

内存和磁盘的双存储引擎架构
使用场景描述
OpenMLDB 的线上服务部分为了满足不同的性能和成本需求,提供了两种分别基于内存和磁盘的存储引擎。关于这两种存储引擎的使用考量,和推荐匹配场景,见如下表。
| 内存存储 | 磁盘存储 | |
|---|---|---|
| 性能 | 低延迟(毫秒级)、高并发 | 预期相比较内存引擎有大约 3-7 倍的性能衰减,和场景有较大关系 |
| 成本 | 数据和索引存储在内存,成本较高 | 数据和索引存储在磁盘,成本较低 |
存储引擎架构
内存存储引擎架构
内存存储引擎的详细架构参考:在线模块架构
磁盘存储引擎架构
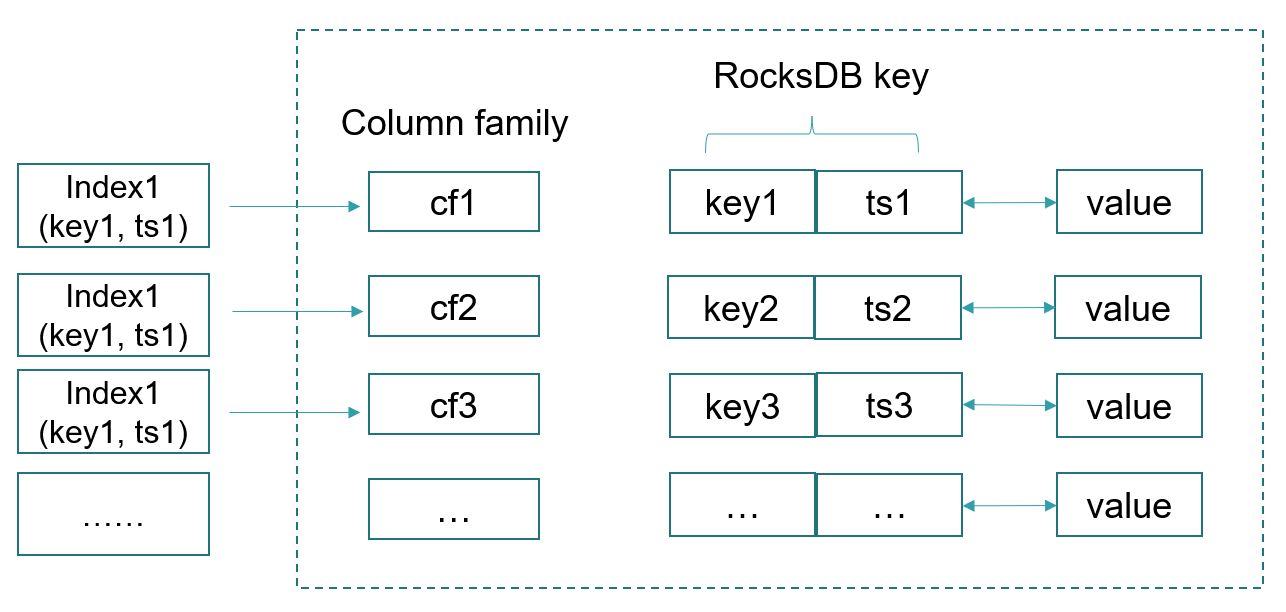
OpenMLDB 磁盘存储引擎底层基于 RocksDB 实现。RocksDB 本质上是一个基于磁盘的 KV 数据库,其实现的基本逻辑为将创建表格时的索引所对应的 KEY 和 TS (OpenMLDB 列索引)组合起来,成为 RocksDB 的 KEY,并且映射到相应的 column family。RocksDB 内的值则即为当前索引键对应的 OpenMLDB 内的一行数据。下图反映了基于 RocksDB 进行存储引擎映射的基本架构。
使用方式
内存引擎为 OpenMLDB 默认的存储引擎,两种引擎的使用说明如下:
- 两种引擎的指定为表级别,即在同一个数据库内,不同表格可以混合使用不同的存储引擎(但是一张表只能对应一种存储引擎)
- 存储引擎的指定通过建表时的参数
storage_mode进行指定,其可选值为Memory,HDD, 或者SSD,比如
CREATE TABLE t1 (col0 STRING, col1 int, std_time TIMESTAMP, INDEX(KEY=col1, TS=std_time)) OPTIONS(partitionnum=8, replicanum=3, storage_mode='HDD');- 如不指定存储模式,则默认使用内存存储引擎
- 表格创建以后,无法再修改其存储模式
功能支持对比
虽然在大部分的场景,双存储引擎的功能支持是一致的,但是在某些场景上还是有所区别。下图列出了相关的功能支持区别,在做切换之前需要考虑对于业务是否有实际的影响。
| 内存引擎 | 磁盘引擎 | |
|---|---|---|
| 动态增加/删除索引 | ✓ | ✘ |
| 创建 absandlat 和 absorlat 索引 | ✓ | ✘ |
| 允许同一个 key 下的数据有相同的时间戳(TS) | ✓ | ✘ |
| 精确条数指标统计 | ✓ | ✘ |
| BulkLoad | ✓ | ✘ |
性能对比测试
硬件配置
- CPU:2x Intel(R) Xeon(R) Gold 6230 CPU @ 2.10GHz
- SSD:Intel DC P4600 Series 2TB,磁盘引擎选用该 SSD 作为存储介质
- DRAM:物理机器内存 512 GB,但是为了方便进行实验,我们使用工具 Chaosblade (https://github.com/chaosblade-io/chaosblade) 进行模拟内存占用。最终模拟测试可用的内存为 8/16/32 GB
部署和负载
- OpenMLDB 使用集群模式部署,采用了两个 tablets 的配置,没有开启预聚合优化。
- 测试所用数据和脚本使用了 OpenMLDB 内置的测试脚本的默认参数,可以参考 https://github.com/4paradigm/OpenMLDB/tree/main/benchmark
- 对于实时请求,我们使用了基于全量数据的随机查询,来避免系统缓存所带来的影响。
- 对于某组特定的可用内存参数,我们不断增大数据量,来查看系统性能和数据量的关系。由于系统缓存的存在,我们预期当数据量小于内存时,缓存可以很好的避免磁盘 IO 造成的性能衰退;但是随着数据量的增大,性能将会呈现持续下降趋势,直到某一个平衡点。这个实验可以帮助我们学习到不同数据量下的性能表现,以及最终达到的预期最差性能。
测试结果
- CPU:2x Intel(R) Xeon(R) Gold 6230 CPU @ 2.10GHz
- SSD:Intel DC P4600 Series 2TB,磁盘引擎选用该 SSD 作为存储介质
- DRAM:物理机器内存 512 GB,但是为了方便进行实验,我们使用工具 Chaosblade (https://github.com/chaosblade-io/chaosblade) 进行模拟内存占用。最终模拟测试可用的内存为 8/16/32 GB
部署和负载
- OpenMLDB 使用集群模式部署,采用了两个 tablets 的配置,没有开启预聚合优化。
- 测试所用数据和脚本使用了 OpenMLDB 内置的测试脚本的默认参数,可以参考 https://github.com/4paradigm/OpenMLDB/tree/main/benchmark
- 对于实时请求,我们使用了基于全量数据的随机查询,来避免系统缓存所带来的影响。
- 对于某组特定的可用内存参数,我们不断增大数据量,来查看系统性能和数据量的关系。由于系统缓存的存在,我们预期当数据量小于内存时,缓存可以很好的避免磁盘 IO 造成的性能衰退;但是随着数据量的增大,性能将会呈现持续下降趋势,直到某一个平衡点。这个实验可以帮助我们学习到不同数据量下的性能表现,以及最终达到的预期最差性能。
测试结果
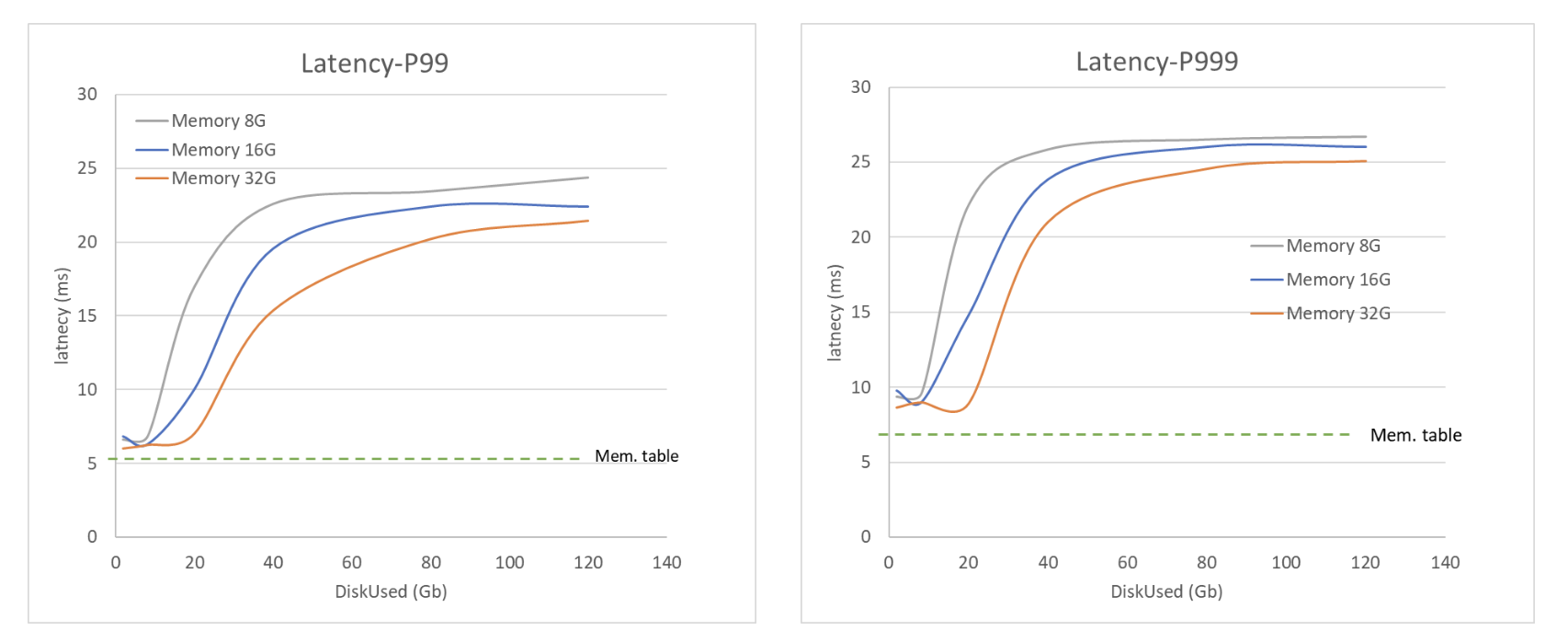 不同可用内存容量下,磁盘引擎的访问延迟(纵轴)和数据量大小(横轴)的关系
不同可用内存容量下,磁盘引擎的访问延迟(纵轴)和数据量大小(横轴)的关系
访问延迟的实验结果如上图所示,我们可以有以下观察和结论:
- 当数据量小于可用内存时,由于系统缓存的存在,依然可以保持较高的性能表现(毫秒级延迟)。
- 当数据量变大,性能将会持续下降,直到出现一个相对平衡的状态(拐点基本是当数据量为内存容量的 2-3 倍左右)。进入平衡状态主要是因为由于数据量较大,缓存基本失效,因此由磁盘 overhead 带来的性能衰退占据了主导。
- 在进入平衡状态以后,性能衰退到约为最优情况下(数据量较小时)的 20-50%
- 如果数据量小于内存,我们测试基于 64 GB 物理内存下 16 GB 数据量的内存存储引擎的性能,性能数字对应图上 Mem. table 所示的横虚线。可以看到,内存存储引擎可以相比较于磁盘引擎的最好性能,额外带来访问延迟大约 25% 的性能改进。该改进主要来自于基于内存存储引擎的双层跳表的索引结构,带来的窗口数据的快速访问。
- 综上分析,磁盘存储引擎整体的性能约为内存存储引擎的 15-38%
总结
本文总结了 OpenMLDB 双存储引擎的架构和功能对比,以及系统性的考察了磁盘引擎的性能表现。实际使用中,我们推荐根据实际的应用场景进行选择。比如对于我们所测试的应用场景,如果需要 10 毫秒左右的超低延迟,那么优先选择内存存储引擎;如果对于内存成本敏感,同时可以接受如 20-30 毫秒左右的延迟性能,则可以优先考虑磁盘引擎,将会帮你节省 80% 左右的硬件成本。








