

导读:在近期的 meetup 中 OpenMLDB PMC 卢冕以《OpenMLDB v0.5.0介绍:线上线下一致的生产级特征平台》为议题,从「 人工智能工程化落地的数据和特征挑战」 ,「OpenMLDB:构建线上线下一致的生产级特征平台」,「 OpenMLDB v0.5.0:性能、成本、易用性升级」三个方面介绍开源机器学习数据库 OpenMLDB。本文节选演讲中首次对外展示的 OpenMLDB v0.5.0 性能升级展示 和 OpenMLDB 应用案例介绍 部分整理而成。
OpenMLDB v0.5.0 性能升级展示:OpenMLDB v0.5.0 带来性能、成本、灵活性的重大优化升级。新版本的 OpenMLDB 在线性能数量级提升,低成本落地选择,使用场景灵活性扩展。 OpenMLDB 应用案例介绍:在特征计算系统的实现上,主打海外市场的金融科技企业Akulaku 采用场景驱动方式,通过使用 OpenMLDB,更加高效地实现特征“现用现算”。
一、OpenMLDB v0.5.0 升级展示
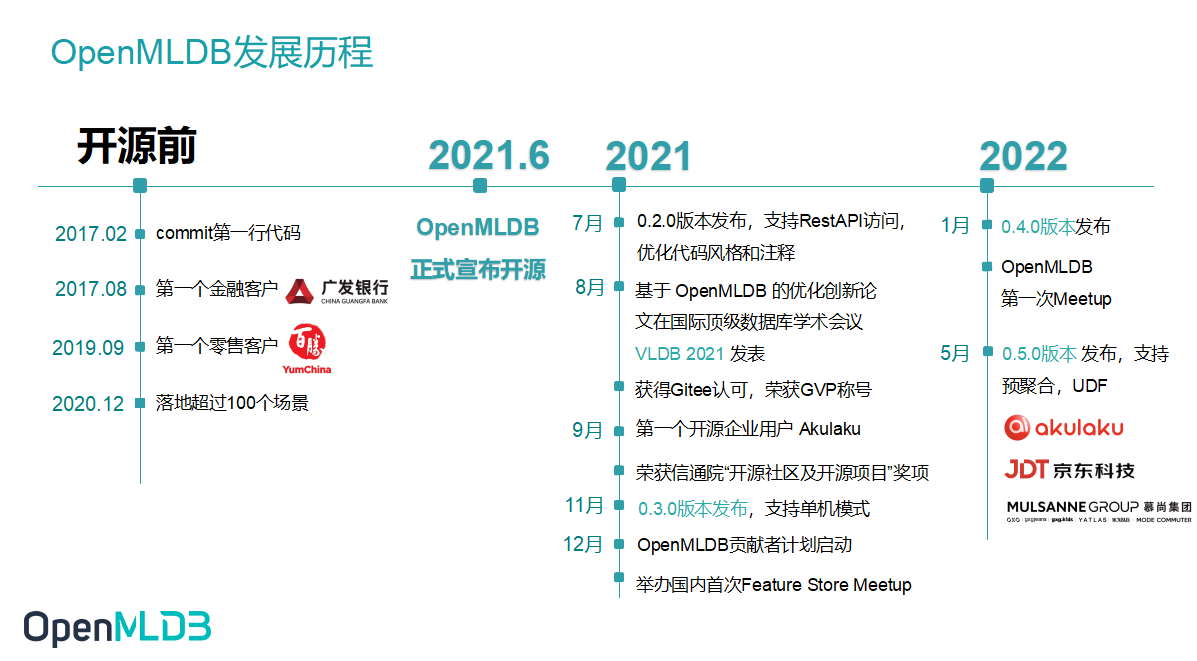 OpenMLDB 最早是第四范式先知平台中的特征平台,所以在开源之前这个产品就累积了不少应用场景。自 2021 年 6 月开源之后我们调整步调,跟随社区发展,也累积了一些社区用户,像是 Akulaku 和京东科技。从去年的 0.1.0 发展到现在的 0.5.0,OpenMLDB 也在性能上实现了多方面的升级,接下来会为大家展开做详细介绍。
OpenMLDB 最早是第四范式先知平台中的特征平台,所以在开源之前这个产品就累积了不少应用场景。自 2021 年 6 月开源之后我们调整步调,跟随社区发展,也累积了一些社区用户,像是 Akulaku 和京东科技。从去年的 0.1.0 发展到现在的 0.5.0,OpenMLDB 也在性能上实现了多方面的升级,接下来会为大家展开做详细介绍。
升级一:预聚合技术:显著提升长窗口性能
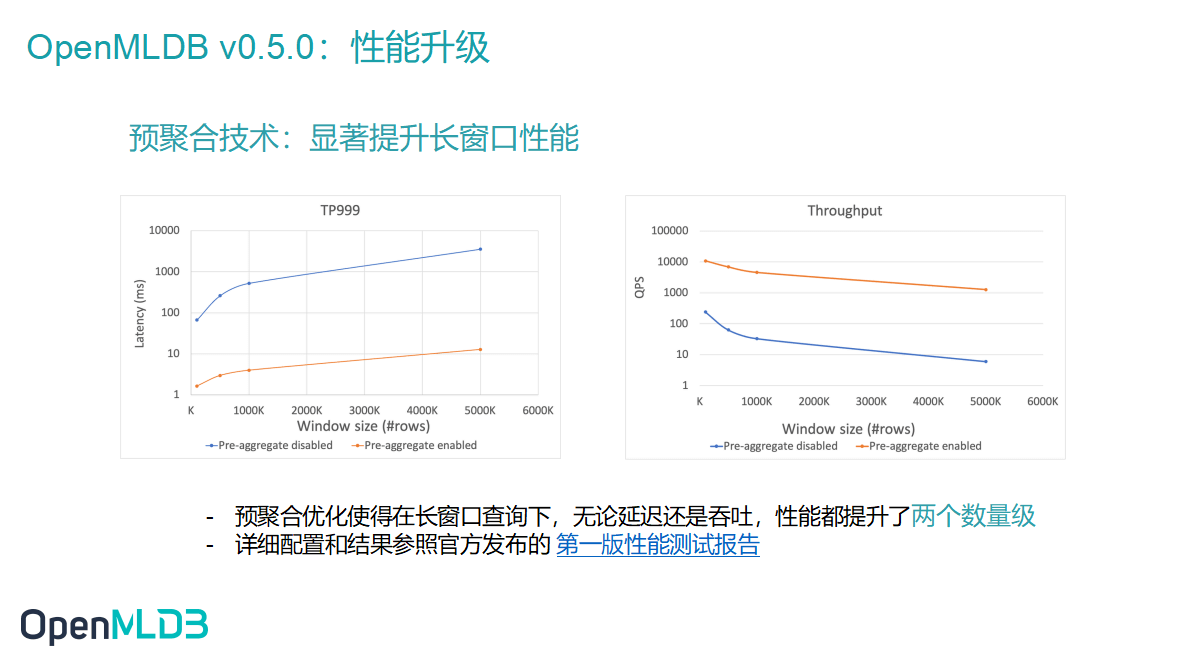 0.5.0 版本第一个重要升级就是我们把预聚合技术完整地实现了出来,对长窗口性能做到了显著提升。长窗口指的是数据行数特别多的窗口。
我们可以看到当社区用户的 workload 达到百万的级别,或者有些窗口的时间跨度比较长(可能会有两到三年的时间跨度)时,面对这种级别的窗口,实时计算延迟会像上图左侧的蓝色线的对数指标一样因为窗口内数据太多而到达秒级别。引入预聚合之后,我们可以率先把部分数据结合运算出来(比如每个月的数据先做聚合运算),而后加上最近的实时数据做计算,此时延迟会得到显著降低,可以控制在 10 毫秒,整体上看无论是延迟还是吞吐,都可以提升两个数量级的性能。更多详细的数据以及升级前后的不同参数变化可以去阅读 OpenMLDB 的性能测试报告(https://mp.weixin.qq.com/s/C4gFGwx6BnK7txPZpaCrcg)。
0.5.0 版本第一个重要升级就是我们把预聚合技术完整地实现了出来,对长窗口性能做到了显著提升。长窗口指的是数据行数特别多的窗口。
我们可以看到当社区用户的 workload 达到百万的级别,或者有些窗口的时间跨度比较长(可能会有两到三年的时间跨度)时,面对这种级别的窗口,实时计算延迟会像上图左侧的蓝色线的对数指标一样因为窗口内数据太多而到达秒级别。引入预聚合之后,我们可以率先把部分数据结合运算出来(比如每个月的数据先做聚合运算),而后加上最近的实时数据做计算,此时延迟会得到显著降低,可以控制在 10 毫秒,整体上看无论是延迟还是吞吐,都可以提升两个数量级的性能。更多详细的数据以及升级前后的不同参数变化可以去阅读 OpenMLDB 的性能测试报告(https://mp.weixin.qq.com/s/C4gFGwx6BnK7txPZpaCrcg)。
升级二:成本降低
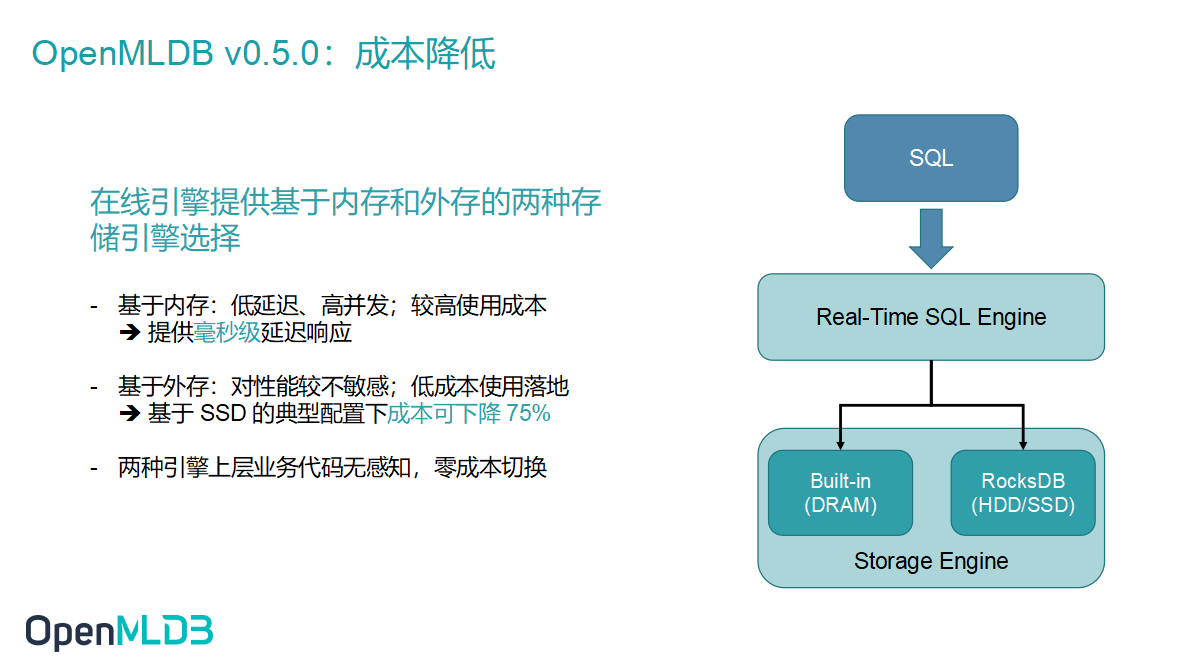 第二个升级在于成本。在 v0.5.0 中我们增加了一个很重要的特性——第二种存储引擎的选择。如上图右侧所示的 Real-Time SQL Engine,在新版本之前 OpenMLDB 只支持基于 DRAM 的存储引擎。DRAM 里面的所有数据包括索引都是储存在内存里的,是最高效的一种模式,但是对应了较高昂的成本。在我们实际落地的案例中,存在用户数据量在 10 TB 左右,如果仅仅为了满足 10 TB 的数据需求就得凑出 20 台左右的服务器增加了一些不必要的落地成本。
所以,我们提出了另一种存储方式,即基于磁盘的储存引擎。OpenMLDB 选择 RocksDB 做了对接以此节约成本。当然,选择这种方式需要面对性能上的损耗,我们初步预计是在两倍以内,稍后也会做出更详尽的性能报告。基于 SSD 的典型配置,折算后成本可下降 75%。升级后,OpenMLDB 提供给大家基于内存和外存的两种存储引擎选择,上层业务代码对于这两种方式的切换是没有感知的,切换成本为零。
第二个升级在于成本。在 v0.5.0 中我们增加了一个很重要的特性——第二种存储引擎的选择。如上图右侧所示的 Real-Time SQL Engine,在新版本之前 OpenMLDB 只支持基于 DRAM 的存储引擎。DRAM 里面的所有数据包括索引都是储存在内存里的,是最高效的一种模式,但是对应了较高昂的成本。在我们实际落地的案例中,存在用户数据量在 10 TB 左右,如果仅仅为了满足 10 TB 的数据需求就得凑出 20 台左右的服务器增加了一些不必要的落地成本。
所以,我们提出了另一种存储方式,即基于磁盘的储存引擎。OpenMLDB 选择 RocksDB 做了对接以此节约成本。当然,选择这种方式需要面对性能上的损耗,我们初步预计是在两倍以内,稍后也会做出更详尽的性能报告。基于 SSD 的典型配置,折算后成本可下降 75%。升级后,OpenMLDB 提供给大家基于内存和外存的两种存储引擎选择,上层业务代码对于这两种方式的切换是没有感知的,切换成本为零。
升级三:易用性增强
 第三个升级是 OpenMLDB 可以支持 UDF。在升级前,如果用户需要用到 OpenMLDB 不支持的聚合函数,需要通过复杂的步骤、繁琐的手续来实现——或者是开发者修改 OpenMLDB 的源代码库,增加 build-in 函数,重新编译,或者是把需要的代码 contribute 给社区 repo 才能使用。在 v0.5.0 中 OpenMLDB 可以支持 C++ UDF,后面社区会考虑其他语言的 UDF 开发。目前 OpenMLDB 支持用户自定义函数的动态注册,如右图所示,用户可以按照规范实现函数,我们在开发者文档里也给出了详细的开发指南方便大家参照查看。
第三个升级是 OpenMLDB 可以支持 UDF。在升级前,如果用户需要用到 OpenMLDB 不支持的聚合函数,需要通过复杂的步骤、繁琐的手续来实现——或者是开发者修改 OpenMLDB 的源代码库,增加 build-in 函数,重新编译,或者是把需要的代码 contribute 给社区 repo 才能使用。在 v0.5.0 中 OpenMLDB 可以支持 C++ UDF,后面社区会考虑其他语言的 UDF 开发。目前 OpenMLDB 支持用户自定义函数的动态注册,如右图所示,用户可以按照规范实现函数,我们在开发者文档里也给出了详细的开发指南方便大家参照查看。
二、OpenMLDB 应用案例介绍
Akulaku 智能计算架构中的特征平台
Akulaku 是一家主打海外市场的互联网金融服务企业,服务内容包括网上购物和分期付款,现金贷,保险等等,也就是 Akulaku 包含金融属性和电商属性,以金融属性为主。同时,Akulaku 也是 OpenMLDB 的第一个社区用户。
如今,Akulaku 已经把 OpenMLDB 与自身的智能计算架构做了一个深度整合,主要应用在金融风控,电商智能客服以及电商推荐等场景中。
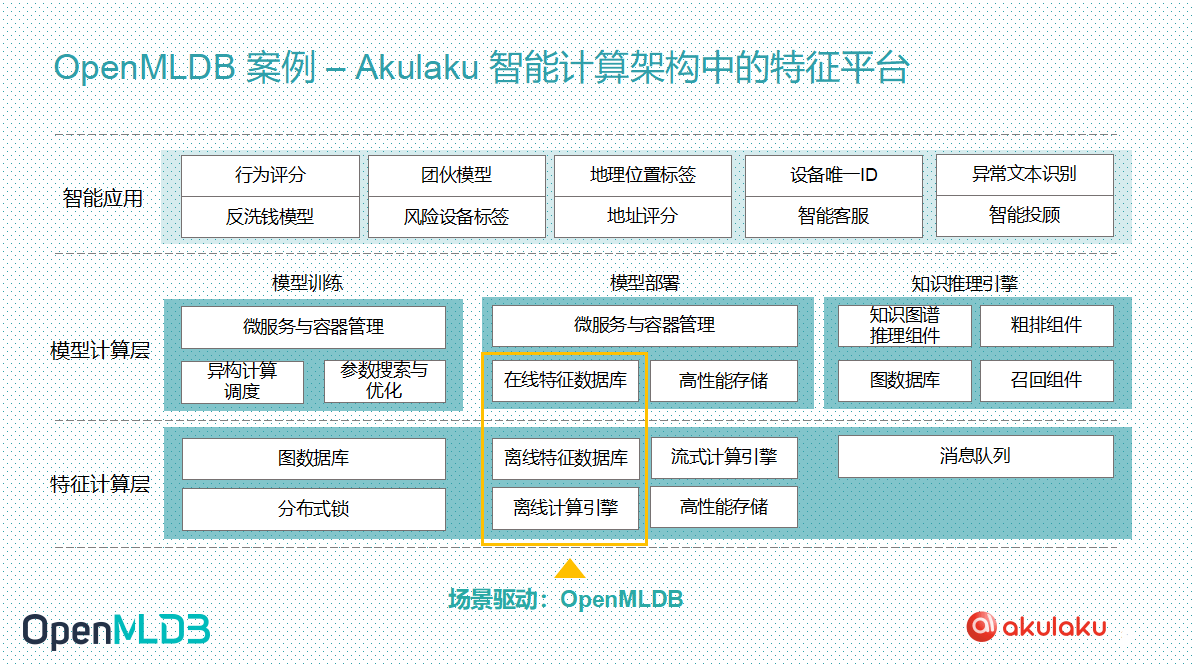 Akulaku 构建的智能计算架构中,最上层是品种丰富的智能应用,而 OpenMLDB 主要作用于下面的模型计算层和特征计算层。在模型计算层的模型部署部分应用了 OpenMLDB 的实时计算引擎,而特征计算层使用了 OpenMLDB 的离线开发功能。所以作为线上线下一致的生产级特征平台,OpenMLDB 纵跨了模型计算层和特征计算层,嵌入在 Akulaku 的智能计算架构中提供特征服务。
Akulaku 构建的智能计算架构中,最上层是品种丰富的智能应用,而 OpenMLDB 主要作用于下面的模型计算层和特征计算层。在模型计算层的模型部署部分应用了 OpenMLDB 的实时计算引擎,而特征计算层使用了 OpenMLDB 的离线开发功能。所以作为线上线下一致的生产级特征平台,OpenMLDB 纵跨了模型计算层和特征计算层,嵌入在 Akulaku 的智能计算架构中提供特征服务。

Akulaku 在实际应用中可以通过 OpenMLDB 以场景驱动的方式处理 10 亿条订单的滑窗特征计算,其测试的请求延迟为 4 毫秒。上图左侧可见 Akulaku 在特征计算环节遇到的难点,他们要求在低延迟的同时满足高时效性,同时要兼顾高吞吐量,还要求线下分析和线上部署的逻辑一致。这些要求正好与 OpenMLDB 的主要特性相互契合。
于是,基于 OpenMLDB 的解决方案 Akulaku 在业务调用环节在现用现算的逻辑之下使用 OpenMLDB 进行实时计算。Akulaku 使用了持久内存 PMEM,同时以 SQL 作为离线和在线的桥梁,然后在线基于时序数据库做了时间滑窗。最后实现的效果是可以实现近 1 天订单数量(10 亿条左右)上的实时特征计算。通过 OpenMLDB 的应用,Akulaku 可以做到实时更新、时间窗口实时滑动,在下单环节延时不超过 200 毫秒,在最后的一天订单查询环节更是达到了只有 4 毫秒的延时。在测试中,他们使用了 3 台 PMEM 的云上节点最终实现了订单查询的需求。
三、结语
1. Roadmap
 ● 工具开发:在 v0.6.0 Roadmap 中我们希望进一步增强 OpenMLDB 的易用性和可运维性,计划提供数据库状态自检和报告工具、查询调试和 tracing 工具、数据库性能分析和统计报告工具。这些工具可以帮助用户自查问题,提升效率。
● 生态扩展:在生态整合的过程中,Flink CDC Connector 已经被提上计划。
● 算法开发:虽然 OpenMLDB 目前还不支持特征编码的算法,但是我们在逐步纳入相关算法,让 OpenMLDB 成为更完整的特征平台。
(欢迎大家在https://github.com/4paradigm/OpenMLDB/issues/1519上留言表达自己的需求和建议。)
● 工具开发:在 v0.6.0 Roadmap 中我们希望进一步增强 OpenMLDB 的易用性和可运维性,计划提供数据库状态自检和报告工具、查询调试和 tracing 工具、数据库性能分析和统计报告工具。这些工具可以帮助用户自查问题,提升效率。
● 生态扩展:在生态整合的过程中,Flink CDC Connector 已经被提上计划。
● 算法开发:虽然 OpenMLDB 目前还不支持特征编码的算法,但是我们在逐步纳入相关算法,让 OpenMLDB 成为更完整的特征平台。
(欢迎大家在https://github.com/4paradigm/OpenMLDB/issues/1519上留言表达自己的需求和建议。)
2. 感恩和欢迎开发者
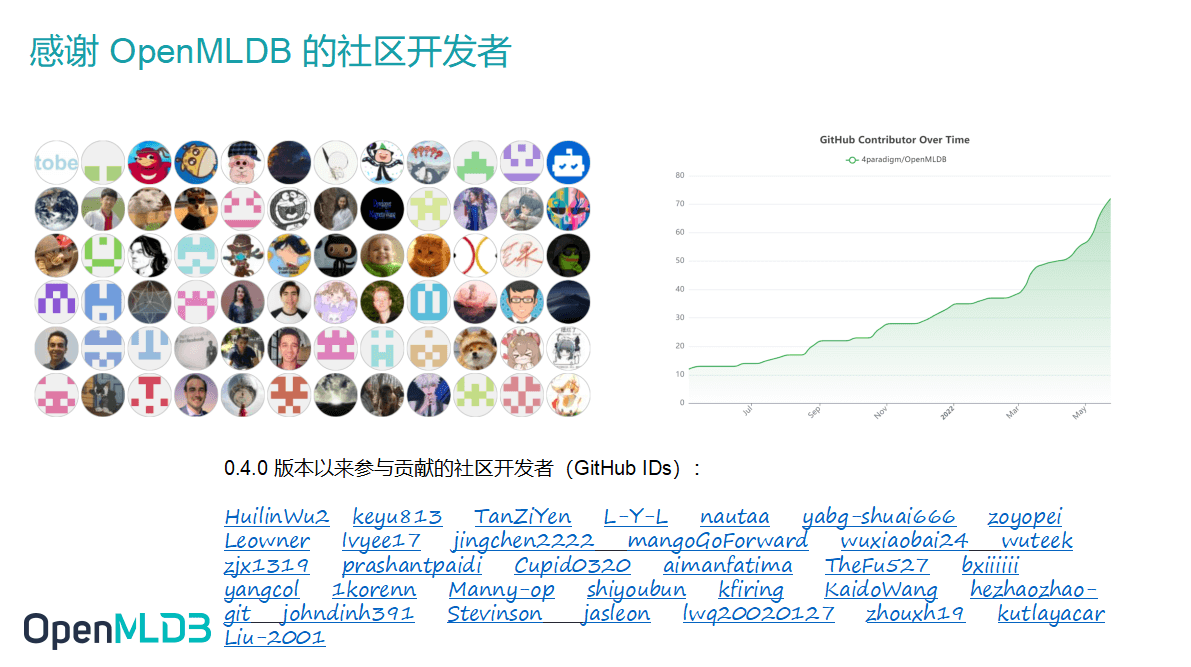 在最后我想感谢 OpenMLDB 社区的开发者对社区的贡献。到目前为止,OpenMLDB 收获了 74位开发者,0.4.0 版本发布以来有不少社区开发者为我们提供了新的思路,是开发者的贡献帮助 OpenMLDB 不断成长。同时,我们也欢迎新的开发者关注社区、贡献力量。
在最后我想感谢 OpenMLDB 社区的开发者对社区的贡献。到目前为止,OpenMLDB 收获了 74位开发者,0.4.0 版本发布以来有不少社区开发者为我们提供了新的思路,是开发者的贡献帮助 OpenMLDB 不断成长。同时,我们也欢迎新的开发者关注社区、贡献力量。
 今天的分享就到这里了,感谢大家。
今天的分享就到这里了,感谢大家。








