

一、背景
OpenMLDB 线上计算的最大优势为可以低延迟(毫秒级)高效处理实时特征计算请求。其中,为了达到低延迟,OpenMLDB 默认使用了基于内存的存储引擎。但是,当业务增长时,对于内存资源消耗以及访问吞吐需求的压力也会上升。本篇文章主要介绍基于 内存存储引擎 的资源预估(磁盘引擎见最后的说明),可以帮你更好的预估、配置用于部署 OpenMLDB 的机器资源。
二、模型概览
2.1 参数说明
为了方便表述,我们先把所有使用到的参数符号以及含义汇总在以下表格。

表一:预估模型所使用的的符号和意义
2.2 概览
OpenMLDB 的资源瓶颈一般会是在内存消耗和吞吐能力上,因此本篇文章重点介绍这两个资源的预估,在最后对其他资源做一个简单介绍:
-
内存消耗:内存是一般情况下 OpenMLDB 的资源瓶颈。
-
吞吐能力:每台机器的吞吐能力有限(在内存不是资源瓶颈的前提下,一般 CPU 会是吞吐能力的瓶颈),如果业务增长需求更多的吞吐,则需要进行水平扩容,增加机器数量。
简单期间,在水平扩容下,我们假设所有机器的配置都是一样旳(如不一样原理类似)。因此,可以使用如下公式来估算针对某一场景所需要的机器台数 n:
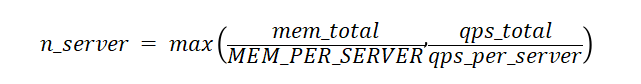
我们可以看到,由于 MEM_PER_SERVER 为一个常数,因此整个模型中最重要的是估算出内存消耗总量 mem_total,以及吞吐能力 qps_total 和 qps_per_server,以下我们分别介绍。
三、内存预估模型
在绝大多数的情况下,内存消耗会是资源的瓶颈(而非吞吐),我们首先来看内存消耗预估。我们提供一基于经验的快速预估模型,以及一个较为复杂的分析型模型。
3.1 内存预估经验模型
我们首先给出一个基于经验预估的模型。该模型适用于对数据规模和业务场景还没有明确需求的前提下,想大致预估一下内存占用的场景。对于大部分的时序数据场景,该公式可以预估内存消耗最多部分。即实际的内存消耗一般会略高于预估值。如果想得到较为准确的预估,请参考后面 3.2 章节的分析模型。
基于表一的符号定义,该经验模型表示如下:
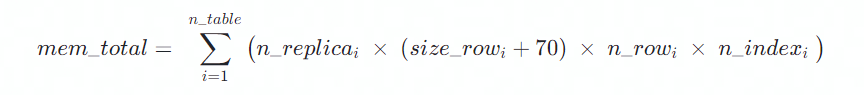
可以看到,该公式主要和数据 schema,数据规模,以及索引个数有关。如果索引个数如果较难预估,基本上可以按照经验认为,在普遍情况下,主表的索引在三个左右,每张副表有一个索引 。
3.2 内存预估分析型模型
内存消耗也可以基于实现原理分析出发,进行较为准确的预测。但是该预测需要较多的信息,计算过程也较为复杂,在没有深入使用之前较难操作。适合于上线生产环境之前,需要对资源做精细化估算使用。
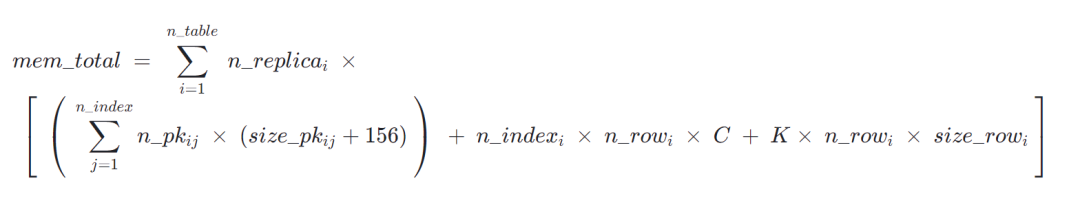 该分析模型涉及到了两个额外的参数
该分析模型涉及到了两个额外的参数
-
C:该参数对于不同类型的表格取值不同。如果是 latest 和 absorlat 表,取值为 70;如果对于 absolute 表以及 absandlat 表,取值为 74。不同表格和 TTL 设置有关,见说明 https://openmldb.ai/docs/zh/main/reference/sql/ddl/CREATE_TABLE_STATEMENT.html#columnindex 注意,这里 C 的取值 70 和 74,是两个和编码格式有关的 overhead,其实也是预估值。精确值的计算方式较为复杂,并且在不同场景下也会有所区别,在这里不做展开描述。
-
K: 如果不同索引的数据落在同一节点和分片下, 他们会共享数据(但是这个概率不大)。因此 K 代表了真实存放的数据份数,其可能的取值范围为 [1, n_index]
注意,这个模型假设基于内存存储引擎(磁盘存储引擎说明见本文最后),没有打开预聚合功能下的消耗。如果打开了预聚合,会有额外的少量内存消耗,相比较于上述的主体消耗基本可以忽略不计。
四、吞吐预估模型
虽然大部分情况下内存会是瓶颈,在某些高并发场景下,吞吐也可能成为资源瓶颈。
首先,对于吞吐的需求 qps_total,该参数取决于业务使用方,不在这里做展开。
对于每台机器提供的吞吐能力(qps_per_server),由于吞吐会和机器配置、数据集、SQL 复杂程度、以及延迟要求强相关,较难通过分析的方式给出。以下建议两种预估方式:
-
实测肯定是较为准确的预估方式,但是在项目初期较难实施
-
可以通过我们的性能报告 实时引擎性能测试报告(第一版) ,进行经验预估。该测试使用了三台机器,其基准测试得到在 TP999 < 10ms 以内的延迟下,折算成单台 QPS 在 8,000 左右,因此可以使用其作为参考值 qps_per_server=8,000
五、其他资源预估
5.1 磁盘空间
对于内存存储引擎来说,虽然索引和数据存放于内存,但是其 binlog 以及 snapshot 依然需要存放在磁盘。磁盘空间占用会和数据量有关,一般推荐配置为内存预估值的 三倍。
5.2 CPU
CPU 资源主要和吞吐能力相关。绝大部分情况,资源瓶颈在内存消耗,CPU 并不会成为瓶颈。只有在少数情况下 CPU 可能会成为瓶颈,比如窗口数据量巨大(百万级别)并且无法使用预聚合优化、或者业务对于 QPS 需求极高。在这些情况下,需要进行水平扩容。
5.3 网络带宽
OpenMLDB 一般情况下并不是一个网络 IO 密集型的程序,对于网络没有特别要求。普通 10Gbps 网络带宽应该足够满足条件。
5.4 磁盘存储引擎
到此为止,我们讨论的都是基于默认的内存存储引擎。如果是基于磁盘存储引擎(HDD 或者 SSD),则对于内存的压力较小,磁盘需要的空间数量大概是本文预估的内存消耗量的 2-3 倍。








