

本文转载自李喆,原文:李喆:OpenMLDB/FEDB 论文阅读笔记。
Paper: Optimizing In-memory Database Engine for AI-powered On-line Decision Augmentation Using Persistent Memory (VLDB 2021, 4paradigm, NUS, Intel)
OpenMLDB (论文内称为FEDB)是第四范式的一个开源 in memory feature database(在我还在港科读书的时候就蛮看好这个公司的,当时港科计算机系主任杨强还过去这边做了顾问吧,没想到这么多年换了个赛道今天又碰上了,扯远了...)。其在一个 典型的 AI 系统中的位置如下图。为哈要专门搞一个 feature database 呢?论文里提到的主要原因是解决 online feature extraction 速度太慢的问题(下面细说),github page 上给出了更多工程上的 feature,如特征存储、特征计算、特征上线、特征共享、特征服务等,同时满足产品级需求(如低延迟、高并发、灾备、高可用、扩缩容、平滑升级、可监控等)并使用 SQL进行操作。这让特征设计者可以专注于设计上,而不被工程效率上的事所烦扰。
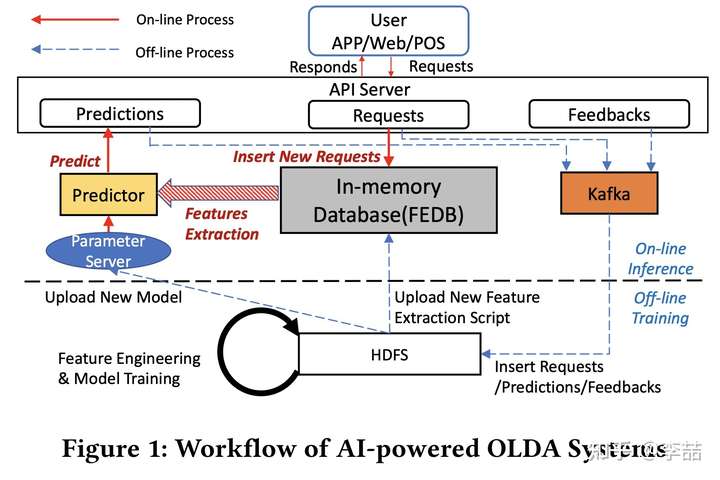
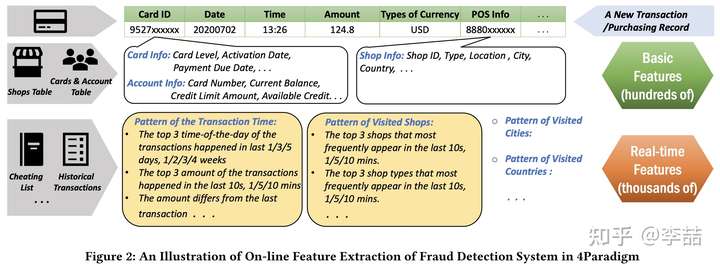
为哈说 online feature extraction 会慢呢?首先要搞懂啥是 online feature extraction,用他们给的 fraud detection 例子来说:每次信用卡刷卡的时候,要在10ms 内判断是不是 fraud。刷卡本身会产生一个 transaction,这里面有一些基本的 feature(几百个),但是还有很多 real-time feature(几千个)是要靠查询获取的,并且也是只能在刷卡的时候才能获取,比如刷卡前一段时间访问前三的商店,以及购物最频繁的时间点等等。这个 “刷卡前一段时间“ 被称为一个 time window,我们可以设置 window 的宽度,比如 几分钟,几小时,几天等,这样的 time window 越多,获取的 features 越多,最后 fraud detection 的 accuracy 也越准确。可以看出,这些 feature 的获取的确是比较耗时的,如果 online application 对时间比较敏感,则 feature extraction 的时间可能难以接受。
并且这种 one insert followed by multiple aggregate query 的 OLDA pattern,不太符合 OLTP,OLAP,Time series database 的典型 workload。
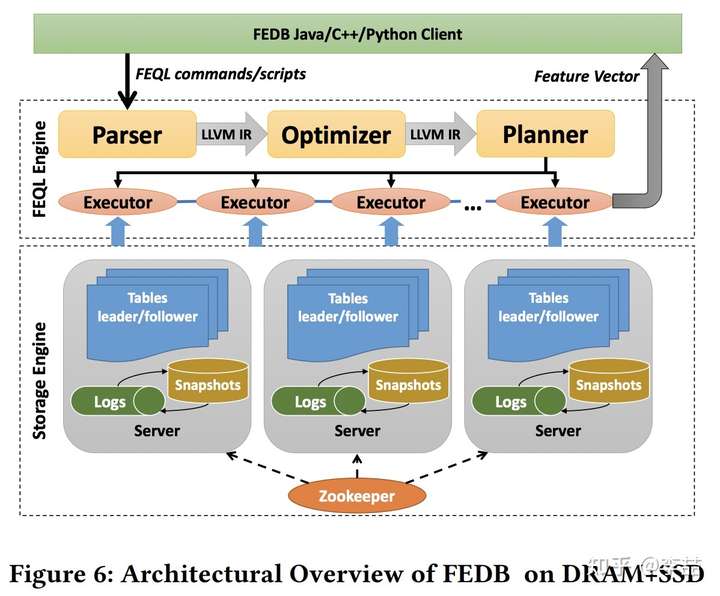
那么要解决这个问题,FEDB 是怎么设计的呢?先来看哈 FEDB 的总体架构:他们为 feature extraction 专门设计了一个 SQL-like language called FEQL (Feature Extraction Query Language),这可以让用户一次定义多个 time window 而不用分多次执行。这个 EFQL 使用 llvm 进行解析优化编译。交给 executor 后,会使用一个 双层跳表 的数据结构来加速 multiple time window 内的 TopN query。下层的存储引擎层是比较典型的高可用架构。
下面来说哈这个双层跳表 (double-layered skiplist),如下图,其实就是做了个二级分区,第一层以 key 分区,第二层以 timestamp 分区。
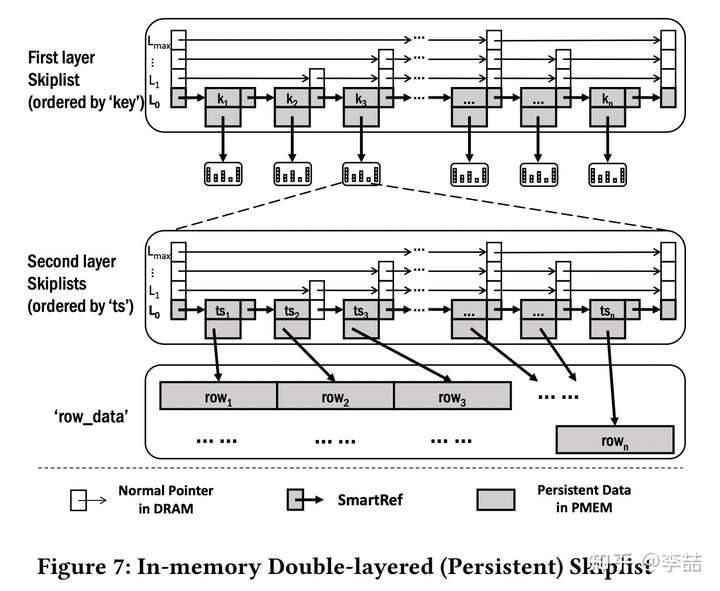
作为优化,EFDB 也可以使用 PMEM(persistent memory)来实现双层跳表。主要解决两个问题并作出一些优化:1. 内存分配/回收问题(防止system failure 时内存泄漏) 2. 数据一致性问题(也是在 system failure 后) 对于第一个问题,作者使用了 Intel 提供的 PMDK and libpmemobj-cpp 来申请/回收物理内存,并对申请好的维护了一个池子来构建跳表,这样就不会影响 performance。对于第二个,EFDB 用了 pointer 的最后4个空位来标记是否是 dirty/delete,如果是dirty,并且要读的话,要先 flush 它。








