

基于OpenMLDB v0.4.0快速搭建全流程线上AI应用
OpenMLDB在立项开始就有很多性能的优化,包括基于LLVM的JIT优化,可以针对不同的CPU架构、Linux服务器或MAC服务器,通过LLVM做对应的代码生成优化,甚至是最新的基于M1的ARM架构苹果电脑,也是可以让OpenMLDB针对这种场景做优化的。
前面提到了在部分场景OpenMLDB可以比Spark有10倍甚至10倍以上的性能提升,其实也得益于我们对 Spark做了很多代码优化,包括像开源Spark不支持的窗口倾斜优化、窗口并行优化等等,甚至我们对 Spark源码进行了改造,来实现这种定制化的针对AI场景的性能优化。
OpenMLDB在存储上也有优化,传统的数据库服务大多基于文件,这种基于b+树数据结构的存储,对于高性能在线AI应用还是不太适合,还可能需要针对时序特征做优化。我们实现了针对分区键和排序键盘做的多级跳表数据结构,能进一步提升OpenMLDB在时序数据上的读写性能。
近期我们正式发布了OpenMLDB 0.4.0版本,这个版本也有很多性能和功能上的优化,那么本文会介绍OpenMLDB 0.4.0最新版本上的一些新特性,以及怎么基于这个新版本来快速搭建一个全流程的线上AI应用。
首先做一个简单的自我介绍,我叫陈迪豪,目前在第四范式担任平台架构师,是OpenMLDB项目的核心研发和PMC成员,之前参与过分布式存储HBase、分布式的基础架构项目OpenStack项目的开发,是机器学习中常用的TVM框架的贡献者,目前专注于分布式系统和数据库的设计。

今天会给大家介绍三个方面的内容:
- OpenMLDB 0.4.0全流程的新特性
- OpenMLDB 0.4.0单机版和集群版的快速上手
- 手把手教大家如何使用OpenMLDB来快速搭建一个全流程的线上AI应用
【01 | OpenMLDB 0.4.0的全流程新特性介绍】
OpenMLDB 0.4.0 全流程新特性 1 | 在线离线统一存储
第一个新特性是,OpenMLDB的在线存储和离线存储统一了,即一致性的表的视图,右上角是我们旧版本的表信息,通过SQL的describe语句,可以看到这个表名叫T1, 它的Schema信息,包含多少列以及每一列的类型,下面就是它的索引信息。
在0.4.0我们新增加了一个统一的表视图,就是把离线存储和在线存储统一到一起了。右下角就是在一个普通表的定义下面,增加一个offline的table信息,信息中会包括:offline存储路径、离线存储的数据格式、是否是deep copy等一些属性。
统一存储也是业界数据库里面很少出现的设计,它实现了离线表和在线表共享一套表名和scheme,共享一套索引信息,共享一个SQL解析引擎,我们使用C++实现的SQL解析引擎来编译SQL,然后共享同一个数据引入和导出流,也就是说离线表和在线表都可以使用相同的SQL语句来做数据导入和导出,他们唯一的区别就是离线和在线分别有独立的持久化存储。我们刚刚提到的在线是全内存的高性能多级跳表存储,离线上我们支持让本地的文件存储以及像HDFS这种分布式存储,来应对离线和在线不同的场景需求。

OpenMLDB 0.4.0 全流程新特性 2 | 高可用离线任务管理
第二个新特性就是,新增加了一个高可用的离线任务管理服务,叫TaskManager Service。
高可用的离线任务管理服务,支持本地或Yarn集群上的Spark任务管理,支持使用SQL来做任务管理,像SHOW JOBS, SHOW JOB, STOP JOB等,都是通过拓展SQL语法来实现的。它内置支持多种数据任务,包括:导入在线数据,导入离线数据,导出离线数据。

OpenMLDB 0.4.0 全流程新特性 3 | 端到端的AI工作流
第三个重要的特性是,实现了真正的端到端AI工作流,可以基于SDK或者CLI命令行使用。
左边的列表就是我们在做端到端AI应用落地的8个步骤,分别是:创建数据库、创建数据库表、导入离线数据、进行离线的特征抽取,然后使用机器学习框架进行模型训练、部署SQL上线、导入在线数据,以及上线在线特征服务。
从第1到第8个步骤,几乎每个步骤都可以通过OpenMLDB的SDK或命令行来实现:
- 使用标准的SQL语句创建数据库和创建数据库表,这个是标准SQL就支持的。
- 像导入离线数据,一些SQL方言也可以支持,例如SQL Server或MySQL可以支持类似这种Load Data in File的语法,即从文件导入数据到一个表中。
我们也支持离线和在线的数据导入,以及离线的特征抽取,因为前面介绍了我们特征计算都是使用拓展的SQL语言,我们在命令行里集成了离线SQL任务的提交功能,你可以在命令行去执行一个标准的SQL,比如这里的select sum语句,使用SQL提交任务后,因为它是离线任务,因此会提交到一个分布式的计算集群,比如yarn集群,然后做分布式的离线特征计算。
对于第5步机器学习模型训练:
- 我们支持外部的机器学习训练框架,像TensorFlow,PyTorch,LightGBM,XGBoost或者OneFlow等;
- 因为我们生成的是标准的样本数据格式,像CSV、LIBSVM或者TFRecords等,用户可以使用TensorFlow等框架来做模型训练;
- 这些框架也可以提交到本地、yarn集群、k8s集群等,来做分布式的训练;
- 支持使用GPU等硬件进行加速,跟我们的特征数据库OpenMLDB是完全兼容的。
模型训练以后,即我们的SQL特征可以上线了,然后可以直接执行一个Deploy命令,接上要上线的SQL,就可以上线我们的在线特征服务了。这个也是我们通过SQL拓展来实现的。
然后上线后的服务,需要给它注入一些历史的时序特征,我们称之为特征的蓄水。用户的一些历史数据,也可以使用Load Data的这个SQL语句来完成。
完成以后,我们内部会起一个支持HTTP和RPC接口的服务,客户端使用标准的HTTP请求就可以访问了,或者使用我们的Java、Python SDK。未来我们也会把这个功能集成到CLI中,来实现全流程的端到端AI工作流在命令行上的整合。

【02 | OpenMLDB 0.4.0 单机/集群版快速上手】
介绍完0.4.0新增的全流程特性,那么接下来,就给大家快速上手一下0.4.0的单机版和集群版功能。
首先单机版和集群版的区别是:
- 单机版部署简单,模块比较少,只需要下载一个预编译的Binary就可以了,没有任何外部的依赖。单机版的功能也是齐全的,支持Linux和MAC操作系统,MAC下基于M1芯片的ARM架构,或者是基于英特尔CPU芯片的x86架构也都是支持的。因此,它适合于功能测试和小规模的POC测试。
- 集群版有完整丰富的功能集。
- 它支持高可用,所有的节点都是高可用的,没有单点故障。
- 它支持大容量存储,虽然我们的在线存储数据是放在内存里,但是它支持存储的水平拓展。随着数据量增加,只要水平增加通用的x86的存储服务器就可以了。
- 它是高性能的,无论是离线计算还是在线计算,集群版都可以支持分布式的并行计算,加速建模和特征抽取的时间。

OpenMLDB 0.4.0 单机版快速上手 | 启动单机版OpenMLDB数据库
单机版的起使用方法就非常简单了。单机版和集群版在GitHub上都是开源的,在GitHub下载的代码,底层就支持集群版的功能。对于单机版我们提供了一个脚本,只要执行这个脚本,就会启动单机版需要的三个组件。右边是它的架构,包括一个Name Server服务和一个API Server服务,底层数据会存储在单个Tablet上,那么用户使用命令行或者SDK就可以访问我们的服务了。

OpenMLDB 0.4.0 单机版快速上手 | 使用OpenMLDB客户端
客户端的使用非常简单,前面使用一个脚本启动完这个集群后,可以像MySQL这样,使用一个客户端的命令行工具,指定IP和端口连接OpenMLDB数据库。连接后会打印一些集群的基本信息,包括版本号等信息。

OpenMLDB 0.4.0 单机版快速上手 | 执行标准SQL
连接上以后,我们就可以使用标准的SQL语句了。
PPT左边列举了我们已经支持的SQL语句,在我们的文档网站中可以看到更详细的介绍。基础的SQL,如DML、DDL等语句都已经支持了,SELECT INTO和各种SELECT子查询语句也是可以支持的。
右边就是一些执行SQL命令的截图。使用数据库一般的使用流程就是:
- 创建一个数据库,然后Use数据库,后面的SQL操作就会在默认的DB上完成;
- 我们可以Create table,这也是遵循标准这种ANSI SQL语法的。但相比于标准SQL,我们在创建表的时候,还可以做索引和时间列的指定;
- 通过Show tables,看到已经创建好的table。
我们也支持标准的SQL插入语句,把单条数据插入到数据库表里面,通过select语句可以查询,这是OpenMLDB作为一个最基础的在线数据库提供的一些功能。

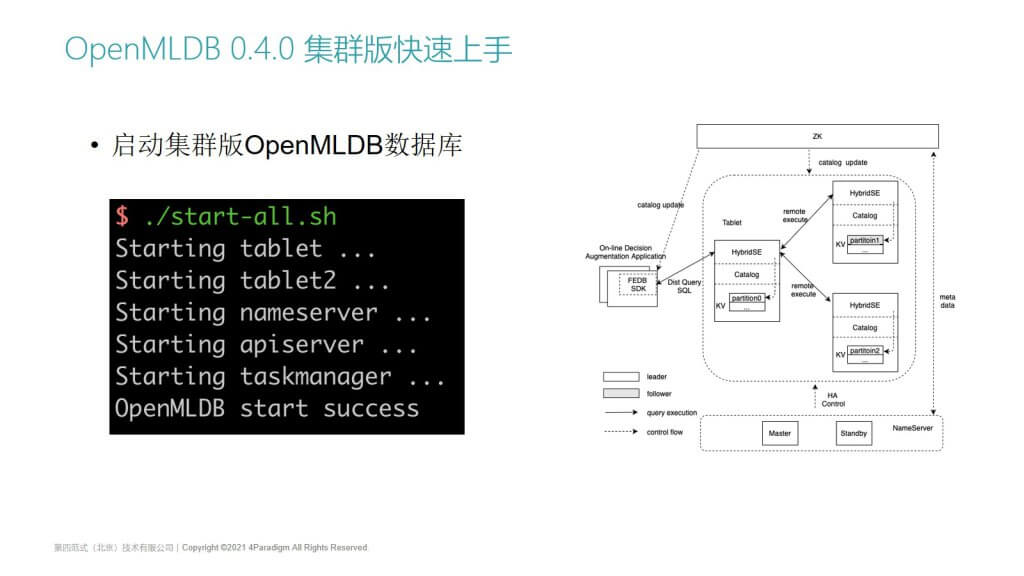
OpenMLDB 0.4.0 集群版快速上手 | 启动集群版OpenMLDB数据库
那么接下来我会介绍集群版。集群版的启动方法跟单机版类似,我们会提供一个star-all脚本。集群版相比于单机版,有高可用以及多组件的特点。
- 首先它的组件会更多,除了我们会启动前面提到的的tablet,name server和api server以外,我们为了实现高可用,默认会启动两个tablet,以保证所有的数据至少是两备份的。
- 用户可以在配置文件里面配置数据的备份数,以及集群的规模。
- 很重要的一点是,在0.4.0版本支持了离线的任务管理,因此也会增加一个叫task manager的高可用任务管理模块。
ppt右边是一个基础的架构图,除了OpenMLDB本身以外,高可用的实现目前依赖一个ZooKeeper集群。OpenMLDB的一些基础的元数据,包括主节点服务还有需要持久化的信息会存储到ZK上面,name server启动后把自己的高可用地址注册到ZK上,tablet会通过ZK来连接主name server已经监听一些元数据的更新。
OpenMLDB 0.4.0 集群版快速上手 | 集群版OpenMLDB配置文件
集群版的部署会相对复杂,它新增了task manager模块,大家也可以简单看一下技术组件的配置文件,其中比较重要的是,大部分组件都需要配置ZooKeep的IP和路径,保证所有的组件都是连接到同一个ZooKeep上,通过Zab协议实现高可用的元数据管理,来保证整个集群的高可用。

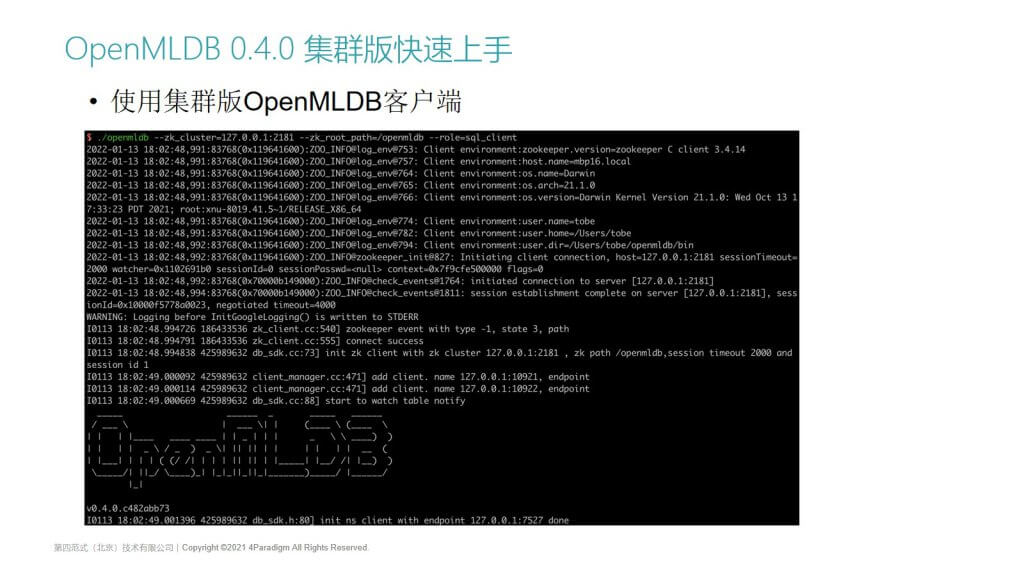
OpenMLDB 0.4.0 集群版快速上手 | 使用集群版OpenMLDB客户端
使用集群版的客户端跟单机版稍微有一点区别,在使用OpenMLDB命令行客户端的时候,它不再是直接指定name server的IP和端口,因为name server也是高可用的,它的IP端口在Failover时可能会变,所以我们在启动的时候,需要配置ZK的信息,启动后会打印更多集群版相关的一些配置和版本信息等。
它的使用方法跟单机版是类似的,我们可以通过前面提到的SQL语句,你可以把它当成一个超高性能的,基于全内存的时序数据库,或者是支持SQL的数据库来使用。
OpenMLDB 0.4.0 集群版快速上手 | 使用集群版OpenMLDB高级功能
集群版还有一些更高级的功能,这里给大家介绍两个:
1.离线模式和在线模式。这是集群版特有的功能,因为单机版所有的计算都是在单机上,所以不会区分在线模式和离线模式。集群版支持对于HDFS等海量数据的存储,离线计算底层目前也是基于Spark来做的。
那么离线模式和在线模式怎么使用的呢?
- 我们支持一个标准SQL的Set语句,然后可以看到当前的execute_mode是online的,online的时候我们执行的SQL语句,都是通过在线模式执行的,也就是去查内存的数据。
- 通过set @SESSION.exexute_mode = "offline",就可以把模式切换成离线了。
- 可以看到当前模式是offline,offline模式的SQL查询就不是去内存里面查了,因为在真实的场景里面,比如风控或者团伙欺诈识别,离线数据可能是海量的,可能是几T到几百T的规模。SQL查询肯定不是交互能马上返回结果的,而且这个查询结果也不可能完全放在某一个节点做聚合。所以在离线模式下,我们会把SQL的查询当成一个任务。可以看到任务的基本信息,包含任务ID、任务类型、任务状态等等。
- 在执行完SQL以后,0.4.0版本会提供一些命令,比如Show jobs,查看任务的状态,查看日志信息等等,来实现这种离线的任务管理。这部分管理功能也集成到了CLI命令行之中。
2. 部署SQL到线上服务。这是集群版和单机版都支持的。这点是其他在线数据库不支持的。用户在创建完数据库和数据库表以后,对于某一个做完特征抽取的SQL,科学家认证比较有效后,可以通过Deploy命令来上线,然后再通过SHOW DEPLOYMENT就可以看到我们已经部署的服务,这有点类似在SQL里面的一个存储过程,每一个Deployment都对应一个可上线的SQL。我们作为用户使用线上服务的时候,它可以通过deploy的名字来做在线SQL的执行,这点跟我们的存储过程是类似的。

【03 | Workshop - 快速搭建全流程线上AI应用】
最后,我会通过一个workshop,带大家快速地从命令行开始,从头搭建一个全流程的线上AI应用。
应用场景
这是我们演示的场景,一个Kaggle的竞赛,叫New Your City Taxi Trip Duration,一个预估行程时间的机器学习场景。我们会下载比赛提供的一个计程车历史行程数据,开发者或者建模科学家需要根据这些数据,使用机器学习的方法,来预估新给出的测试集来预估行程时间。训练数据并不大,一共是11列,大概是100多万行,它的特点是包含了Timestamp的时序数据,对于行程预估场景时序数据是比较重要的。我们需要根据每个出租车行驶的历史记录,还有前序的一些特征,来做最终行程时间的预估。

OpenMLDB 0.4.0技术方案
这次演示使用基于OpenMLDB 0.4.0的技术方案,这里先汇总了一下:
- 特征抽取语言:使用的是科学建模科学家最熟悉的SQL语言;
- 模型训练框架:这个例子里面使用的是LightGBM,当然大家如果想使用TF或者PyTorch也是可以支持的;
- 离线存储引擎:使用本地的文件存储,因为它样本的数据量其实并不大,只有100多万行,可能就是几十兆的数据,在实际场景中,机器学习的样本可能会更大更复杂,那么OpenMLDB也是可以支持HDFS存储的;
- 在线存储引擎:使用OpenMLDB的高性能时序存储,一个基于多级跳表数据结构的内存存储;
- 在线预估服务:使用的是OpenMLDB自带的API server,提供的是标准的Restful接口和RPC的接口。

第一步:运行OpenMLDB镜像
接下来就大家来演示一下,我们在使用OpenMLDB建模的时候,首先需要搭建一个OpenMLDB数据库运行环境。
OpenMLDB本身提供了一个测试的demo镜像,OpenMLDB的底层实现是基于c++的,本身会比较稳定和易安装。我们在使用OpenMLDB的时候,可以使用我们在GitHub上提供的官方docker镜像。mac环境或者Linux环境也可以直接下载我们的源代码,本地编译和执行。
执行完就进入了该容器,截图就是它完整的docker file内容。为了demo演示,我们多安装了一些库,比如pandas,python,大家使用的时候只需要安装镜像和Binary,就可以通过一个脚本把Binary下载下来,并启动服务端和客户端了。镜像的内容也是非常干净的,不需要去下载一些额外的组件。
第二步:启动OpenMLDB集群
第二步就是启动OpenMLDB集群,可以使用init.sh(我们封装好的一个脚本),或者OpenMLDB项目里面提供的start脚本,也可以直接用自己编译的Binary来启动。
因为我们这次演示的集群版的完整功能,所以我们会先启动ZooKeeper服务,并启动我们依赖的一些组件,像tablet、name server、API server和task manager。只要把这几个组件启动以后,我们就拥有了集群版OpenMLDB的功能。大家如果感兴趣,也可以看sh脚本的内容,init.sh也会支持单机版和集群版,我们使用集群版会多启动了一个ZooKeeper,以及所有的OpenMLDB的组件。
组件的启动其实也是非常简单的,就是start-all的脚本内容。我们会定义很多个组件,并做一个循环,把每一个组件都单独起起来。这些组件的启动是通过OpenMLDB c++项目编译出来的一个binary,当然不同平台要在对应的平台上编译出来,然后使用一个mon工具把它启动起来就可以了。

第三步:创建数据库和数据表
服务已经启动后,我们可以用一个类似MySQL的客户端做连接。只要配置好ZK的地址,就能自动找到name server的地址,进入到数据库的里面,此时,就可以执行大部分标准的SQL语句了。
这里为了演示我们计程车端到端的机器学习建模流程,我们将:
- 先创建一个测试用的DB,create database,然后再use database;
- 此时通过show databases命令就可以看到database已经创建好了;
- 然后我们在database里面创建一个表,因为还没开始做离线模型训练,我们无法提前知道表需要建什么索引,所以我们支持用户不指定索引来创建表。现在可以看到表大概有十一列,然后这个表对应的就是Kaggle比赛的数据集,他提供的11列的数据类型,其中包括多列timestep类型的数据。
- 此时可以看到create successfully了,表已经创建好了,叫t1。

第四步:导入离线数据
第4步我们就需要开始导入离线数据了,把Kaggle竞赛里面提供的训练数据导入进来,目前支持多种数据格式的导入,包括parquet格式和csv格式。
为了进行离线的数据导入,我们需要把当前的执行模式切换成离线,然后通过load data语句然后来进行。
为什么要切换成离线呢?如果没有切换成离线的话,此时的数据导入就会变成在线数据导入。如果离线数据量特别大,或者数据是从HDFS导入的,那么全部数据导到我们的在线的内存存储是不靠谱的,所以把执行模式切换成离线非常重要。
然后执行一个导入的SQL,这个SQL会提交一个任务,通过show jobs就可以看到这个任务的状态,它是一个ImportOfflineData的一个任务,大概几秒钟这个任务就已经完成了,数据就已经导入了进来。
我们重新看一下数据库,可以看到在刚刚导入的时候,是还没有导入离线数据的,没有离线的这些地址的。在离线导入成功以后,表的属性里面就会包含离线的信息,它表示离线的数据已经导入到当前的某个路径上,可以看到这个数据文件也正确导入了。

第五步:使用离线数据进行特征抽取
我们继续刚刚的演示,先把模式切换成离线。离线数据导入以后,就可以进行离线的特征抽取,这个步骤不同的建模场景花费的时间不同,需要有建模科学家来选择需要抽取需要什么特征,然后去不断地调整特征抽取的SQL脚本。
接下来我们可以使用over window滑动窗口来做时序特征,去求它的min、max等聚合值,也可以取单行的特征,对某一行做一个单行的计算。
最后SQL执行完以后,我们要把特征抽取后的样本数据存放到一个位置,可以让它导出到本地的某个路径,如果说数据量比较大,也可以导出到一个HDFS分布式存储里面。
此时可以看到这个任务执行成功了,通过show jobs就可以看到job ID是2,job的状态从最开始的submitted变成了running,因为它在分布式地执行,虽然不是一个很复杂的SQL,但是它的数据来自t1离线数据。在真实的离线特征抽取里面,数据量可能非常大,不可能在本地内存里面完成SQL的计算,所以我们会把这个任务提交到一个本地或者yarn上的Spark去执行。
大家可以看到这个状态已经变成了finished,说明这个数据已经导出成功了。刚刚我们的SQL语句指定了导出路径,在命令行看到样本数据已经正确导出了。为了支持更多的训练框架,除了默认支持的csv格式还支持其他样本格式,这个数据文件的内容就是通过刚刚的SQL语句产生的样本数据,

第六步:使用样本数据进行模型训练
这个样本数据就可以使用开源的机器学习框架来做训练,这里使用我们的train脚本,大家也可以简单看一下它的内容,首先它引入了lightgbm第三方库,前面需要你输入刚刚指定的特征文件路径,以及它需要导出的模型的路径。
然后前面是对样本数据做一个整合,把多个csv文件整合成单个csv文件,然后通过panda把csv的特征读出来。下面是建模用户非常熟悉的机器学习建模脚本:
- 首先是对样本进行训练集合、预估集的拆分,把他的label列提取出来;
- 把python的dataset传进去,并配置一下我们使用的机器学习模型,像GBDT或者决策树、DNN模型都可以;
- 使用lightgbm的train函数就可以开始训练了。
这个脚本也可以替换成任何TensorFlow、PyTorch或者是oneflow等开源机器学习框架的训练脚本。我们执行这个脚本,因为它的样本数据并不是很多,所以他很快就把新的模型训练完并导出到输出路径上,后续我们就可以使用这个模型做模型上线了。但是大家一定要考虑到我们模型上线并不只是 model的influence,我们的输入数据是Kaggle提供的原始数据,所有的端到端机器学习流程一定是包括特征抽取,还有模型的influence的。

第七步:部署SQL上线
我们需要使用OpenMLDB提供的一个高性能的在线特征计算功能,把刚刚做的建模的SQL上线。我们从客户端重新进入OpenMLDB数据库里面,切换它的默认DB,SQL的部署跟前面的SQL离线特征计算是一样的,此时,并不需要对某一个特征做特殊的开发,我们只需要使用相同的SQL语句,前面加上deploy语句,就可以做SQL上线了。deploy的时候它会对某些键做分区,对时间列做排序,我们会对这些键分别提前建好索引,对这些数据进行按照索引来排列存储。

第八步:导入在线数据到OpenMLDB
Deploy完以后就可以做在线预估了,预估的时候我们肯定是希望实现在线预估的,因为我们做的特征是这种时序窗口特征,我们希望每个特征计算的时候,大家都可以根据前一天的窗口来做min或者max的聚合,所以我们一般会进行一个蓄水的操作,就是把一些线上数据导入到在线的数据库里面。在线的导入也是一个分布式的任务,我们执行完以后就可以看到提交了一个job,job目前也运行得很快,在本地环境里它的性能是非常好的,可以看到这个job3已经完成了,数据已经导入了。

第九步:启动HTTP预估服务和在线预估
有了导入后的在线数据,第9步我们就可以启动预估服务做在线预估了。预估服务包装了一下,有个叫start predict server的脚本,这个脚本是我们封装的一个很简单的Python HTTP server,HTTP server就会把一些客户端数据包装请求到API server,最后会打印结果。原始数据进来以后,通过特征计算得到样本数据,并且会去加载刚刚模型训练得到的LightGBM模型,要使用模型来接收在线返回的特征样本,然后再把这个预估结果给返回出去。

第十步:进行在线特征抽取计算
我们先启动predict server,最后一步就是做在线的predict。
在线的predict是我们封装的一个脚本,这个脚本就是一个HTTP的client,会把我们提供的原始数据列(这些输入包括字符串类型数据,不是特征抽取后的样本)作为参数传入,通过Python直接执行,这里执行得很快,单次在线的特征抽取可以做到10毫秒以内。
这个执行速度是如何做到的呢?这跟我们用户建模的SQL复杂度有关,像这种简单的特征,数据量比较小的话,甚至可以做到1毫秒以内,纯特征计算的时间,加上模型预估的时间,用户几乎没有感知就马上返回了。这里分别是通过我们SQL语句来做的特征样本在线的样本,然后这个是经过lightgbm返回的一个模型预估后的数据。
有些人可能觉得这跑几个脚本好像也没什么,你只是做了一些SQL的计算而已,我去MySQL里面查这个数据,好像也可以做到几十毫秒或者100毫秒以内返回。区别是什么呢?
- 像刚刚有观众提到的Feature store也可以支持这种特征存储,然后它也可以支持简单的特征计算,例如你传一个特征, trip_duration可能是10,然后你的特征是对它做归一化或者给它做一个变换,这种其实都是单行的特征,显然单行的特征性能是非常高的,无论是用Python还是c++来实现,你对于一个原始数据做一个乘法做一个加法,几乎就只需要一次CPU计算。
- 而我们支持的特征其实是一个滑动窗口的时序聚合特征,在计算输入的某一行数据时,计算的并不是只对这一行做一个数值计算,你需要从数据库里面去把这一行它一天以前的所有的数据给拿出来,然后根据ROWS BETWEEN或者RANGE BETWEEN的这种窗口定义语法,去做窗口的滑动,然后对窗口内的数据再做一个聚合。我们10毫秒以内的性能其实是对于这两个特征,然后分别做不同的聚合得到的结果。
- 如果不是使用专门的时序数据库,例如我们是从MySQL里面去获取它的当前行数据的前一天的所有的数据,可能窗口数据获取就要超过100毫秒,我们可以做到窗口数据获取,还有窗口特征计聚合计算以及最后的模型预估,整体时间都可以控制到10毫秒到20毫秒以内,这个是跟我们的存储架构设计是密不可分的,也是我们OpenMLDB跟其他的这种OLTP数据库的区别。最后我们就可以得到一个预估的结果。

上线全流程AI应用总结
那么总结一下上线全流程AI应用的10个步骤,其实前面都比较简单,就是启动openMLDB集群,创建数据库,创建表,然后进行离线数据导入和离线的特征计算。当特征抽取的SQL没问题以后,我们就可以做SQL的上线了,上线后会启动一个支持http的预估服务,然后进行一个预估。在0.4.0版本中,几乎所有步骤都可以在SQL的命令行上执行和支持。未来我们也计划去支持基于命令行的在线特征抽取,甚至可以在命令行上拓展SQL语法来支持在命令行上做模型的训练等。

最后简单总结一下本次分享,首先给大家介绍的是OpenMLDB 0.4.0全流程的一些新特性,以及单机和集群版的快速上手,最后通过一个Kaggle比赛场景来给大家演示一下,怎么使用OpenMLDB快速搭建一个能够上线的AI应用。
欢迎大家来参与到我们的社区,目前项目的所有的文档和代码都在GitHub上,如果大家感兴趣,也可以参与issue的提交以及pull request代码开发。欢迎大家也扫码加入我们的微信交流群,我这边的分享就到这里,非常感谢大家的收听。

本文根据陈迪豪在『OpenMLDB Meetup No.1』中的演讲整理而成。








