

背景
本文示范如何使用 OpenMLDB 和 Byzer-lang 联合完成一个完整的机器学习应用。Byzer-lang 作为面向大数据和 AI 的一门语言,通过 Byzer-Notebook 和用户进行交互,用户可以轻松完成数据的抽取、ETL、特征/模型训练、保存、部署到最后预测等整个端到端的机器学习流程。
OpenMLDB 在本例中接收 Byzer 发送的指令和数据,完成数据的实时特征计算,并经特征工程处理后的数据集返回 Byzer,供其进行后续的机器学习训练和预测。
准备
心理准备:因为操作系统环境的千差万别,安装部署常常是最繁琐的和消耗时间的部分。请大家耐心准备,在遇到问题时及时寻求两个社区的帮助。
用户需要找一台 Linux 机器(虚拟机也行),然后部署如下几个应用(都很简单,基本都是下载、解压、运行即可):
- Byzer-lang: Byzer-lang 部署
- Byzer-Notebook:Byzer-Notebook 部署
- OpenMLDB 0.5.2:OpenMLDB 部署,注意是集群版的部署模式,并且 zk 路径要配置成 /openmldb
值得注意的是,如果没有使用对象存储这种共享存储,那么 Byzer-lang, OpenMLDB 需要部署在一台服务器,这样才能互相访问双方产出的文件。
部署时需要注意的几个小问题:
- 部署好 JDK8
- 请确保一些基础的命令,诸如有 curl、ipconfig 等命令。一般部署脚本里会用到,如果没有,按报错提示安装即可。
- 最好使用 bash 执行脚本而不是默认的 sh
对于最后确认是不是安装完成,可以按如下方式进行检查。
首先是检查 OpenMLDB, 用户可以在 OpenMLDB 安装目录里执行如下指令:
./bin/openmldb --zk_cluster=192.168.3.14:7181 --zk_root_path=/openmldb --role=sql_client顺利连接上后说明是可行的,此时需要初始化一个数据库和表:
CREATE DATABASE demo_db;
USE demo_db;
CREATE TABLE t1(id string, vendor_id int, pickup_datetime timestamp, dropoff_datetime timestamp, passenger_count int, pickup_longitude double, pickup_latitude double, dropoff_longitude double, dropoff_latitude double, store_and_fwd_flag string, trip_duration int);执行完成后大概这个样子:
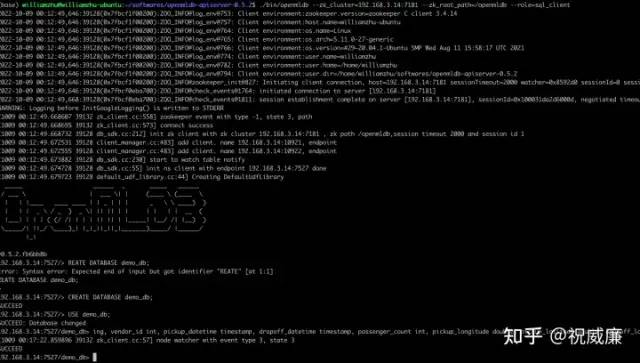
其次是检查 Byzer ,可以访问服务器的 9002 端口,如果你顺利进入 Byzer-Notebook 显示如下界面,则证明是可行的:
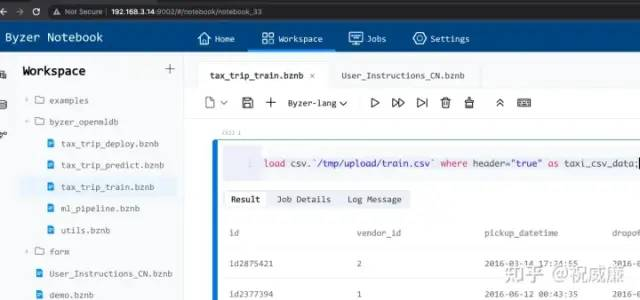
数据准备
首先,从 New York City Taxi Trip Duration 下载出租车的数据,解压得到如下数据集:
接着进入 Byzer-Notebook 首页,通过 上传 功能上传这个文件:
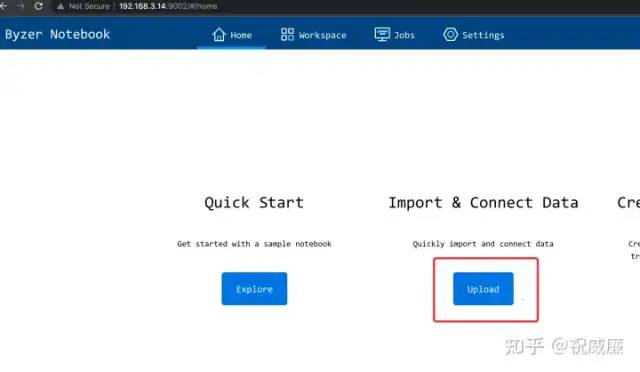
上传后你应该可以在 Byzer-Notebook 的文件系统里看到这个文件:
这样,我们数据就准备好了。
接下来,我们会分成三个步骤进行:
- 特征/模型训练
- 特征部署和模型部署
- 端到端的预测能力
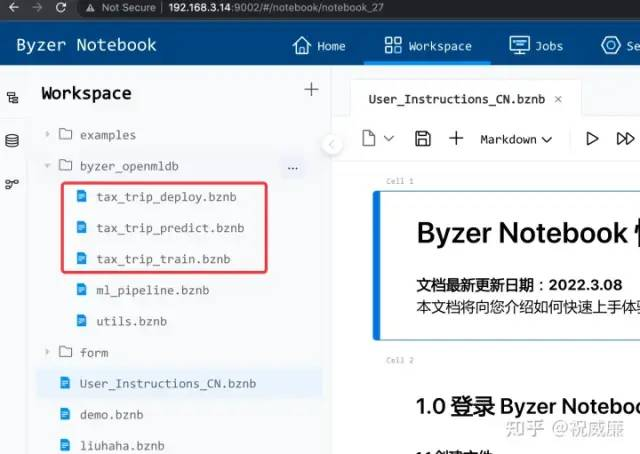
这三个步骤对应成三个 Notebook:
安装 Byzer-openmldb-3.0 插件
Byzer 和 OpenMLDB 通讯需要一个 Byzer 插件,可以在 Byzer-notebook 里直接执行一条指令来安装:
!plugin app add - "byzer-openmldb-3.0";注:如果是 sandbox 模式部署的 Byzer, 目前这个方式是无效的。
网速被限定 100k 以内,因为这个插件比较大,所以下载时间较长,需要大家耐心等待。
另外,在 Log Message 标签页会显示 下载进度信息。
特征/模型训练部分
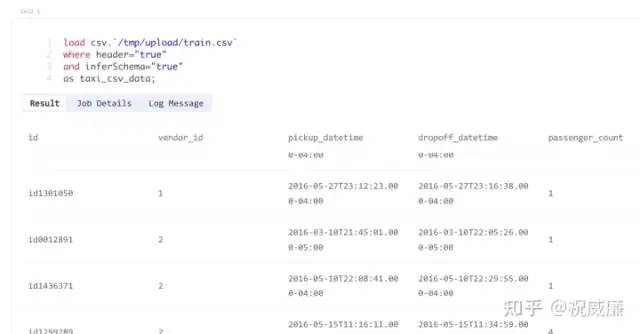
第一步,加载我们训练的 csv 文件看看:
load csv.`/tmp/upload/train.csv`
where header="true"
and inferSchema="true"
as taxi_csv_data;执行后输出结果如下:
为了方便,我们把这个数据保存到数据湖里,然后再次从数据湖里加载成一张表叫 taxi_tour_table_train_simple
save overwrite taxi_csv_data
as delta.`public.taxi_tour_table_train_simple` ;
load delta.`public.taxi_tour_table_train_simple`
as taxi_tour_table_train_simple;这样我们的数据就通过 数据湖 管理起来了。数据湖具有版本管理等功能,速度相比 csv 文件也更快。
但是 OpenMLDB 并不能直接访问数据湖,所以,我们还需要把数据导出一份到文件系统中,供 OpenMLDB 使用。
save overwrite taxi_tour_table_train_simple
as parquet.`/sample_data/data/taxi_tour_table_train_simple`;保存完成后,在侧面的文件系统里是可以看到下列内容:
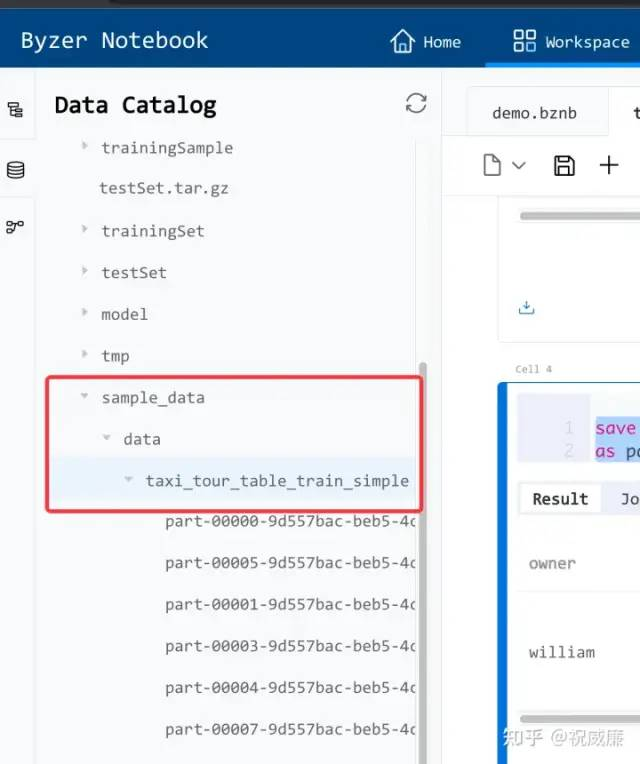
现在,我们需要让 OpenMLDB 把这个数据加载进去:
-- load the data to FeatureStore offline
-- /home/williamzhu/byzer-home/allwefantasy
run command as FeatureStoreExt.`` where
zkAddress="192.168.3.14:7181"
and `sql-0`='''
SET @@execute_mode='offline';
'''
and `sql-1`='''
SET @@job_timeout=20000000;
'''
and `sql-2`='''
LOAD DATA INFILE '${HOME}/sample_data/data/taxi_tour_table_train_simple'
INTO TABLE t1 options(format='parquet', header=true, mode='append');
'''
and db="demo_db"
and action="ddl";点击执行后效果如下:
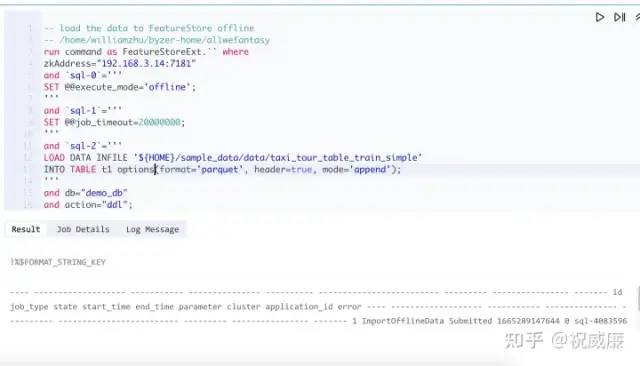
这里有点小遗憾, 测试的 OpenMLDB 版本的最后输出是一个格式化的字符串,所以显示比较凌乱。
值得注意的是,sql-2 是让 OpenMLDB 加载前面我们产生的文件,这里我们需要传递 ${HOME} 做前缀,因为 Byzer 是多租户的引擎,目录是虚拟目录,只有这样不同用户的目录才不会覆盖。OpenMLDB 要访问 Byzer 的目录,需要添加 ${HOME} 这个前缀。
注释,如果发现 ${HOME} 这个无效,请使用 Byzer Notebook 配置文件中的
notebook.user.home进行替代。比如我实验的时候的配置是这个: notebook.user.home=/home/williamzhu/byzer-home
OpenMLDB 是异步模式的,所以系统返回给 Byzer 的是一个任务 ID 号。我们可以使用如下代码看看任务是不是完成了:
run command as FeatureStoreExt.`` where
zkAddress="192.168.3.14:7181"
and `sql-0`='''
SET @@execute_mode='offline';
'''
and `sql-1`='''
SET @@job_timeout=20000000;
'''
and `sql-2`='''
show jobs;
'''
and db="demo_db"
and action="ddl";
!lastCommand named jobs;
select application_id, id, state,end_time from jobs order by id desc as output;输出结果如下:
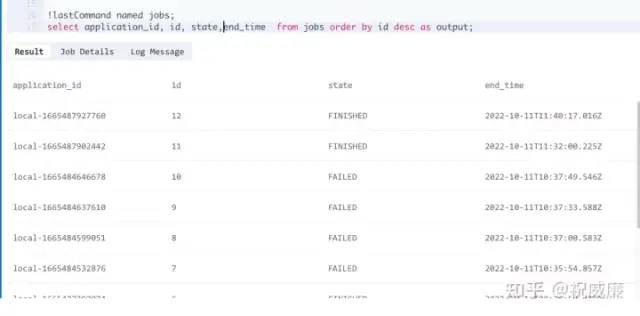
可以观察下 state 状态从 Running 变成 FINISHED, 然后可以继续往下走。
数据被加载到 OpenMLDB 后,现在就可以利用它计算特征,计算的特征我们会保存到 /tmp/feature_data 目录中供 Byzer 后续建模使用。
-- compute feature with OpenMLDB
run command as FeatureStoreExt.`` where
zkAddress="192.168.3.14:7181"
and `sql-0`='''
SET @@execute_mode='offline';
'''
and `sql-1`='''
SET @@job_timeout=20000000;
'''
and `sql-2`='''
SELECT trip_duration, passenger_count,
sum(pickup_latitude) OVER w AS vendor_sum_pl,
max(pickup_latitude) OVER w AS vendor_max_pl,
min(pickup_latitude) OVER w AS vendor_min_pl,
avg(pickup_latitude) OVER w AS vendor_avg_pl,
sum(pickup_latitude) OVER w2 AS pc_sum_pl,
max(pickup_latitude) OVER w2 AS pc_max_pl,
min(pickup_latitude) OVER w2 AS pc_min_pl,
avg(pickup_latitude) OVER w2 AS pc_avg_pl,
count(vendor_id) OVER w2 AS pc_cnt,
count(vendor_id) OVER w AS vendor_cnt
FROM t1
WINDOW w AS (PARTITION BY vendor_id ORDER BY pickup_datetime ROWS_RANGE BETWEEN 1d PRECEDING AND CURRENT ROW),
w2 AS (PARTITION BY passenger_count ORDER BY pickup_datetime ROWS_RANGE BETWEEN 1d PRECEDING AND CURRENT ROW) INTO OUTFILE '${HOME}/tmp/feature_data';
'''
and db="demo_db"
and action="ddl";执行结果:
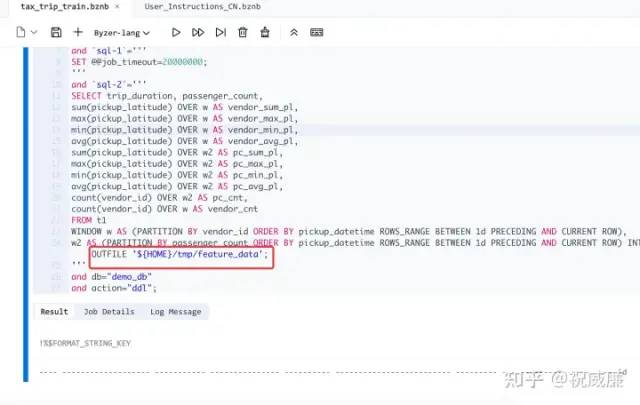
然后我们到 Byzer-Notebook 侧边的文件系统里,可以看到生成了对应的目录:
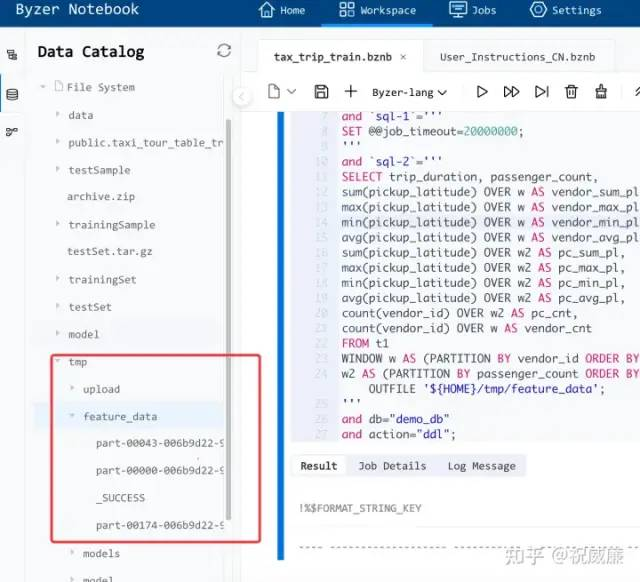
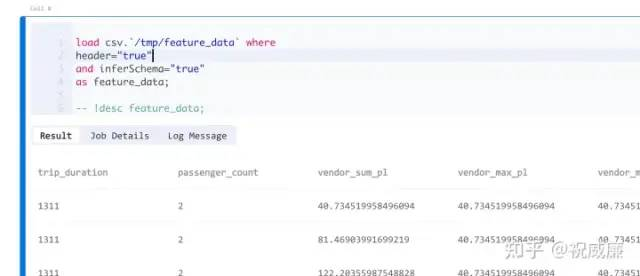
现在,我们可以用 Byzer 加载 OpenMLDB 产生的特征数据了:
load csv.`/tmp/feature_data` where
header="true"
and inferSchema="true"
as feature_data;
-- !desc feature_data;执行效果如下:
对特征在做一些处理,比如类型转换之类的:
select *, cast(passenger_count as double) as passenger_count_d,
cast(pc_cnt as double) as pc_cnt_d,
cast(vendor_cnt as double) as vendor_cnt_d
from feature_data
as new_feature_data;
-- !desc new_feature_data;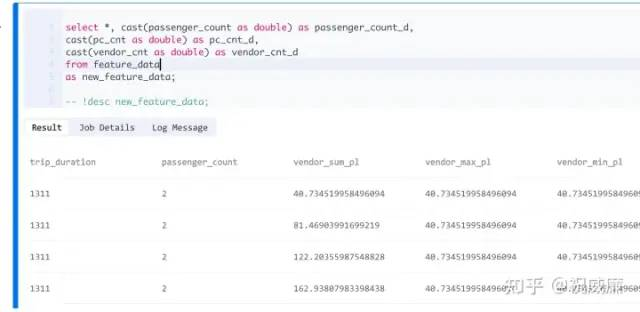
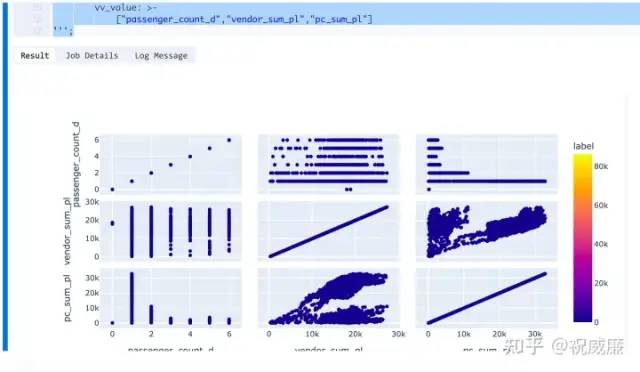
还可以看看特征之间的关系(这是个可选步骤,需要用到 Byzer 可视化插件,用户感兴趣可以参考文章——《祝威廉:Byzer-yaml-visualiaztion 插件介绍》 ,详见知乎):
select
passenger_count_d,
vendor_sum_pl,
vendor_max_pl,
vendor_min_pl,
vendor_avg_pl,
pc_sum_pl,
pc_max_pl,
pc_min_pl,
pc_avg_pl,
pc_cnt_d,
vendor_cnt
, trip_duration as label
from new_feature_data
as visual_data1;
-- 每个 label 按比例抽样
run visual_data1 as RateSampler.`` where sampleRate="0.9,0.1"
as visual_data2;
-- 获得 10% 的数据
select * from visual_data2 where __split__=1 as visual_data;
!visualize visual_data '''
runtime:
env: source /home/williamzhu/miniconda3/bin/activate ray-1.12.0
cache: false
control:
ignoreSort: true
fig:
scatter_matrix:
color: label
dimensions:
vv_type: code
vv_value: >-
["passenger_count_d","vendor_sum_pl","pc_sum_pl"]
''';执行结果如下:
最后,我们来生成最后可以给算法直接用的数据:
select vec_dense(array(
passenger_count_d,
vendor_sum_pl,
vendor_max_pl,
vendor_min_pl,
vendor_avg_pl,
pc_sum_pl,
pc_max_pl,
pc_min_pl,
pc_avg_pl,
pc_cnt_d,
vendor_cnt
)) as features, cast(trip_duration as double) as label
from new_feature_data
as trainning_table;执行结果如下:
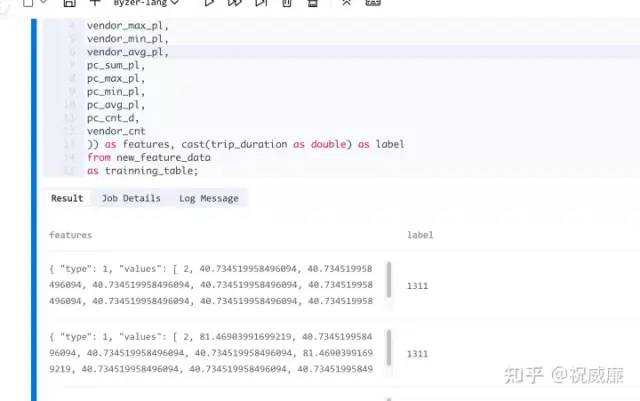
接着我们开始训练模型,使用 线性回归 算法来训练:
train trainning_table as LinearRegression.`/model/tax-trip` where
-- once set true,every time you run this script, MLSQL will generate new directory for you model
keepVersion="true"
-- specify the test dataset which will be used to feed evaluator to generate some metrics e.g. F1, Accurate
and evaluateTable="trainning_table"
-- specify group 0 parameters
and `fitParam.0.labelCol`="label"
and `fitParam.0.featuresCol`="features"
and `fitParam.0.maxIter`="30";模型会被保存在 /model/tax-trip 目录里。
执行结果如下:
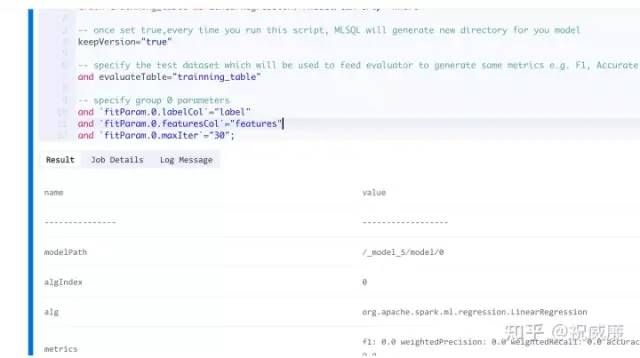
到此,我们模型训练部分结束。
特征部署和模型部署
既然是端到端,那么我们肯定需要把特征和模型代码都进行部署。部署依然很简单。
第一步部署特征工程:
-- deploy feature logical for online
run command as FeatureStoreExt.`` where
zkAddress="192.168.3.14:7181"
and `sql-0`='''
SET @@execute_mode='online';
'''
and `sql-1`='''
SET @@job_timeout=20000000;
'''
and `sql-2`='''
DEPLOY demo SELECT trip_duration, passenger_count,
sum(pickup_latitude) OVER w AS vendor_sum_pl,
max(pickup_latitude) OVER w AS vendor_max_pl,
min(pickup_latitude) OVER w AS vendor_min_pl,
avg(pickup_latitude) OVER w AS vendor_avg_pl,
sum(pickup_latitude) OVER w2 AS pc_sum_pl,
max(pickup_latitude) OVER w2 AS pc_max_pl,
min(pickup_latitude) OVER w2 AS pc_min_pl,
avg(pickup_latitude) OVER w2 AS pc_avg_pl,
count(vendor_id) OVER w2 AS pc_cnt,
count(vendor_id) OVER w AS vendor_cnt
FROM t1
WINDOW w AS (PARTITION BY vendor_id ORDER BY pickup_datetime ROWS_RANGE BETWEEN 1d PRECEDING AND CURRENT ROW),
w2 AS (PARTITION BY passenger_count ORDER BY pickup_datetime ROWS_RANGE BETWEEN 1d PRECEDING AND CURRENT ROW);
'''
and db="demo_db"
and action="ddl";接着模拟一个线上实时数据,方便部署后的使用:
-- mock online data
run command as FeatureStoreExt.`` where
zkAddress="192.168.3.14:7181"
and `sql-0`='''
SET @@execute_mode='online';
'''
and `sql-1`='''
SET @@job_timeout=20000000;
'''
and `sql-2`='''
LOAD DATA INFILE '${HOME}/sample_data/data/taxi_tour_table_train_simple'
INTO TABLE t1 options(format='parquet', header=true, mode='append');
'''
and db="demo_db"
and action="ddl";最后部署下我们的线性回归模型:
--%deployModel
--%url=http://192.168.3.14:9003
register LinearRegression.`/model/tax-trip` as tax_trip_model_predict;这些代码都在 tax_trip_deploy.bznb 文件里:
好了,现在我们来验证下我们部署的 API 服务。
API 预测
这里,我们可以用 Byzer 的 Shell 插件来使用 curl 来进行预测:
!sh curl -XPOST 'http://192.168.3.14:9003/model/predict'
-d 'dataType=row&sql=select tax_trip_model_predict(vec_dense(slice(from_json(get_json_object(string(rest_request("http://192.168.3.14:9080/dbs/demo_db/deployments/demo","POST", map("body","{\"input\":[[\"id0376262\",1,1467302350000,1467304896000,2,-73.873093,40.774097,-73.926704,40.856739,\"N\",1]]}"),map("Content-Type" , "application/json"),map())),"$.data.data[0]"),"array<double>"),2,12))) as tax_duration&data=[{doc:[]}]';执行结果:

随意给一条数据,就能预测出租车的时间了。
总结
通过整合 Byzer 和 OpenMLDB,我们不但能实现端到端的机器学习流程,同时还能完成实时特征工程,而且整个流程操作起来简单高效。Byzer+OpenMLDB,未来前景不可限量。
相关链接
OpenMLDB github 主页: https://github.com/4paradigm/OpenMLDB
OpenMLDB 微信交流群









