

人工智能工程化落地的关键点之一,在于解决真实业务场景的实时批量预估和实时模型更新问题。更好更快的将线上实时数据转化为AI可用的特征,将加速AI应用落地的效率及效果。为此,OpenMLDB 和 Apache Pulsar 合作推出OpenMLDB Pulsar Connector,实现稳定的流式集成,为高效打通实时数据到特征工程提供一条值得期待的清晰路径。
关于OpenMLDB
OpenMLDB 是一个开源机器学习数据库,致力于闭环解决 AI 工程化落地的数据治理难题。自 2021 年 6 月开源以来,OpenMLDB 优先开源了特征数据治理能力,依托 SQL 的开发能力,为企业提供全栈功能的、低门槛特征数据计算和管理平台。
OpenMLDB 包含 Feature Store 的全部功能,并且提供更为完整的 FeatureOps 全栈方案。除了提供特征存储功能,还具有基于 SQL 的低门槛数据库开发体验、面向特征计算优化的 OpenMLDB Spark 发行版,针对实时特征计算优化的索引结构,特征上线服务、企业级运维和管理等功能,让特征工程开发回归于本质——专注于高质量的特征计算脚本开发,不再被工程化效率落地所羁绊。
关于OpenMLDB
OpenMLDB 是一个开源机器学习数据库,致力于闭环解决 AI 工程化落地的数据治理难题。自 2021 年 6 月开源以来,OpenMLDB 优先开源了特征数据治理能力,依托 SQL 的开发能力,为企业提供全栈功能的、低门槛特征数据计算和管理平台。
OpenMLDB 包含 Feature Store 的全部功能,并且提供更为完整的 FeatureOps 全栈方案。除了提供特征存储功能,还具有基于 SQL 的低门槛数据库开发体验、面向特征计算优化的 OpenMLDB Spark 发行版,针对实时特征计算优化的索引结构,特征上线服务、企业级运维和管理等功能,让特征工程开发回归于本质——专注于高质量的特征计算脚本开发,不再被工程化效率落地所羁绊。
关于Apache Pulsar
Apache Pulsar 是下一代云原生消息流平台,在 2018 年 9 月毕业成为 Apache 软件基金会顶级项目。从 2012 年诞生时,Apache Pulsar 就前瞻性地采用了存储计算分离、分层分片的云原生架构,极大减轻用户在消息系统中遇到的扩展和运维困难。
Pulsar 通过特别的设计和抽象,统一地支持 Stream 和 Queue 两种消息消费模式,保持了 Stream 模式的高性能和 Queue 模式的灵活性。Pulsar 在保证大数据消息系统的性能和吞吐量的同时,提供了更多企业级的 Feature,包括方便的运维和扩展、灵活的消息模型、多语言 API、多租户、异地多备、数据的强持久性一致性等等,解决了现有开源消息系统的很多不足之处。同时,这种设计对容器非常友好,使得 Pulsar 成为流原生平台的理想选择。
OpenMLDB-Pulsar Connector
【Connector概述】
- 定位
OpenMLDB Pulsar Connector,高效打通实时数据到特征工程,大幅提升数据使用效率、助力开发者构建实时数据管道、使企业更专注和更高效的探索数据的商业价值。
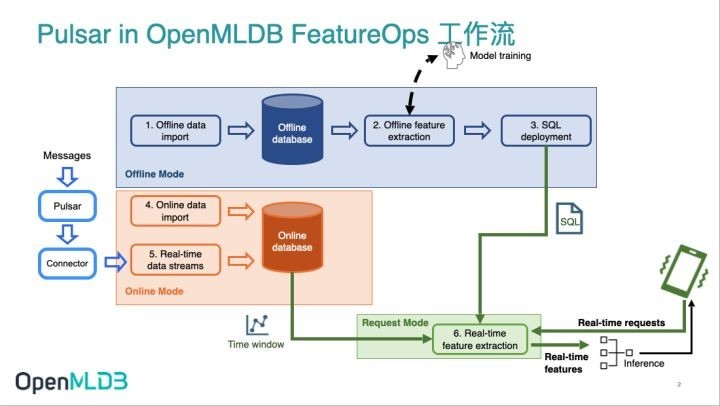
在 Pulsar in OpenMLDB 的工作流中,Connector(位置如下图所示)帮助开发者轻松地将消息系统 Pulsar 与开源机器学习数据库 OpenMLDB 结合使用,面向机器学习发挥出 Pulsar 最强大的实时价值。
 2、功能
2、功能
- Pulsar 可以使用 connector 来连接其他系统。Source connector 可以使其他系统的数据流入 Pulsar,sink connector 可以将消息流出至其他系统。
- 可以通过 Connector Admin CLI 并结合 sources 和 sinks 子命令来管理 Pulsar connector(例如,创建、更新、启动、停止、重启、重载、删除以及其他操作)。
- JDBC OpenMLDB Connector 支持了 sink 功能,使 Pulsar 消息可以写入到 OpenMLDB 在线存储中。
3、优势
为了使 OpenMLDB 与 Pulsar 拥有稳定的流式集成,OpenMLDB connector 具备诸多优势,包括但不限于:
- 易上手。无需编写任何代码,只需进行简单配置,便可通过 OpenMLDB Pulsar Connector 将 Pulsar 的消息流入 OpenMLDB 。简化的数据导入过程能大幅提升企业的数据使用效率。
- 易扩展。根据不同的业务需求,可以选择在单机或集群上运行 OpenMLDB Pulsar Connector,助力企业构建实时数据管道。
- 可持续。OpenMLDB Pulsar Connector 简单的安装和部署过程,使企业能更专注和更高效地探索数据的商业价值。
4、Connector 下载地址
OpenMLDB Pulsar:
Connectorhttps://github.com/4paradigm/OpenMLDB/releases/download/v0.4.4/pulsar-io-jdbc-openmldb-2.11.0-SNAPSHOT.nar
【Connector演示】
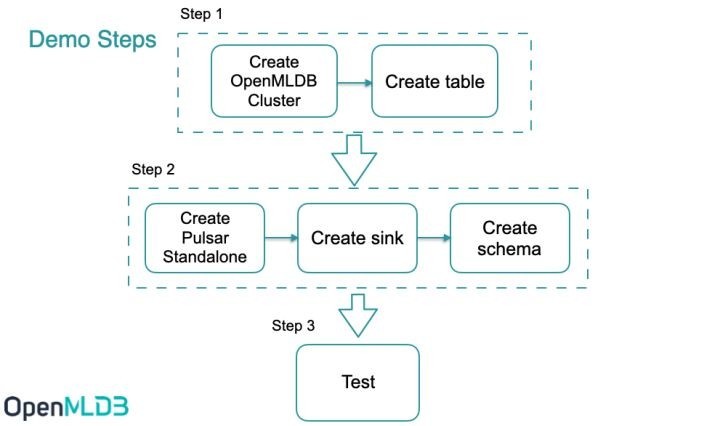
1、流程介绍
- 创建 connector 前需要启动 OpenMLDB 集群,并创建表。
- 创建 Pulsar standalone,创建 sink,sink 配置中使用 OpenMLDB 集群的 JDBC 地址。并且,创建用于解析消息的 schema。
- 向 Pulsar 发送消息,来测试消息是否能自动写入到 OpenMLDB。
2、关键步骤
以下仅列出使用此 connector 的关键步骤,详细说明文档请参考 Pulsar OpenMLDB Connector 使用
步骤1 | 启动 OpenMLDB 并创建表
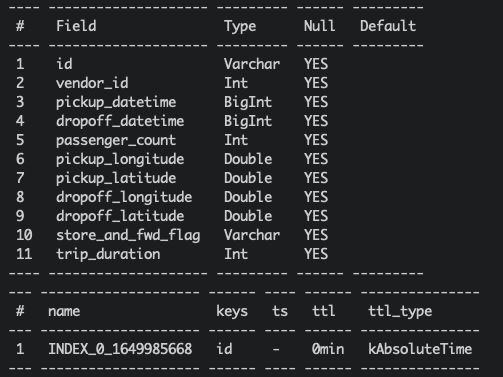
使用 docker 或本地启动 OpenMLDB 集群,并创建表,作为 connector 导入的地址。如图所示,在 pulsar_test 数据库中,创建了 schema 和taxi trip demo 一致的表 connector_test。
 步骤2 | 启动 Pulsar,创建 sink 和 schema
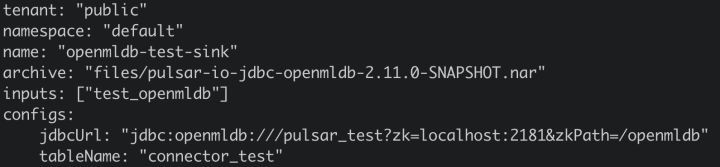
启动 Pulsar Standalone 成功后,即可使用 connector 创建一个 sink,connector 如果预先装载进入 Pulsar,可以使用"jdbc-openmldb"的 sink type,或是使用"archive"指定 connector nar 文件路径。演示中使用后者来创建。创建sink的配置中还需指定 OpenMLDB 的表地址,所以配置情况如下:
步骤2 | 启动 Pulsar,创建 sink 和 schema
启动 Pulsar Standalone 成功后,即可使用 connector 创建一个 sink,connector 如果预先装载进入 Pulsar,可以使用"jdbc-openmldb"的 sink type,或是使用"archive"指定 connector nar 文件路径。演示中使用后者来创建。创建sink的配置中还需指定 OpenMLDB 的表地址,所以配置情况如下:
 由于 OpenMLDB 表数据是有schema的,所以还需要在 pulsar 中为"test_openmldb"配置好 schema,才可以顺利将消息解析为符合O penMLDB schema 的数据并插入。
我们为"test_openmldb"配置 JSON Schema,各列和 OpenMLDB 的列属性一致。配置文件如下:
由于 OpenMLDB 表数据是有schema的,所以还需要在 pulsar 中为"test_openmldb"配置好 schema,才可以顺利将消息解析为符合O penMLDB schema 的数据并插入。
我们为"test_openmldb"配置 JSON Schema,各列和 OpenMLDB 的列属性一致。配置文件如下:
 sink 和 schema 均创建完成后,只要向 topic "test_openmldb"(sink 配置图的"inputs"配置项)发送消息,就会自动写入到 OpenMLDB 集群。
步骤3 | 测试
前两步完成后,就可以进行测试了。测试用 Producer 关键代码如下:
sink 和 schema 均创建完成后,只要向 topic "test_openmldb"(sink 配置图的"inputs"配置项)发送消息,就会自动写入到 OpenMLDB 集群。
步骤3 | 测试
前两步完成后,就可以进行测试了。测试用 Producer 关键代码如下:
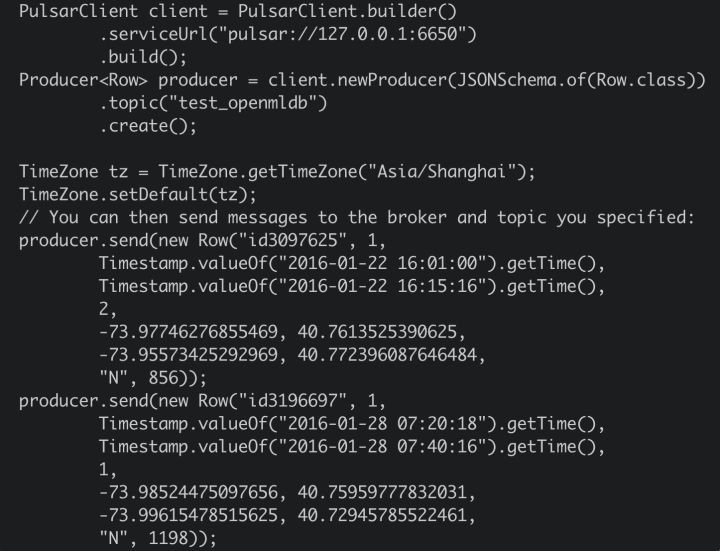 我们用 Producer 程序向 Pulsar 写入两条 JSON Messages。然后,我们可以在 OpenMLDB 在线存储中查询到这两条数据。这说明了,connector 运行正常,可以将流入 Pulsar 的消息自动 sink 到 OpenMLDB 在线存储中。
我们用 Producer 程序向 Pulsar 写入两条 JSON Messages。然后,我们可以在 OpenMLDB 在线存储中查询到这两条数据。这说明了,connector 运行正常,可以将流入 Pulsar 的消息自动 sink 到 OpenMLDB 在线存储中。

写在最后
OpenMLDB 上下游生态体系
为更好降低开发者使用 OpenMLDB 的门槛,OpenMLDB 社区将持续打造面向上下游技术组件的生态圈,为开发者提供更多简单易用的生态 Connector(如下图所示):
- 面向线上数据生态,如 Kafka,Flink,RabbitMQ,RocketMQ等
- 面向离线数据生态,如 HDFS,HBase,Cassandra,S3等
- 面向模型构建的算法、框架,如 XGBoost,LightGBM,TensorFlow,PyTorch,Scikit Learn等
- 面向机器学习建模全流程的调度框架、部署工具,如 Airflow,Kubeflow,DolphinScheduler,Prometheus,Grafana 等
OpenMLDB Roadmap
v0.5.0
OpenMLDB社区将于4月底发布v0.5.0版本([DEV] OpenMLDB v0.5 Roadmap · Issue #1506 · 4paradigm/OpenMLDB · GitHub ),届时OpenMLDB将具备新特性如下:
- 窗口预聚合技术,指数级提升长窗口聚合性能
- 完善的监控, trace, 和 profiling 能力,在企业级应用环境中大幅提升稳定性、可观测性、和可分析性
- 线上存储引擎可插拔以适配不同业务需求,既可以支持基于内存的高性能存储引擎,也可以支持基于外存的大容量低成本存储引擎,还可以支持基于持久内存的存储引擎以在性能和成本间保持平衡
- 用户自定义函数(UDF)支持,大幅提升易用性和适用性
- 上下游数据源生态整合,提供线上数据源的 Kafka, Pulsar connectors
AI 的进步需要付出多方面的努力,而开放式协作是其中的关键环节,我们期待来自开发者的贡献。欢迎大家加入 OpenMLDB 社区,扫描下方二维码可加入社区技术交流微信群。
 或可官网社区板块最下方找到入群通道 https://openmldb.ai/community/
或可官网社区板块最下方找到入群通道 https://openmldb.ai/community/
相关阅读
https://github.com/4paradigm/OpenMLDB/issues/1506
(OpenMLDB Pulsar Connector)
https://openmldb.ai/docs/zh/v0.4/about/index.html
(OpenMLDB文档)
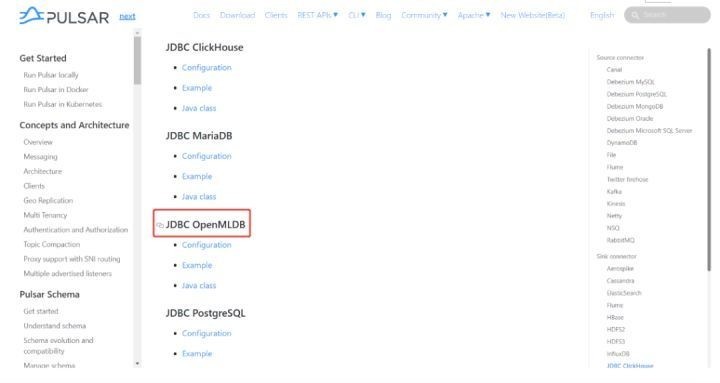
Built-in connector · Apache Pulsar
(Apache Pulsar connector文档,OpenMLDB Pulsar Connector位置如图所示)
OpenMLDB-Pulsar Connector
【Connector概述】
- 定位
OpenMLDB Pulsar Connector,高效打通实时数据到特征工程,大幅提升数据使用效率、助力开发者构建实时数据管道、使企业更专注和更高效的探索数据的商业价值。
在 Pulsar in OpenMLDB 的工作流中,Connector(位置如下图所示)帮助开发者轻松地将消息系统 Pulsar 与开源机器学习数据库 OpenMLDB 结合使用,面向机器学习发挥出 Pulsar 最强大的实时价值。
2、功能
- Pulsar 可以使用 connector 来连接其他系统。Source connector 可以使其他系统的数据流入 Pulsar,sink connector 可以将消息流出至其他系统。
- 可以通过 Connector Admin CLI 并结合 sources 和 sinks 子命令来管理 Pulsar connector(例如,创建、更新、启动、停止、重启、重载、删除以及其他操作)。
- JDBC OpenMLDB Connector 支持了 sink 功能,使 Pulsar 消息可以写入到 OpenMLDB 在线存储中。
3、优势
为了使 OpenMLDB 与 Pulsar 拥有稳定的流式集成,OpenMLDB connector 具备诸多优势,包括但不限于:
- 易上手。无需编写任何代码,只需进行简单配置,便可通过 OpenMLDB Pulsar Connector 将 Pulsar 的消息流入 OpenMLDB 。简化的数据导入过程能大幅提升企业的数据使用效率。
- 易扩展。根据不同的业务需求,可以选择在单机或集群上运行 OpenMLDB Pulsar Connector,助力企业构建实时数据管道。
- 可持续。OpenMLDB Pulsar Connector 简单的安装和部署过程,使企业能更专注和更高效地探索数据的商业价值。
4、Connector 下载地址
OpenMLDB Pulsar:
Connectorhttps://github.com/4paradigm/OpenMLDB/releases/download/v0.4.4/pulsar-io-jdbc-openmldb-2.11.0-SNAPSHOT.nar
【Connector演示】
1、流程介绍
- 创建 connector 前需要启动 OpenMLDB 集群,并创建表。
- 创建 Pulsar standalone,创建 sink,sink 配置中使用 OpenMLDB 集群的 JDBC 地址。并且,创建用于解析消息的 schema。
- 向 Pulsar 发送消息,来测试消息是否能自动写入到 OpenMLDB。
2、关键步骤
以下仅列出使用此 connector 的关键步骤,详细说明文档请参考 Pulsar OpenMLDB Connector 使用
步骤1 | 启动 OpenMLDB 并创建表
使用 docker 或本地启动 OpenMLDB 集群,并创建表,作为 connector 导入的地址。如图所示,在 pulsar_test 数据库中,创建了 schema 和taxi trip demo 一致的表 connector_test。
步骤2 | 启动 Pulsar,创建 sink 和 schema
启动 Pulsar Standalone 成功后,即可使用 connector 创建一个 sink,connector 如果预先装载进入 Pulsar,可以使用"jdbc-openmldb"的 sink type,或是使用"archive"指定 connector nar 文件路径。演示中使用后者来创建。创建sink的配置中还需指定 OpenMLDB 的表地址,所以配置情况如下:
由于 OpenMLDB 表数据是有schema的,所以还需要在 pulsar 中为"test_openmldb"配置好 schema,才可以顺利将消息解析为符合O penMLDB schema 的数据并插入。
我们为"test_openmldb"配置 JSON Schema,各列和 OpenMLDB 的列属性一致。配置文件如下:
sink 和 schema 均创建完成后,只要向 topic "test_openmldb"(sink 配置图的"inputs"配置项)发送消息,就会自动写入到 OpenMLDB 集群。
步骤3 | 测试
前两步完成后,就可以进行测试了。测试用 Producer 关键代码如下:
我们用 Producer 程序向 Pulsar 写入两条 JSON Messages。然后,我们可以在 OpenMLDB 在线存储中查询到这两条数据。这说明了,connector 运行正常,可以将流入 Pulsar 的消息自动 sink 到 OpenMLDB 在线存储中。
写在最后
OpenMLDB 上下游生态体系
为更好降低开发者使用 OpenMLDB 的门槛,OpenMLDB 社区将持续打造面向上下游技术组件的生态圈,为开发者提供更多简单易用的生态 Connector(如下图所示):
- 面向线上数据生态,如 Kafka,Flink,RabbitMQ,RocketMQ等
- 面向离线数据生态,如 HDFS,HBase,Cassandra,S3等
- 面向模型构建的算法、框架,如 XGBoost,LightGBM,TensorFlow,PyTorch,Scikit Learn等
- 面向机器学习建模全流程的调度框架、部署工具,如 Airflow,Kubeflow,DolphinScheduler,Prometheus,Grafana 等
OpenMLDB Roadmap
v0.5.0
OpenMLDB社区将于4月底发布v0.5.0版本([DEV] OpenMLDB v0.5 Roadmap · Issue #1506 · 4paradigm/OpenMLDB · GitHub ),届时OpenMLDB将具备新特性如下:
- 窗口预聚合技术,指数级提升长窗口聚合性能
- 完善的监控, trace, 和 profiling 能力,在企业级应用环境中大幅提升稳定性、可观测性、和可分析性
- 线上存储引擎可插拔以适配不同业务需求,既可以支持基于内存的高性能存储引擎,也可以支持基于外存的大容量低成本存储引擎,还可以支持基于持久内存的存储引擎以在性能和成本间保持平衡
- 用户自定义函数(UDF)支持,大幅提升易用性和适用性
- 上下游数据源生态整合,提供线上数据源的 Kafka, Pulsar connectors
AI 的进步需要付出多方面的努力,而开放式协作是其中的关键环节,我们期待来自开发者的贡献。欢迎大家加入 OpenMLDB 社区,扫描下方二维码可加入社区技术交流微信群。
或可官网社区板块最下方找到入群通道 https://openmldb.ai/community/
相关阅读
https://github.com/4paradigm/OpenMLDB/issues/1506
(OpenMLDB Pulsar Connector)
https://openmldb.ai/docs/zh/v0.4/about/index.html
(OpenMLDB文档)
Built-in connector · Apache Pulsar
(Apache Pulsar connector文档,OpenMLDB Pulsar Connector位置如图所示)
- 定位
2、功能
- Pulsar 可以使用 connector 来连接其他系统。Source connector 可以使其他系统的数据流入 Pulsar,sink connector 可以将消息流出至其他系统。
- 可以通过 Connector Admin CLI 并结合 sources 和 sinks 子命令来管理 Pulsar connector(例如,创建、更新、启动、停止、重启、重载、删除以及其他操作)。
- JDBC OpenMLDB Connector 支持了 sink 功能,使 Pulsar 消息可以写入到 OpenMLDB 在线存储中。
- 易上手。无需编写任何代码,只需进行简单配置,便可通过 OpenMLDB Pulsar Connector 将 Pulsar 的消息流入 OpenMLDB 。简化的数据导入过程能大幅提升企业的数据使用效率。
- 易扩展。根据不同的业务需求,可以选择在单机或集群上运行 OpenMLDB Pulsar Connector,助力企业构建实时数据管道。
- 可持续。OpenMLDB Pulsar Connector 简单的安装和部署过程,使企业能更专注和更高效地探索数据的商业价值。
【Connector演示】
1、流程介绍
- 创建 connector 前需要启动 OpenMLDB 集群,并创建表。
- 创建 Pulsar standalone,创建 sink,sink 配置中使用 OpenMLDB 集群的 JDBC 地址。并且,创建用于解析消息的 schema。
- 向 Pulsar 发送消息,来测试消息是否能自动写入到 OpenMLDB。
2、关键步骤
以下仅列出使用此 connector 的关键步骤,详细说明文档请参考 Pulsar OpenMLDB Connector 使用
步骤1 | 启动 OpenMLDB 并创建表
使用 docker 或本地启动 OpenMLDB 集群,并创建表,作为 connector 导入的地址。如图所示,在 pulsar_test 数据库中,创建了 schema 和taxi trip demo 一致的表 connector_test。
步骤2 | 启动 Pulsar,创建 sink 和 schema
启动 Pulsar Standalone 成功后,即可使用 connector 创建一个 sink,connector 如果预先装载进入 Pulsar,可以使用"jdbc-openmldb"的 sink type,或是使用"archive"指定 connector nar 文件路径。演示中使用后者来创建。创建sink的配置中还需指定 OpenMLDB 的表地址,所以配置情况如下:
由于 OpenMLDB 表数据是有schema的,所以还需要在 pulsar 中为"test_openmldb"配置好 schema,才可以顺利将消息解析为符合O penMLDB schema 的数据并插入。
我们为"test_openmldb"配置 JSON Schema,各列和 OpenMLDB 的列属性一致。配置文件如下:
sink 和 schema 均创建完成后,只要向 topic "test_openmldb"(sink 配置图的"inputs"配置项)发送消息,就会自动写入到 OpenMLDB 集群。
步骤3 | 测试
前两步完成后,就可以进行测试了。测试用 Producer 关键代码如下:
我们用 Producer 程序向 Pulsar 写入两条 JSON Messages。然后,我们可以在 OpenMLDB 在线存储中查询到这两条数据。这说明了,connector 运行正常,可以将流入 Pulsar 的消息自动 sink 到 OpenMLDB 在线存储中。
写在最后
OpenMLDB 上下游生态体系
为更好降低开发者使用 OpenMLDB 的门槛,OpenMLDB 社区将持续打造面向上下游技术组件的生态圈,为开发者提供更多简单易用的生态 Connector(如下图所示):
- 面向线上数据生态,如 Kafka,Flink,RabbitMQ,RocketMQ等
- 面向离线数据生态,如 HDFS,HBase,Cassandra,S3等
- 面向模型构建的算法、框架,如 XGBoost,LightGBM,TensorFlow,PyTorch,Scikit Learn等
- 面向机器学习建模全流程的调度框架、部署工具,如 Airflow,Kubeflow,DolphinScheduler,Prometheus,Grafana 等
OpenMLDB Roadmap
v0.5.0
OpenMLDB社区将于4月底发布v0.5.0版本([DEV] OpenMLDB v0.5 Roadmap · Issue #1506 · 4paradigm/OpenMLDB · GitHub ),届时OpenMLDB将具备新特性如下:
- 窗口预聚合技术,指数级提升长窗口聚合性能
- 完善的监控, trace, 和 profiling 能力,在企业级应用环境中大幅提升稳定性、可观测性、和可分析性
- 线上存储引擎可插拔以适配不同业务需求,既可以支持基于内存的高性能存储引擎,也可以支持基于外存的大容量低成本存储引擎,还可以支持基于持久内存的存储引擎以在性能和成本间保持平衡
- 用户自定义函数(UDF)支持,大幅提升易用性和适用性
- 上下游数据源生态整合,提供线上数据源的 Kafka, Pulsar connectors
AI 的进步需要付出多方面的努力,而开放式协作是其中的关键环节,我们期待来自开发者的贡献。欢迎大家加入 OpenMLDB 社区,扫描下方二维码可加入社区技术交流微信群。
或可官网社区板块最下方找到入群通道 https://openmldb.ai/community/
相关阅读
https://github.com/4paradigm/OpenMLDB/issues/1506
(OpenMLDB Pulsar Connector)
https://openmldb.ai/docs/zh/v0.4/about/index.html
(OpenMLDB文档)
Built-in connector · Apache Pulsar
(Apache Pulsar connector文档,OpenMLDB Pulsar Connector位置如图所示)
- 创建 connector 前需要启动 OpenMLDB 集群,并创建表。
- 创建 Pulsar standalone,创建 sink,sink 配置中使用 OpenMLDB 集群的 JDBC 地址。并且,创建用于解析消息的 schema。
- 向 Pulsar 发送消息,来测试消息是否能自动写入到 OpenMLDB。
2、关键步骤
以下仅列出使用此 connector 的关键步骤,详细说明文档请参考 Pulsar OpenMLDB Connector 使用
步骤1 | 启动 OpenMLDB 并创建表
使用 docker 或本地启动 OpenMLDB 集群,并创建表,作为 connector 导入的地址。如图所示,在 pulsar_test 数据库中,创建了 schema 和taxi trip demo 一致的表 connector_test。
步骤2 | 启动 Pulsar,创建 sink 和 schema
启动 Pulsar Standalone 成功后,即可使用 connector 创建一个 sink,connector 如果预先装载进入 Pulsar,可以使用"jdbc-openmldb"的 sink type,或是使用"archive"指定 connector nar 文件路径。演示中使用后者来创建。创建sink的配置中还需指定 OpenMLDB 的表地址,所以配置情况如下:
由于 OpenMLDB 表数据是有schema的,所以还需要在 pulsar 中为"test_openmldb"配置好 schema,才可以顺利将消息解析为符合O penMLDB schema 的数据并插入。
我们为"test_openmldb"配置 JSON Schema,各列和 OpenMLDB 的列属性一致。配置文件如下:
sink 和 schema 均创建完成后,只要向 topic "test_openmldb"(sink 配置图的"inputs"配置项)发送消息,就会自动写入到 OpenMLDB 集群。
步骤3 | 测试
前两步完成后,就可以进行测试了。测试用 Producer 关键代码如下:
我们用 Producer 程序向 Pulsar 写入两条 JSON Messages。然后,我们可以在 OpenMLDB 在线存储中查询到这两条数据。这说明了,connector 运行正常,可以将流入 Pulsar 的消息自动 sink 到 OpenMLDB 在线存储中。
写在最后
OpenMLDB 上下游生态体系
为更好降低开发者使用 OpenMLDB 的门槛,OpenMLDB 社区将持续打造面向上下游技术组件的生态圈,为开发者提供更多简单易用的生态 Connector(如下图所示):
- 面向线上数据生态,如 Kafka,Flink,RabbitMQ,RocketMQ等
- 面向离线数据生态,如 HDFS,HBase,Cassandra,S3等
- 面向模型构建的算法、框架,如 XGBoost,LightGBM,TensorFlow,PyTorch,Scikit Learn等
- 面向机器学习建模全流程的调度框架、部署工具,如 Airflow,Kubeflow,DolphinScheduler,Prometheus,Grafana 等
OpenMLDB Roadmap
v0.5.0
OpenMLDB社区将于4月底发布v0.5.0版本([DEV] OpenMLDB v0.5 Roadmap · Issue #1506 · 4paradigm/OpenMLDB · GitHub ),届时OpenMLDB将具备新特性如下:
- 窗口预聚合技术,指数级提升长窗口聚合性能
- 完善的监控, trace, 和 profiling 能力,在企业级应用环境中大幅提升稳定性、可观测性、和可分析性
- 线上存储引擎可插拔以适配不同业务需求,既可以支持基于内存的高性能存储引擎,也可以支持基于外存的大容量低成本存储引擎,还可以支持基于持久内存的存储引擎以在性能和成本间保持平衡
- 用户自定义函数(UDF)支持,大幅提升易用性和适用性
- 上下游数据源生态整合,提供线上数据源的 Kafka, Pulsar connectors
AI 的进步需要付出多方面的努力,而开放式协作是其中的关键环节,我们期待来自开发者的贡献。欢迎大家加入 OpenMLDB 社区,扫描下方二维码可加入社区技术交流微信群。
或可官网社区板块最下方找到入群通道 https://openmldb.ai/community/
相关阅读
https://github.com/4paradigm/OpenMLDB/issues/1506
(OpenMLDB Pulsar Connector)
https://openmldb.ai/docs/zh/v0.4/about/index.html
(OpenMLDB文档)
Built-in connector · Apache Pulsar
(Apache Pulsar connector文档,OpenMLDB Pulsar Connector位置如图所示)
- 面向线上数据生态,如 Kafka,Flink,RabbitMQ,RocketMQ等
- 面向离线数据生态,如 HDFS,HBase,Cassandra,S3等
- 面向模型构建的算法、框架,如 XGBoost,LightGBM,TensorFlow,PyTorch,Scikit Learn等
- 面向机器学习建模全流程的调度框架、部署工具,如 Airflow,Kubeflow,DolphinScheduler,Prometheus,Grafana 等
OpenMLDB Roadmap
v0.5.0
OpenMLDB社区将于4月底发布v0.5.0版本([DEV] OpenMLDB v0.5 Roadmap · Issue #1506 · 4paradigm/OpenMLDB · GitHub ),届时OpenMLDB将具备新特性如下:
- 窗口预聚合技术,指数级提升长窗口聚合性能
- 完善的监控, trace, 和 profiling 能力,在企业级应用环境中大幅提升稳定性、可观测性、和可分析性
- 线上存储引擎可插拔以适配不同业务需求,既可以支持基于内存的高性能存储引擎,也可以支持基于外存的大容量低成本存储引擎,还可以支持基于持久内存的存储引擎以在性能和成本间保持平衡
- 用户自定义函数(UDF)支持,大幅提升易用性和适用性
- 上下游数据源生态整合,提供线上数据源的 Kafka, Pulsar connectors
AI 的进步需要付出多方面的努力,而开放式协作是其中的关键环节,我们期待来自开发者的贡献。欢迎大家加入 OpenMLDB 社区,扫描下方二维码可加入社区技术交流微信群。
或可官网社区板块最下方找到入群通道 https://openmldb.ai/community/
相关阅读
https://github.com/4paradigm/OpenMLDB/issues/1506
(OpenMLDB Pulsar Connector)
https://openmldb.ai/docs/zh/v0.4/about/index.html
(OpenMLDB文档)
Built-in connector · Apache Pulsar
(Apache Pulsar connector文档,OpenMLDB Pulsar Connector位置如图所示)








