

本文由 Akulaku 资深算法开发工程师黄泓 4 月 23 日在 DataFunSummit 上的演讲「Akulaku 智能计算系统及应用」整理而成。
在特征计算系统的实现上,Akulaku 采用场景驱动方式,通过使用 OpenMLDB,更加高效地实现特征“现用现算”。
Akulaku 的场景和需求
Akulaku 是一家主打海外市场的互联网金融服务提供者,服务内容包括网上购物和分期付款,现金贷,保险等等。也就是 Akulaku 包含金融属性和电商属性,以金融属性为主。
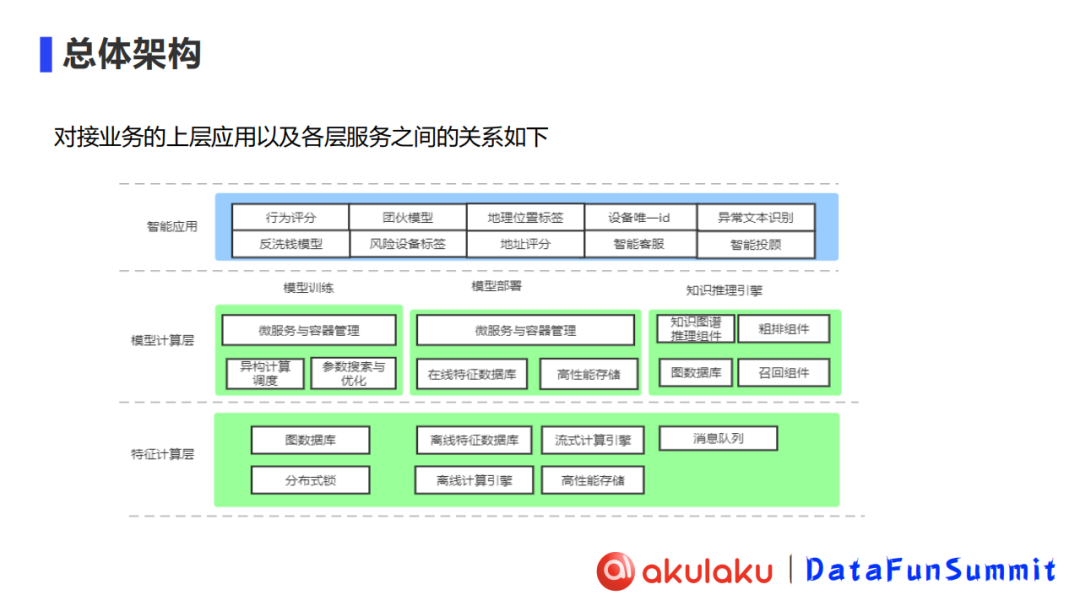
主要的应用场景包括金融风控、电商智能客服以及电商推荐等等。Akulaku 的智能计算架构(如下图所示)整体上分为 3 层,从下往上依次为特征计算层、模型计算层和智能应用层:
- 特征计算层:包含底层特征和指标的计算产出
- 模型计算层:包含模型的训练、部署和针对知识图谱的推理引擎
- 智能应用层:基于部署的模型、训练的模型和知识推理引擎,我们搭建了一系列的智能应用,包含例如反洗钱模型、风险设备标签等等
智能计算系统构建的难点
虽然业务场景比较丰富,但难点主要聚焦在特征计算环节,大致包含以下三点:
- 线上部署:低延时,高时效性
- 线下分析:高吞吐量
- 逻辑一致:线下分析和线上部署的逻辑需要完全一致
而在实际场景中,同时满足这三点并不容易。

在我们的计算场景中,主要包含三类特征和三类模型:

架构与案例 | 智能计算系统(特征计算方式)的实现
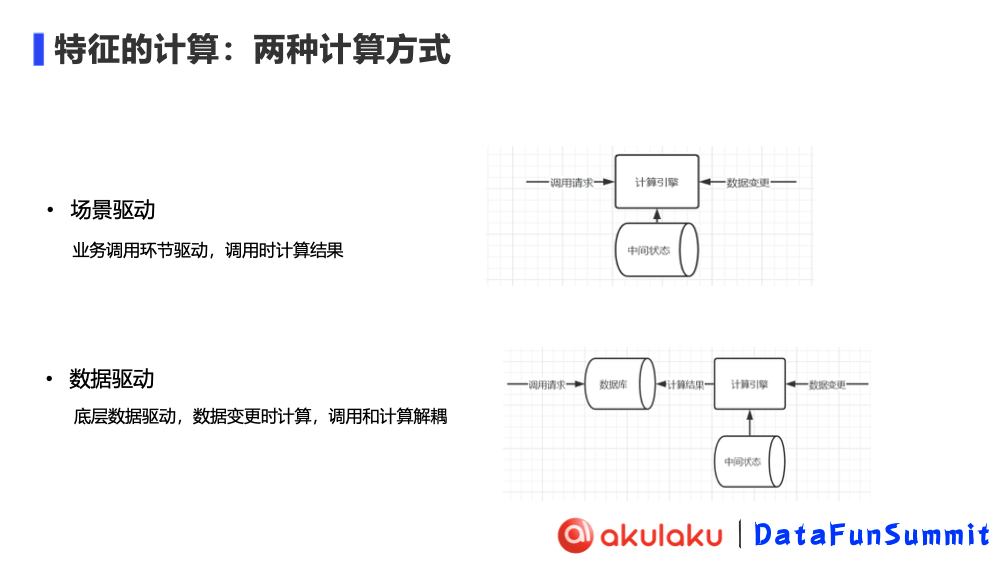
特征计算方式主要分为场景驱动和数据驱动两种。可以通过下图更直观地感受到二者的区别。
具体案例分析:以“时间窗口”为例

以典型案例“时间窗口”为例展开。时间窗口特征,即时间窗口内的统计和加总,比如近 N 天的订单个数,要求实时更新,时间窗口实时滑动,下单环节延时不能超过 200ms。且在具体业务中,还会有复杂的关联需求 ,比如“团伙近 3 天订单个数”。
考虑场景驱动,比较简单直接的想法是直接在关系数据库中写 SQL,但这一方案无法控制延时,在极端情况下延时有可能超过200ms。所以团队考虑了数据驱动的方式,尝试使用 Flink 计算引擎实现滑动窗口的逻辑。
数据驱动的特征计算方式(基于Flink CDC 及 Flink SQL的方案)
目前,Akulaku 数据驱动的特征计算方式是基于 Flink 的。Flink 又有两种做法,一种是 Flink CDC,一种是 Flink SQL。
Flink CDC
- 思路:
- 基于关系型的数据库做中间的存储。
- 数据的变更是根据中间状态的变更触发最终数据的更新。
- 优点:
- 因为 Flink CDC 依赖于外部存储,所以可以做状态初始化。比如需要计算近15天的特征时,就不需要将15天前到现在的特征进行重新计算,而是把前14天的数据先初始化到状态存储里再计算到现在。
- Flink CDC 外部存储的运维是比较稳定方便的。
- 缺点:
- Flink CDC 缺点是比较依赖外部数据库的性能,而且实现起来比较笨重
- 线上线下的逻辑差异比较大。
Flink SQL
- 思路:
- 方案在思考时,我们使用 Flink SQL 动态表的抽象。
- 使用优先队列和 MapState 管理数据的过期和数据的出窗。
- 优点:
- 可以利用 Flink 的特性,包括状态管理。
- SQL 相对来说会好理解一些,语义回溯比较接近,便于做流批一体。
- 缺点: 踩着 Flink 的一些特性的边界来做,比如我们刚刚说过的 watermark,它既不是事件时间,也不是处理时间,是我们自己维护的一个状态。也就是说我们在事件的设计上还是跳脱了 Flink 的设计,但是其他很多特性都在复用,比如说状态管理和聚合时的批次提交。
考虑数据驱动的计算方式,可以基于 Flink CDC 进行数据计算,主要思路是:
- 使用中间存储保存窗口表,对于新进入的数据,只维护近 X 天的数据;
- Flink CDC 捕捉窗口表的变更,计算出最终结果。
场景驱动的特征计算方式(基于 OpenMLDB 的方案)
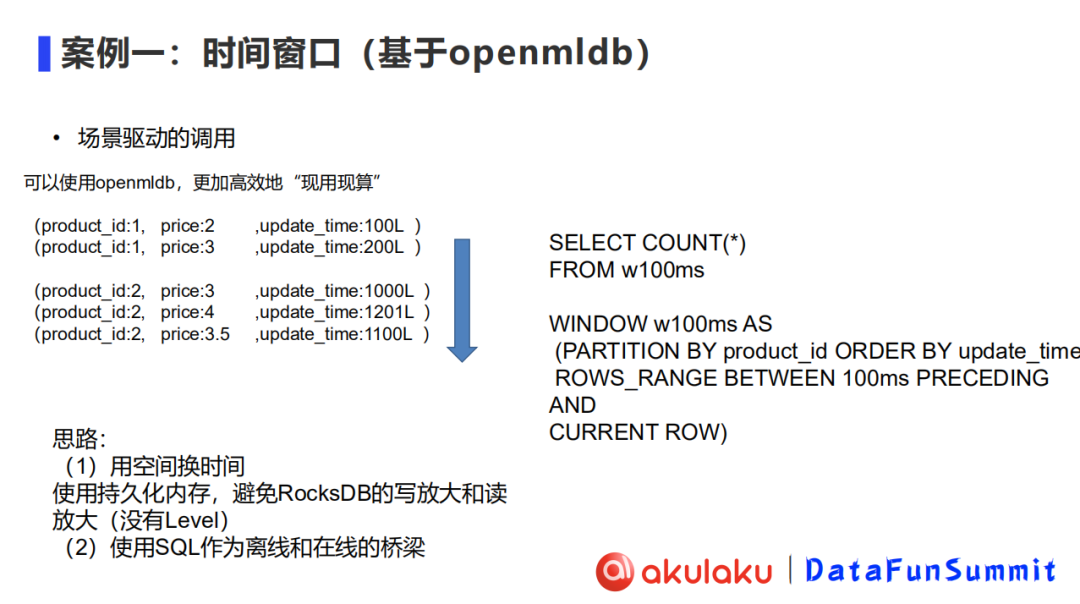
场景驱动的计算方式也并非不可实现。通过使用 OpenMLDB,可以更加高效地实现特征“现用现算”。
基于 OpenMLDB 完成场景驱动的调用,主要思路是:
- 用空间换时间,使用 OpenMLDB 把所有数据存储在内存或持久化内存中。在成本不够的情况下,可以考虑存储在持久化内存中。同时,避免类似 RocksDB 的写放大和读放大,也就是说,存储里没有 level 这一概念。
- 使用 SQL 作为离线和在线的桥梁。离线部分是 Spark,基于SQL语义来做数据回溯,从而做离线分析。
而在线部分针对的是时间滑窗维度的问题,是基于时序数据库做数据滑窗。
场景驱动 (OpenMLDB) 和数据驱动 (Flink CDC) 性能对比
OpenMLDB 及 Flink CDC 的测试环境及结果:
- 数据量:10 亿/天
- 取业务中一个典型场景,行为评分计算,每天的数据量能达到 10 亿条
- 除行为评分之外,大概还有三四个数据源
- OpenMLDB 硬件资源占用:3 x 256G 三节点集群
- 测试样本:一天内的窗口特征,OpenMLDB 和直接读 polarDB的延时基本相同(4 毫秒左右)
- 测试结果:两者性能基本相当
| 场景驱动 (OpenMLDB) | 数据驱动 (Flink CDC) | |
|---|---|---|
| 思路 | 现用现算,在调用时计算 | 数据变更时计算,调用和计算解耦 |
| 优点 | 1.实现简单 2.线上线下容易保持一致,回溯容易 |
1.业务调用时间与计算时间无关,业务可用性高 2. 计算结果与场景无关,一次计算,多场景调用 |
| 局限性 | 1.硬件依赖性比较高 2.维护业务稳定性比较有挑战 |
1.复杂性较高 2.线上线下逻辑不容易保持一致 3.会有大量无头的数据 |
两种计算方式在架构中的位置
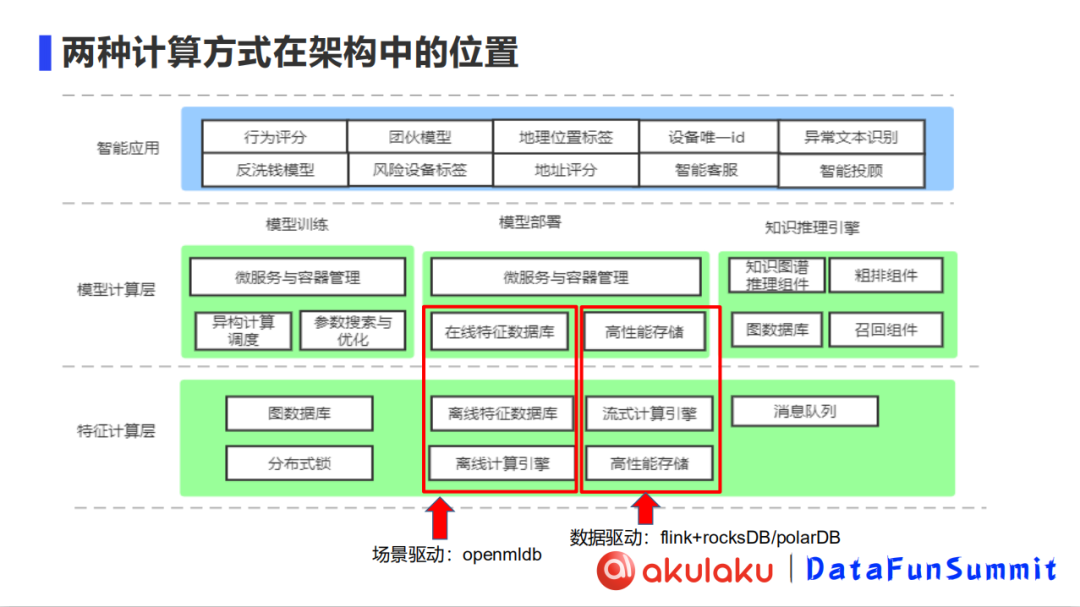
Akulaku 的特征计算层未来会向 Ray 进行一个转变,目前还是以Java 为主。数据驱动 (FLink+RocksDB+PolarDB) 在高性能存储、流式计算引擎、高性能存储的部分实现。场景驱动的部分以 OpenMLDB 为主,在架构中跨模型计算层和特征计算层。在线部分基于 OpenMLDB 的在线特征数据库。离线部分则基于OpenMLDB 的离线特征数据库和离线计算引擎 (OpenMLDB Spark Distribution)。








