

本文整理自 OpenMLDB Meetup No.5 中 OpenMLDB PMC 邓龙的演讲。本文深入解析 OpenMLDB 架构设计背后的硬核技术,带领大家了解 OpenMLDB 毫秒级实时在线特征计算引擎内部实现。
分享视频如下:
视频链接:https://www.zhihu.com/zvideo/1537772166535331840
接下来作者将从“OpenMLDB 整体架构”、“在线实时 SQL 执行引擎和存储引擎”、“在线引擎性能测试”三个板块为大家介绍 OpenMLDB 毫秒级的实时在线特征计算引擎。
一、OpenMLDB 整体架构
1.1 OpenMLDB 是线上线下一致的生产级特征平台
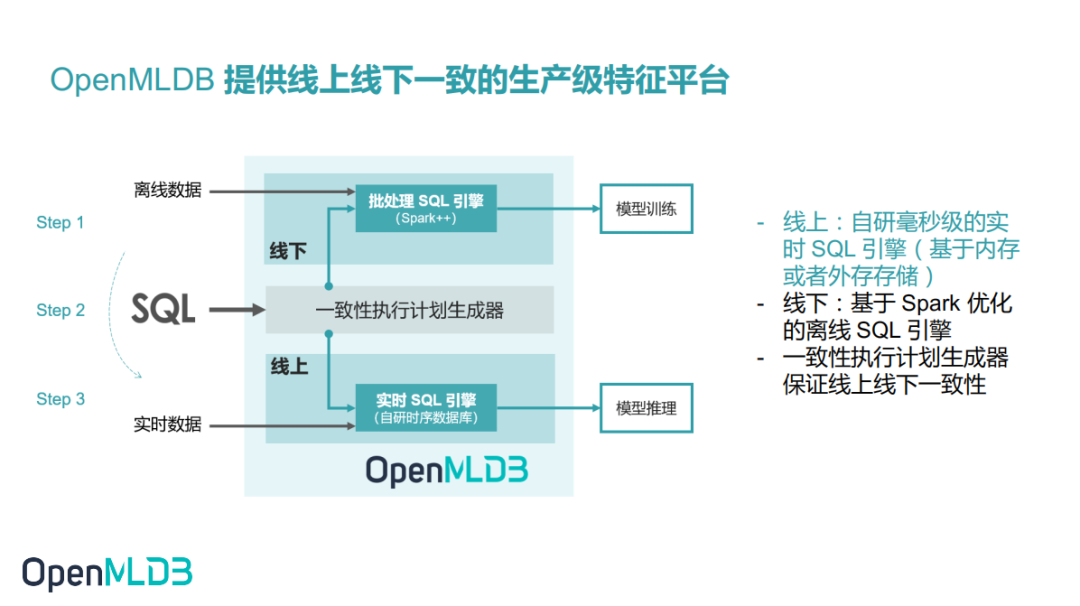 OpenMLDB 是一个提供线上线下一致性的生产级特征平台,我们对外提供的是一整套的 SQL 语言。用户可以通过 SQL 语言写成脚本,再用 OpenMLDB 离线引擎做批量计算,进行模型探索。探索完成后,SQL 脚本能直接上线通过 OpenMLDB 的在线实时引擎完成实时特征计算。
OpenMLDB 是一个提供线上线下一致性的生产级特征平台,我们对外提供的是一整套的 SQL 语言。用户可以通过 SQL 语言写成脚本,再用 OpenMLDB 离线引擎做批量计算,进行模型探索。探索完成后,SQL 脚本能直接上线通过 OpenMLDB 的在线实时引擎完成实时特征计算。
在离线部分,OpenMLDB 的离线特征计算引擎是基于 Spark 做了一个改造。Spark 会用 JNI 的方式来调用我们生成的SQL解析执行库。在线部分,我们用自研实时计算引擎来做实时计算。OpenMLDB离线和在线引擎使用同一套一致性执行计划生成器,运行同一套代码,天然保证了线上线下的一致性。
1.2 OpenMLDB 线上引擎整体架构
1.2.1 主要模块
OpenMLDB 线上引擎包含的主要模块有 Apache ZooKeeper, Nameserver 以及 Tablet (Tablet包括SQL Engine 和 Storage Engine)。下图显示了这些模块之间的关系。其中 Tablet 是整个 OpenMLDB 存储和计算的核心模块,也是消耗资源最多的模块。
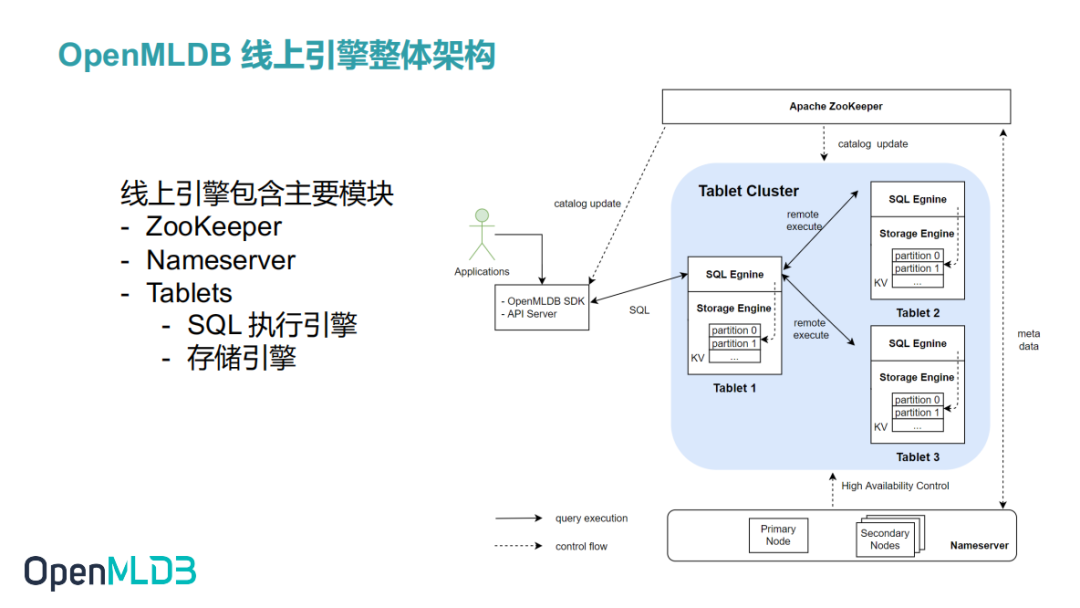
- ZooKeeper 在 OpenMLDB 中用于服务发现和元数据存储和管理功能。ZooKeeper 和 OpenMLDB SDK,Tablet, Namesever 之间都会存在交互。
- Nameserver 主要用来做 Tablet 管理以及故障转移(failover)。当一个 Tablet 节点宕机后,Nameserver 就会触发一系列任务来执行故障转移。当节点恢复后会重新把数据加载到该节点中。同时,为了保证 Nameserver 本身的高可用,Nameserver 在部署时会部署多个实例,并采用primary/secondary 的模式。同一时刻只会有一个 primary 节点。多个 Nameserver 通过 ZooKeeper 实现 primary 节点的抢占。因此,如果当前 primary 节点挂掉,则 secondary 节点会通过 ZooKeeper 重新选出一个 primary 节点。
- Tablet 模块负责执行SQL、存储数据。从功能上看,Tablet包含了 SQL Engine 和 Storage Engine 两个模块。Tablet 也是 OpenMLDB 部署资源时可调配的最小单元。一个 Tablet 不能被拆分到多个物理节点;但是一个物理节点上可以有多个 Tablet。
1.2.2 执行流程
首先,我们会提供一个 OpenMLDB SDK(目前已有Java SDK、Python SDK,Go SDK 正在开发当中)。
当然我们也提供 HTTP 的方式,用 HTTP 的方式需要部署一个 API Server。API Server 里面集成了 OpenMLDB SDK 对 HTTP 请求做转发。
SDK 启动时,会连接到 ZooKeeper ,获取一些信息。例如 Nameserver 和 Tablet 的节点信息,还有表的元数据信息等。
然后 SDK 再依据 SQL 中的信息按照一定策略把请求发送到对应的 Tablet 的节点上。
Tablet 节点收到请求后会通过 SQL 引擎做 SQL 解析,形成分布式的执行计划。这个Tablet 可能会给其他 Tablet 发送子任务。其他Tablet在执行子任务的过程中,会和存储引擎做一些数据的交互,计算完把结果返回到最初的 Tablet 上汇总。
最后把计算结果返回到SDK。
二、在线实时 SQL 执行引擎和存储引擎
2.1 SQL 执行引擎
SQL Engine 负责 SQL 执行 。SQL engine 收到 SQL 查询的请求后的执行过程如下图所示:
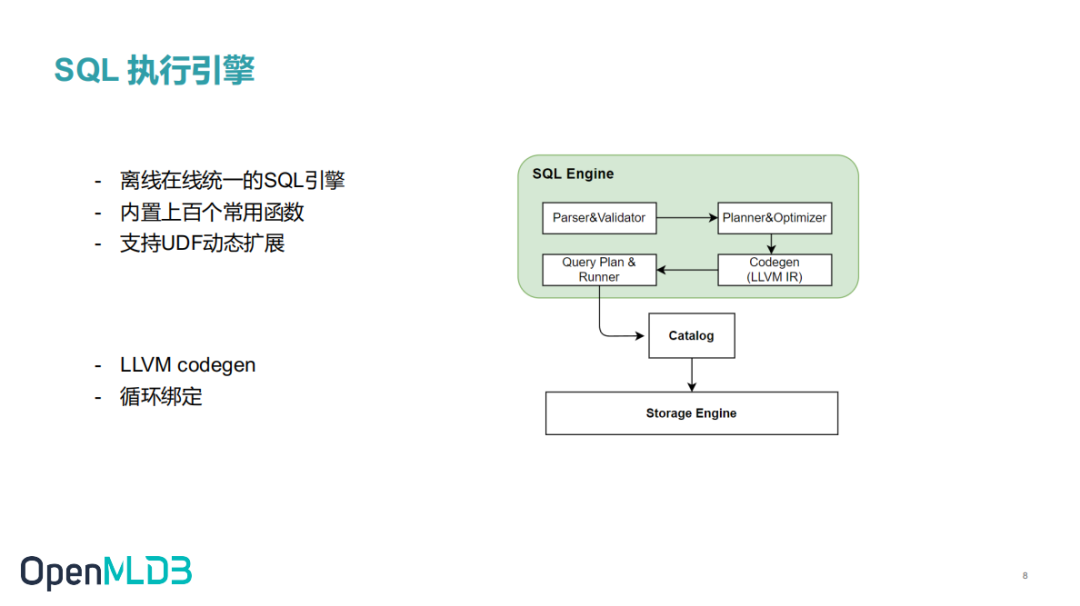
最开始由 Parser 完成 SQL 解析和校验,生成逻辑计划并进行优化。然后 Codegen 生成 LLVM IR,再编译成机器可执行代码。最后生物理执行计划。SQL 引擎基于执行计划,通过 Catalog 获取存储层数据做 SQL 执行运算。
OpenMLDB SQL Engine 提供上百个内置的函数。例如单行的一些函数,对年月日做的简单处理,字符串拼接以及一些聚合函数如sum/avg等等。这些内置函数基本上能满足用户的常用需求。但针对特征逻辑比较复杂的用户场景,我们还提供了 UDF 的方式,用户可以自己实现处理逻辑。目前只支持 C++ 语言。
对 SQL 引擎我们还做了很多优化,如循环绑定和窗口合并。在一个窗口内,可能会有多种聚合的特征,循环绑定只遍历一次窗口数据就会把基于这个窗口的所有聚合特征计算出来,避免多次遍历提高执行效率。窗口合并是指如果多个窗口使用相同的partition by 列和 order by 列,只是窗口大小不一样,执行引擎只会把最大的窗口从存储引擎中把数据拉出来,不会多次拉取。
2.2 在线存储引擎

Storage Engine 负责 OpenMLDB 数据的存储,以及高可用相关的功能。OpenMLDB 提供基于内存和基于外存两种存储引擎。自研的内存存储引擎具有低延迟、高并发的优势,可以提供毫秒级的延迟响应,但成本较高。对性能要求不高的用户也可以使用外存存储引擎,成本较低。经测试基于 SSD 成本可下降 75%。两种引擎对于上层业务代码无感知,可以零成本随意切换。
2.3 内存存储引擎核心数据结构
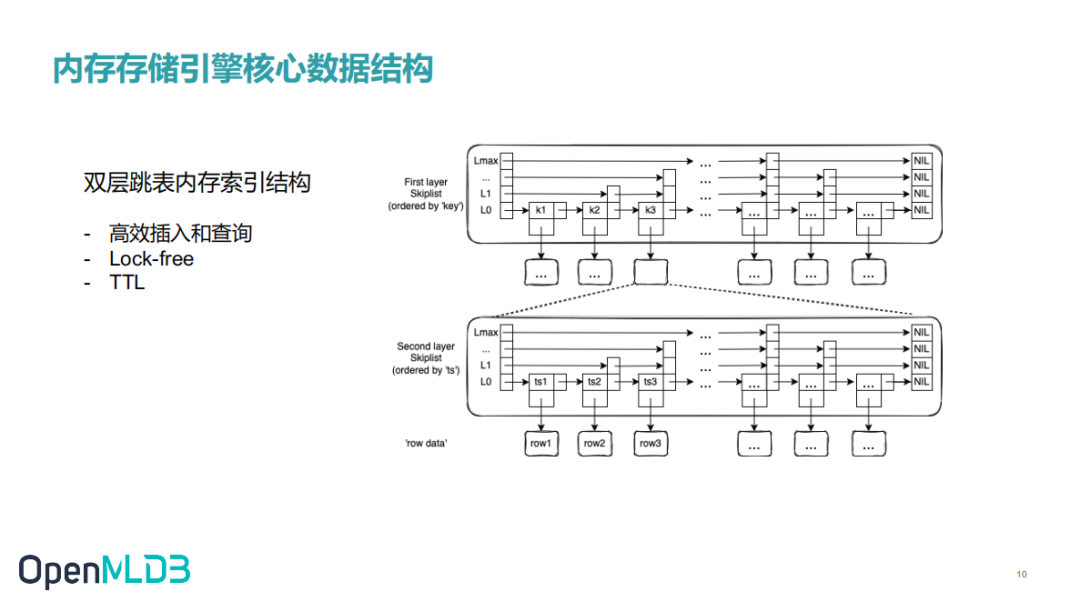
OpenMLDB 内存存储引擎的核心数据结构是一个双层跳表。这里使用跳表是因为跳表拥有良好的查询和插入性能。跳表本身是一个链表结构,这样就很容易实现成lock free,提高性能。而且跳表做 TTL 也非常便捷,只需要修改下对应节点指针。
在第一层跳表中key是对应索引列的值,value指向二级跳表。二级跳表中的key是时间戳,value是一行数据编码后的值。二级跳表是按时间排好序的,这样就很容易查询一段时间内的数据。
2.4 外存存储数据模型——基于 RocksDB
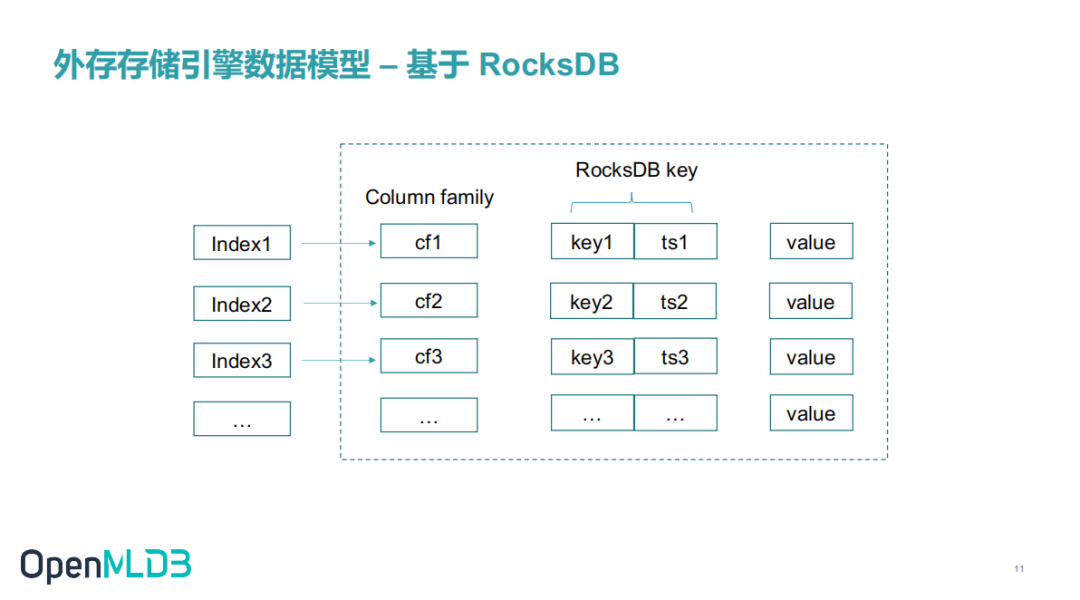
基于 RocksDB 优秀的性能表现以及丰富的功能,OpenMLDB 外存存储引擎选择基于 RocksDB 存储。在OpenMLDB创建表时会基于创建指定多个索引。这里每一个索引就会对应一个 Column family。不同的 Column family 会有单独的 SST 文件和单独的数据淘汰策略,但是它们共享一个 Memory Table。一个 key 和一个 ts 会拼接起来形成 RocksDB 的一个 key。RocksDB 内部 key 是排好序的,这样相同的 OpenMLDB key的数据就会挨在一起 ,方便做一段时间内的数据查询。
2.5 高效的编解码格式
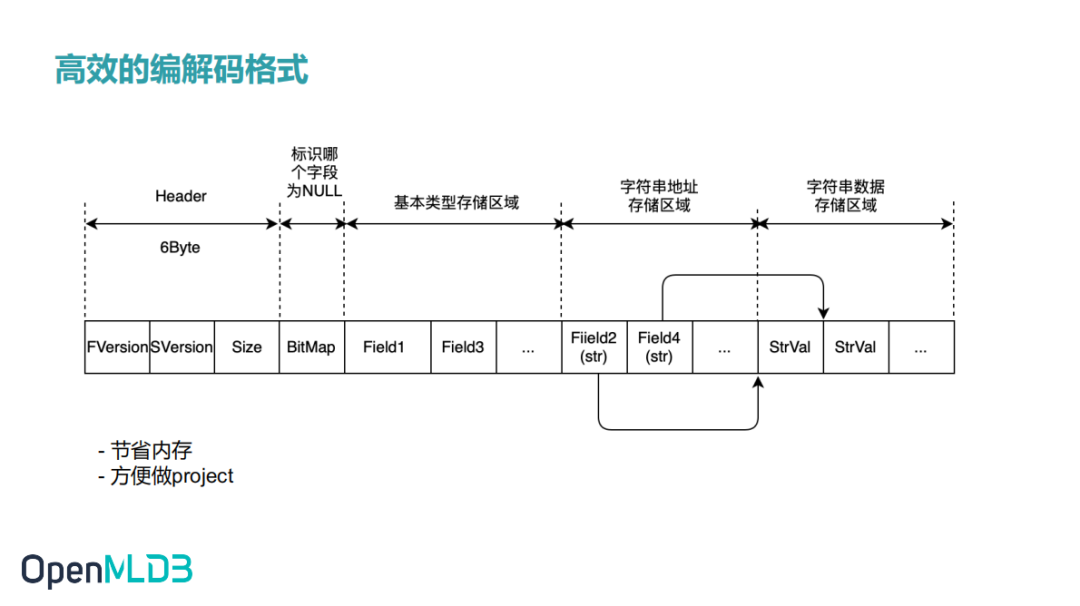
因为我们存储引擎是全部放在内存里边,所以对数据的内存比较敏感,我们设计了一套更高效的编解码方式。FVersion 表示数据编码格式版本号, 占用一个字节。如果编码方式做修改,版本号会加 1。不同的版本号对应不同的编解码方案。SVersion 表示 schema 的版本号, 占用一个字节。增加和删除字段版本号都会加 1。Size 表示整条数据大小, 占用四个字节。BitMap 表示哪个字段为 NULL,如果 schema 字段数为 N, 占用长度为: (N+7) / 8。基本类型存储区域存放 bool/int8/int16/int32/int64/float/double 类型的字段。字符串地址存储区域存储字符串的实际位置,字符串数据存储区域存储的是字符串实际内容。
2.6 数据分片
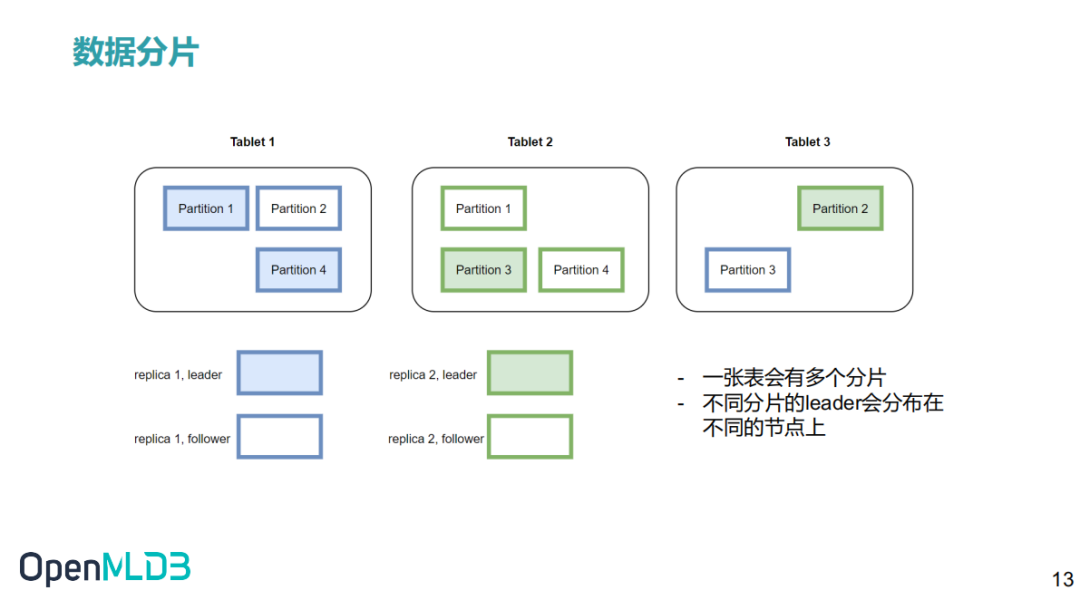
OpenMLDB 集群版是一个分布式的数据库,一张表的数据会进行分片,并且建立多个副本,最终分布在不同的节点中。这里展开说明两个重要的概念:副本和分片。
- 副本(replication):为了保证高可用以及提升分布式查询的效率,数据表将会被存放多个拷贝,这些拷贝就叫做副本。
- 分片(partition):一张表(或者具体为一个副本)在具体存储时,会进一步被切割为多个分片用于分布式计算。分片数量可以在创建表时指定,但是一旦创建好,分片数就不能动态修改了。分片是存储引擎主从同步以及扩缩容的最小单位。一个分片可以灵活的在不同的 tablet 之间实现迁移。同时一个表的不同分片可以并行计算,提升分布式计算的性能。OpenMLDB 会使得每一个 tablet 上的分片数目尽量平衡,以提升系统的整体性能。一张表的多个分片可能会分布在不同 tablet 上,分片的角色分为主分片(leader)和从分片(follower)。当获得计算请求时,请求将会被发送到数据对应的主分片上进行计算;从分片用于保证高可用性。
如上图显示了一个数据表,在两个副本的情况下,在三个 Tablet 上的存储布局。实际使用中,如果某一个或者几个 tablet 的负载过高,可以基于分片,进行数据迁移,来改善系统的负载平衡和整体的吞吐。
2.7 主从同步
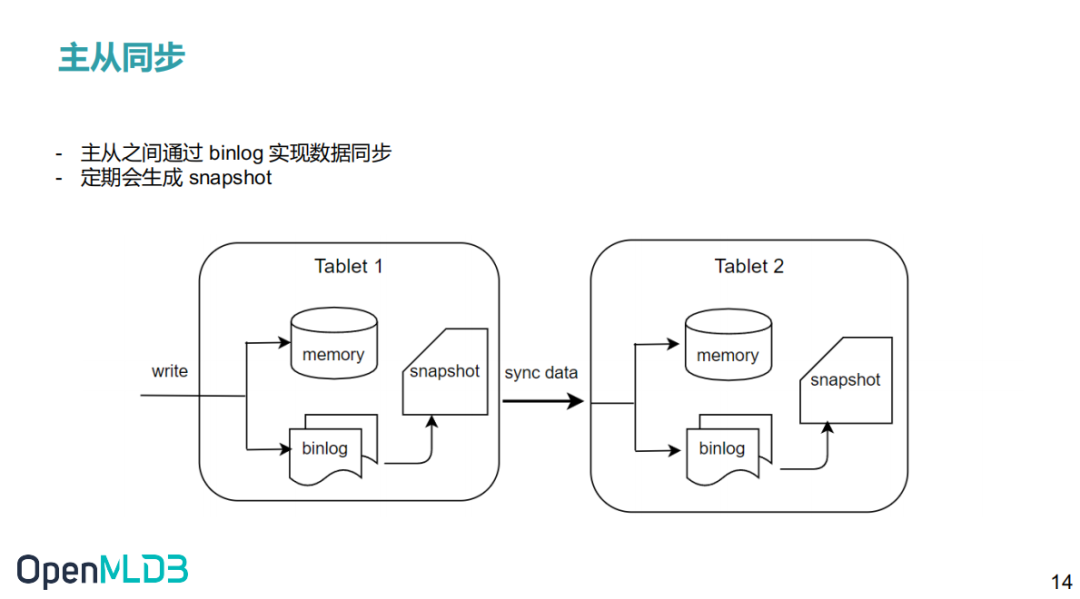
目前版本的 OpenMLDB 的在线数据全部保存在内存中,为了实现高可用会把数据通过 binlog 以及 snapshot 的形式持久化到硬盘中。
如上图所示,服务端收到 SDK 的写请求后会同时写内存和 binlog。binlog 是用来做主从同步的,数据写到 binlog 后会有一个后台线程异步的把数据从 binlog 中读出来然后同步到从节点中。从节点收到同步请求后同样进行写内存和 binlog操作。Snapshot 可以看作是内存数据的一个镜像,不过出于性能考虑,snapshot 并不是从内存 dump 出来,而是由 binlog 和上一个 snapshot 合并生成。在合并的过程中会删除掉过期的数据。OpenMLDB会记录主从同步和合并到 snapshot 中的 offset, 如果一个 binlog 文件中的数据全部被同步到从节点并且也合并到了 snapshot 中,这个 binlog 文件就会被后台线程删除。
2.8 预聚合技术
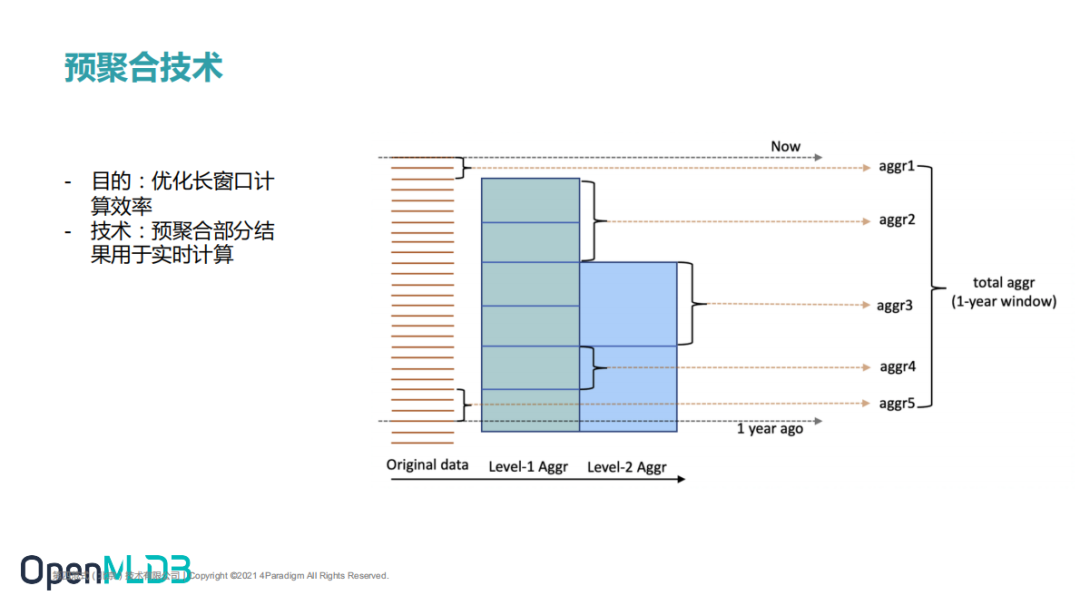
某些场景中,时间窗口内的数据量比较大,可能达到上百万条,那么用实时计算的方式来计算特征,性能会急剧下降,可能达到了几百毫秒甚至秒级的延时。所以我们用预聚合技术,针对长时间窗口、大数据量做一些优化,提升在线计算的性能。预聚合会按照设定的预聚合窗口提前聚合计算,当 SQL 上线之后,会做预聚合表的 初始化。当数据插入进来的话,我们会自动判断这条数据所在表有无关联预聚合表,若有关联,则会更新预聚合表。目前这块是同步计算,可能对性能会有一定的影响,后续会做成异步更新。
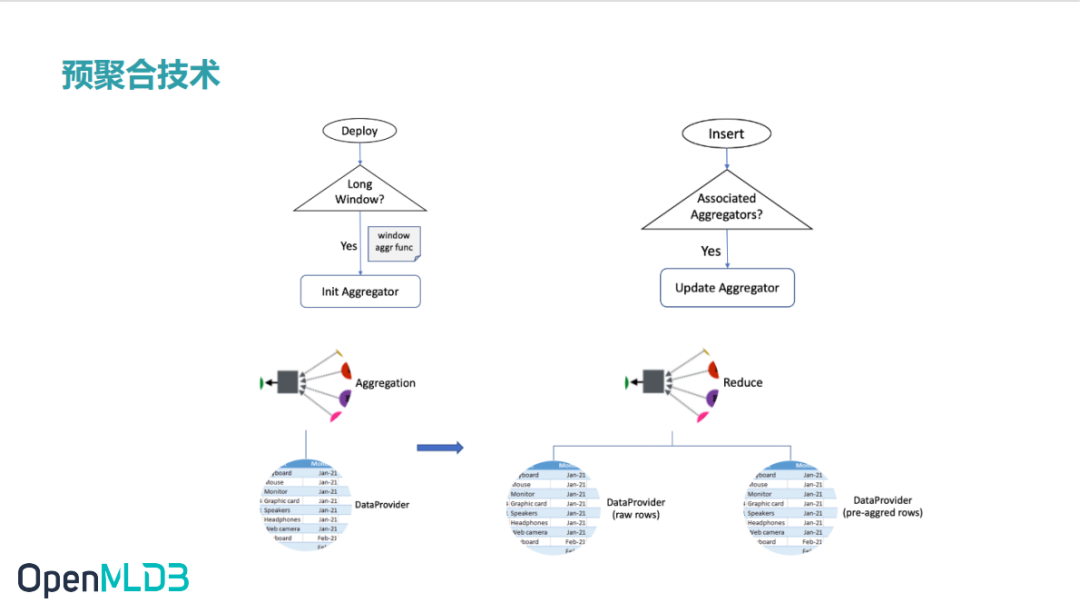
当收到读取请求时,OpenMLDB 会判断这个请求是否为长窗口优化,若是那我们可以从这个长窗口边界把原始数据拿取出来,通过这个已经预聚合的数据计算得到结果。因为窗口中数据已经提前算好了,所以性能肯定会有大幅的提升。
三、在线引擎性能测试
3.1 OpenMLDB 是线上线下一致的生产级特征平台
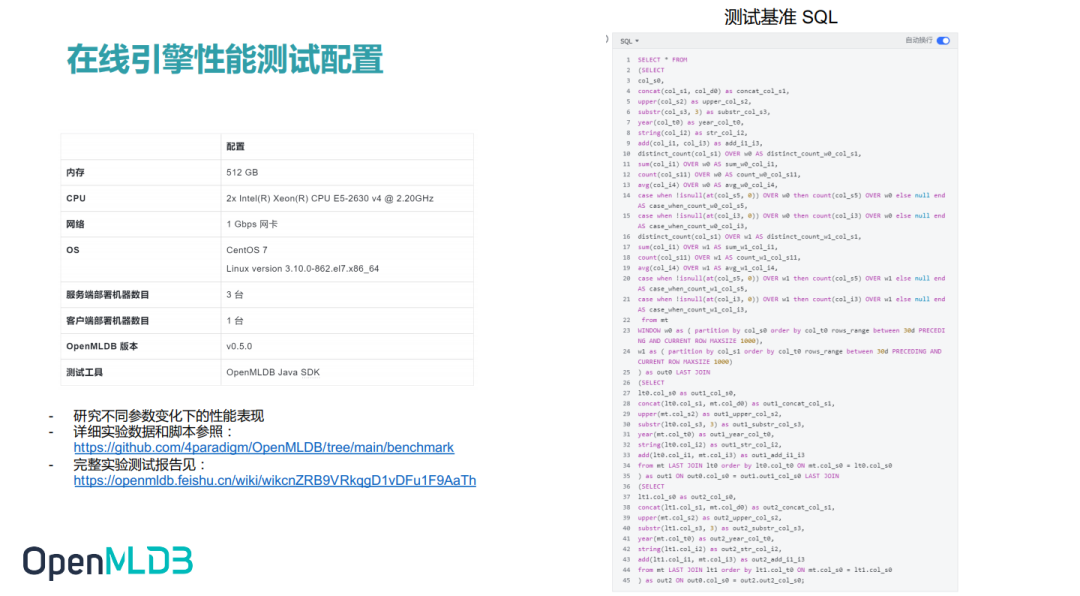
测试场景配置如图所示。右侧的 SQL 里边有两个窗口,分别定义了 WINDOW1 和 WINDOW2,也有两个 last join,在接下来的性能测试展示中会对窗口做一些预聚合的操作,以及基础的特征计算。
3.2 变化 Window 数目以及 LAST JOIN 数目
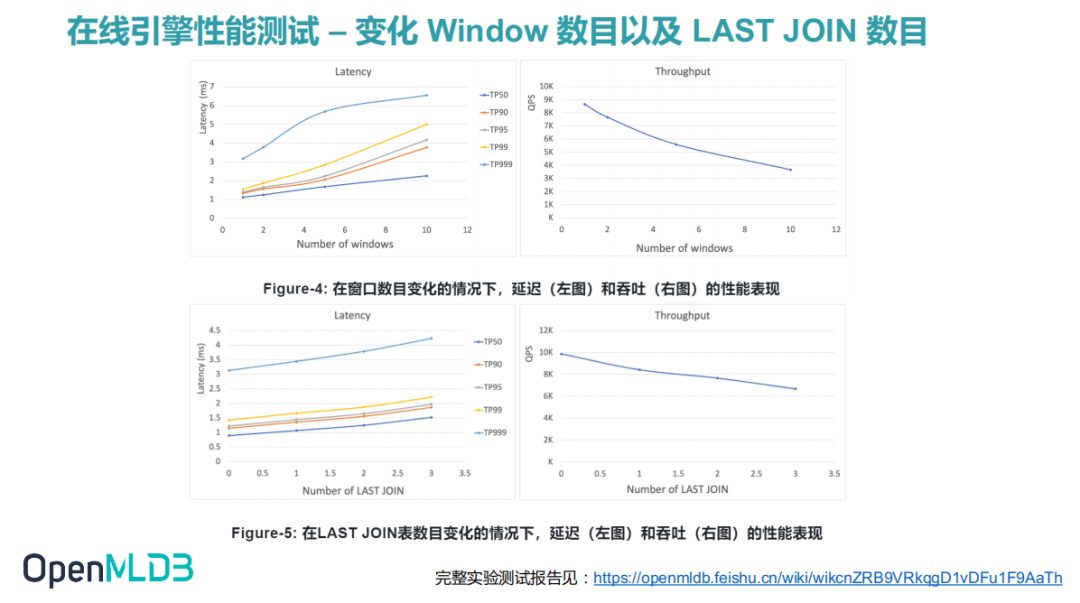
上图中我们能看到不同窗口的性能表现。左上图展示了随着窗口的大小的增大,Latency 也会有相应的一个提升。因为窗口变多,那么数据请求和特征计算也会占用更多的资源,消耗更多的时间。即使到达十个窗口, TP999 延迟也在 七毫秒 以内。右上图展示了吞吐量随窗口的变化。
下半部分的两张图展示的是 LAST JOIN 表个数对 OpenMLDB 的延迟和吞吐的影响。左下图可见随着 LAST JOIN 个数增加,Latency 也是会有缓慢的一个上升,当然这里的上升并不明显,而吞吐性能也能得到相应下降。
3.3 变化窗口内数据条数和索引列基数
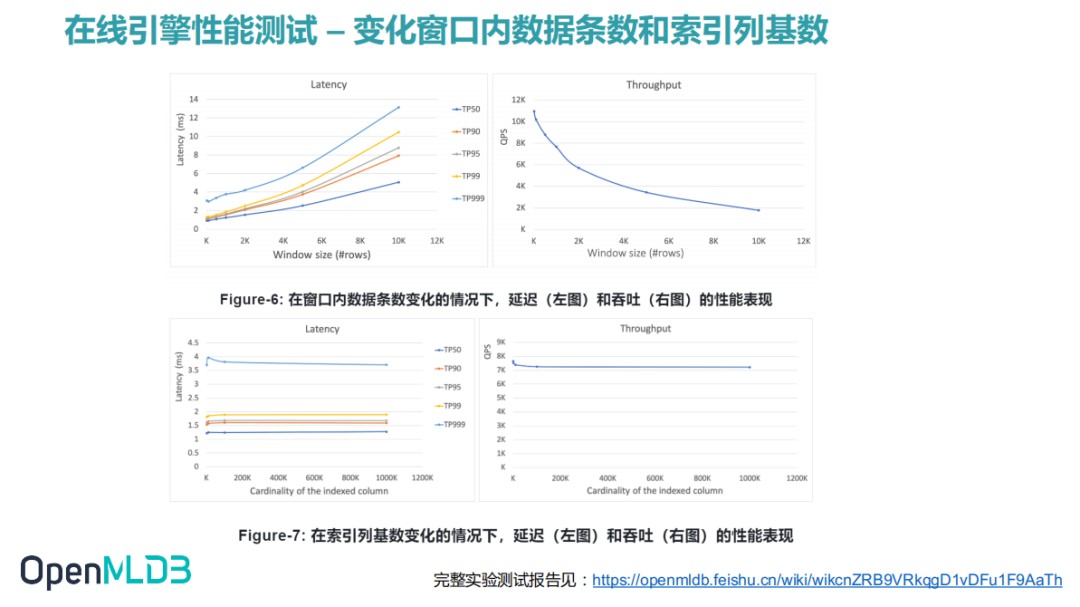
在窗口大小为两千的时候,延迟大概是在四毫秒左右,当窗口上升到了一万的时后,延迟超过十毫秒以上了。大部分情况下能将延迟控制延迟在十毫秒内。
索引列基数变化对性能基本上没什么影响。
3.4 长窗口优化
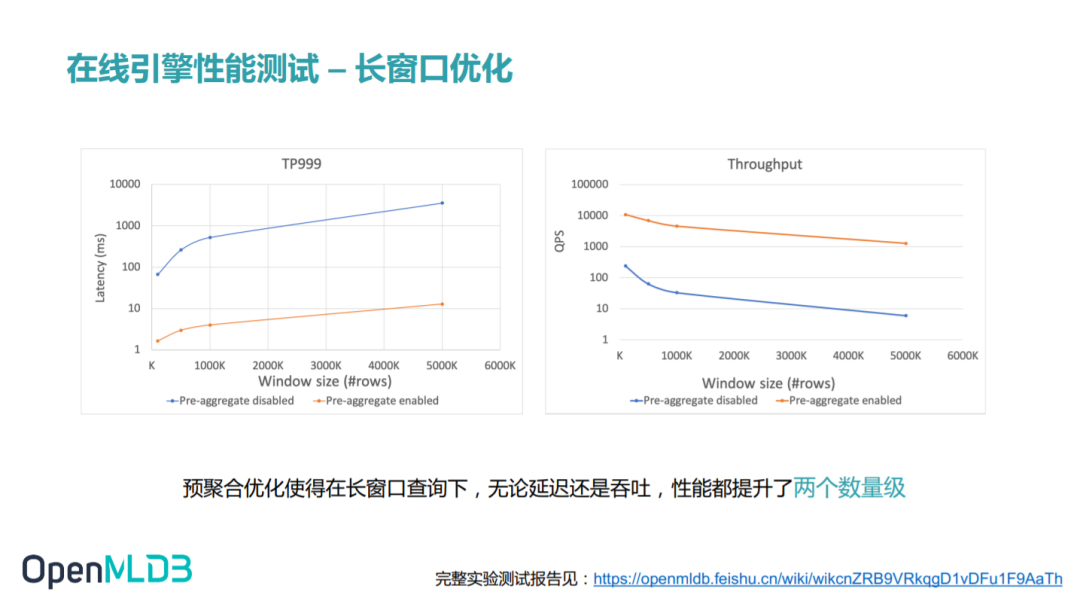
在使用了预聚合优化技术后,长窗口的查询无论是延迟还是吞吐都得到了两个数量级的性能提升。
写在最后
希望本文能够帮大家 OpenMLDB 快速理解掌握如何使用
如果想进一步了解 OpenMLDB 或者参与社区技术交流,可以通过以下渠道获得相关信息和互动~
Github: https://github.com/4paradigm/OpenMLDB
Email: contact@openmldb.ai
OpenMLDB 微信交流群:









