

选择 OpenMLDB
OpenMLDB 提供生产级 FeatureOps 全栈解决方案
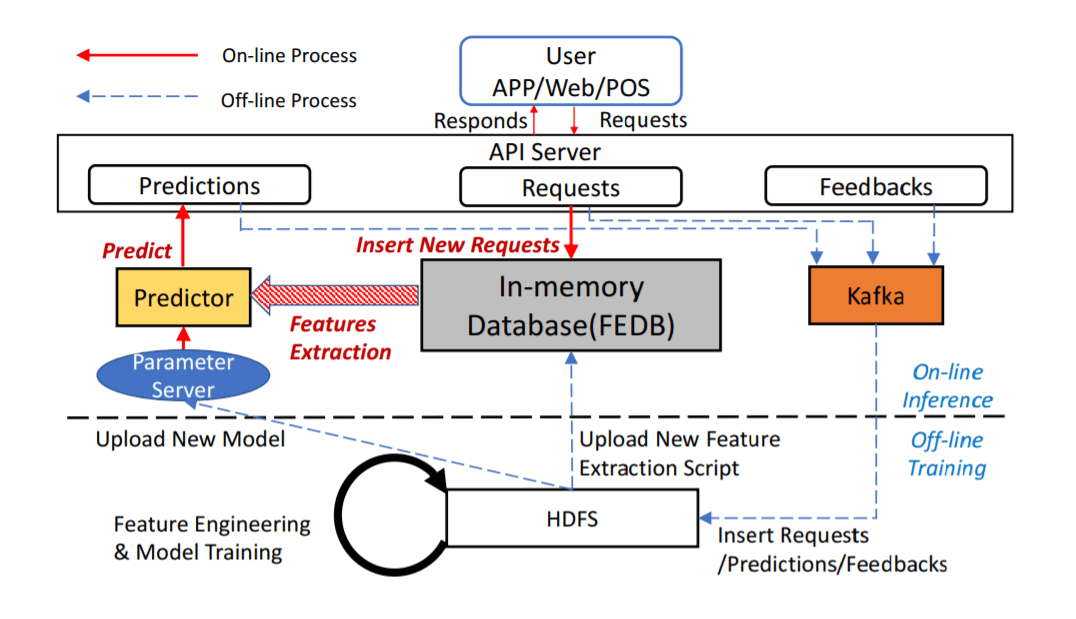
以 SQL 为核心的开发和管理体验
低门槛且功能强大的数据库开发体验,全流程基于 SQL 进行特征计算脚本开发以及部署上线
线上线下一致性执行引擎
离线和实时特征计算使用统一的计算执行引擎,线上线下一致性得到了天然保证
面向特征计算的定制化优化
离线特征计算提供基于源代码优化的Spark高性能版本,线上实时特征计算在高吞吐压力下的复杂查询提供几十毫秒量级的延迟,充分满足高并发、低延迟的性能需求
生产级特性
为大规模企业应用而设计,整合诸多生产级特性,包括灾备恢复、高可用、可无缝扩缩容、可平滑升级、可监控、异构内存架构支持等
应用场景
OpenMLDB在实际场景中高效驱动AI应用落地
查看更多

场景驱动的特征计算方式 OpenMLDB,高效实现“现算现用”
在特征计算系统的实现上,Akulaku 采用场景驱动方式,通过使用 OpenMLDB,更加高效地实现特征“现算现用”。

OpenMLDB 在 37 手游特征计算场景中的应用
本文整理自 37 手游技术主管彭佳铭和高级算法工程师左伟健在 OpenMLDB Meetup No.6 中的分享 ——《OpenMLDB 在 37 手游特征计算场景中的应用》。

如何选择架构中的底层工具?OpenMLDB 在 Akulaku 数据驱动中的应用实践给你答案
本文整理自第四范式技术日中 Akulaku 算法总监马宇翔在「高效落地AI工具链及开源生态」分论坛的演讲。
OpenMLDB介绍视频
新闻资讯

OpenMLDB荣登ACM旗舰期刊
2023-07-26
日前,最新一期的ACM(国际计算机学会)旗舰期刊《Communications of the ACM》(ACM 通讯) 刊登了开源机器学习数据库项目 OpenMLDB 的文章,获得了期刊编辑主席团的一致认可。

第四范式获信通院尖峰开源项目及开源人物双料大奖
2022-05-05
2021年9月17日,在中国信息通信研究院(以下简称“信通院”)、中国通信标准化协会联合主办的“2021 OSCAR 开源产业大会"上,第四范式荣获“OSCAR尖峰开源案例”双料大奖——开源机器学习数据库OpenMLDB斩获“开源社区及开源项目”奖项,第四范式基础架构负责人郑曌作为OpenMLDB等开源项目发起人成功当选“开源人物”。
英特尔和第四范式联合研究成果入选国际顶会 VLDB 2021
2021-01-08
基于持久内存优化的AI实时决策系统数据库OpenMLDB(论文标题:Optimizing In-memory Database Engine for AI-powered On-line Decision Augmentation Using Persistent Memory),被国际顶级数据库学术会议VLDB(Very Large Data Base)作为常规研究论文录取。论文以解决在线预估系统的业务需求和痛点为目的,针对如何设计底层数据库组件来高效支撑万亿维稀疏特征在线预估系统,以及如何基于英特尔®傲腾™持久内存进一步解决业务和系统设计的痛点等两方面进行创新性设计和全面优化。
FAQ
主要使用场景是什么?
目前主要面向人工智能应用,提供高效的线上线下一致性的特征平台,特别针对实时特征需求做了深度优化,达到毫秒级的计算延迟。此外,OpenMLDB 本身也包含了一个高效且功能完备的时序数据库,使用于金融、IoT、数据标注等领域。
OpenMLDB 是如何发展起来的?
OpenMLDB 起源于领先的人工智能平台提供商第四范式的商业软件。其研发团队在 2021 年将商业产品中作为特征工程的核心组件进行了抽象、增强、以及社区友好化,将它们形成了一个系统的开源产品,以帮助更多的企业低成本实现人工智能转型。在开源之前,OpenMLDB 已经作为第四范式的商业化组件之一在上百个场景中得到了部署和上线。
OpenMLDB 是否是一个 feature store?
OpenMLDB 认为是目前普遍定义的 feature store 类产品的一个超集。除了可以同时在线下和线上供给正确的特征以外,其主要优势在于提供毫秒级的实时特征。我们看到,今天在市场上大部分的 feature store 是将离线异步计算好的特征同步到线上,但是并不具备毫秒级的实时特征计算能力。而保证线上线下一致性的高性能实时特征计算,正是 OpenMLDB 所擅长的场景。
OpenMLDB 为什么选择 SQL 作为开发语言?
SQL 具备表达语法简洁且功能强大的特点,选用 SQL 和数据库开发体验一方面降低开发门槛,另一方面更易于跨部门之间的协作和共享。此外,基于 OpenMLDB 的实践经验表明,经过优化过的 SQL 在特征计算的表达上功能完备,已经经历了长时间的实践考验。








