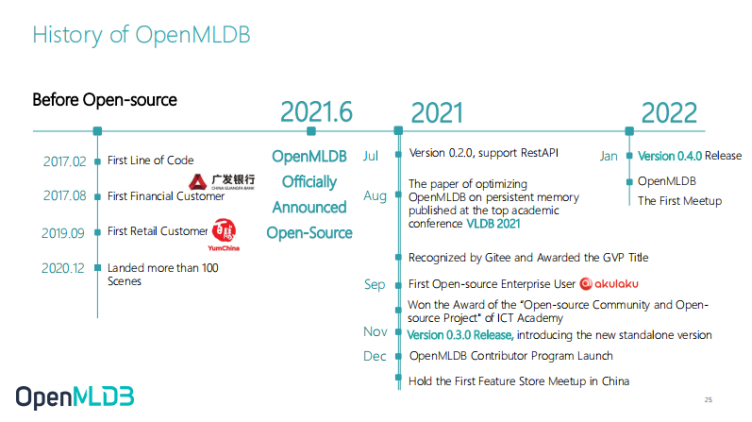
Development History of OpenMLDB
This is the timeline of OpenMLDB. Before June last year, OpenMLDB was an internal closed-source commercial version. It was open-source in June last year. After it was open-source, the highlight of this timeline is that we published a VLDB paper in August, and then we were very honoured to have the first community enterprise user Akulaku in September.
Yesterday, we released version 0.4.0. Later, we will introduce some highlights features of the version 0.4.0.
OpenMLDB Open-source Basic Information
This is a summary of some very high levels of OpenMLDB. The code does not contain third-party dependency, and the number of lines of pure OpenMLDB code is more than 300000. This amount is actually very large. There are more than 18K test cases, which have been tested over time. At present, we can see that after open-source, the code is constantly updated iteratively, and we are very grateful for some contributions from the community.

OpenMLDB 0.4.0 – Enhance SQL Centric Development Experience
Briefly introduce some highlight features of 0.4.0. One of the highlights is the development experience with SQL as the core which has been mentioned before. However, some enhancements have been made in version 0.4.0 to enable it to be used in stand-alone version and in the integrated version.

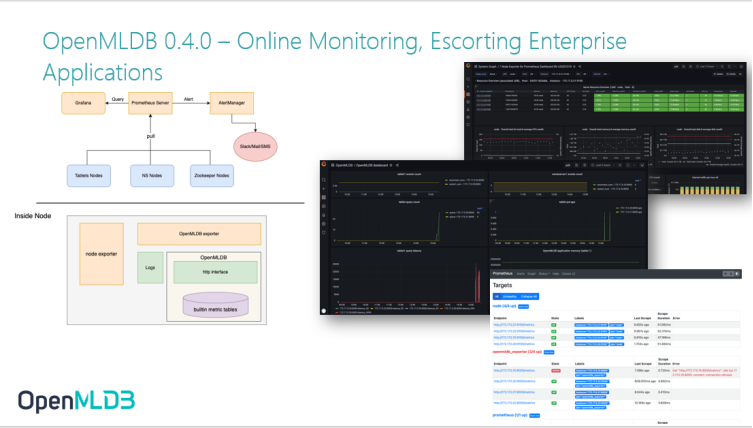
OpenMLDB 0.4.0 – Online Monitoring, Escorting Enterprise Applications
Then, another very important feature is that we introduced the online monitoring module, allowing Prometheus and Grafana to access the online monitoring module. This feature is introduced for the first time, so there are still many areas that need to be improved. But we are able to carry out at least some basic monitoring. This will be a very important function in the later part of the project, and we will continue to improve it.
OpenMLDB 0.4.0 – Complete Document Governance
Another very important milestone is that we have finally made a very perfect document governance. In fact, our document website has been launched. You can check our documents today. There are OpenMLDB introduction, quick start tutorials and some very detailed SQL language references. You can go and see them if you are interested.
The official website of OpenMLDB will be launched soon
Another notice is that the official website of OpenMLDB will be launched soon. It should be launched at the end of this month. Please look forward to it.
Subsequent Important Features of OpenMLDB
Finally, let me briefly talk about some very important features in our subsequent planning. Our features will move towards three main goals: Reducing the Use Threshold, Reducing the Use Cost, and Keeping Up with the Opening Up of Downstream Ecology.
Subsequent iterations will continue to move towards these three goals. For example, if we plan a cloud native version and replace the external memory version with a TCO version based on external storage optimization, the long-term window can support a larger amount of data including the outflow engine of automatic feature engineering and the edge version and we will sort them according to priority. If today's online partners are particularly interested in a feature, this is exactly the feature you will want to use in your business. You can provide with your feedback. We will see the priority of your needs according to the feedback from the community. We also welcome you to joint development from the community.






