

文章目录
收起
 导读:今天我们将从线上线下一致的生产级特征计算平台这个点切入,从「人工智能工程化落地过程中企业面临的数据和特征挑战」 ,「OpenMLDB:线上线下一致性的生产级特征计算平台」,「拥抱开源、面向社区」三个方面介绍开源机器学习数据库 OpenMLDB。
导读:今天我们将从线上线下一致的生产级特征计算平台这个点切入,从「人工智能工程化落地过程中企业面临的数据和特征挑战」 ,「OpenMLDB:线上线下一致性的生产级特征计算平台」,「拥抱开源、面向社区」三个方面介绍开源机器学习数据库 OpenMLDB。  希望这场分享能够帮助大家了解 OpenMLDB 是什么,能做什么,适用于哪些场景。同时本文也将首次介绍 OpenMLDB的使用场景和生态构建。
OpenMLDB使用场景:覆盖离线开发到实时线上计算的完整流程,满足高计算性能需求和实时计算需求,同时也满足纯离线开发及实时线上计算需求。
OpenMLDB生态构建:加速链接DataOps(Pulsar、Kafka等)、ModelOps(TensorFlow、PyTorch、LightGBM等) ,无阻对接ProductionOps(Airflow、DolphinScheduler等) ,围绕OpenMLDB构建面向机器学习应用及上线全流程的上下游生态。
介绍一下我自己,我叫卢冕,目前在第四范式担任系统架构师,主要负责数据库团队和高性能计算团队,同时也是开源项目 OpenMLDB 的主要研发负责人,目前主要专注于数据库系统和异构计算。
希望这场分享能够帮助大家了解 OpenMLDB 是什么,能做什么,适用于哪些场景。同时本文也将首次介绍 OpenMLDB的使用场景和生态构建。
OpenMLDB使用场景:覆盖离线开发到实时线上计算的完整流程,满足高计算性能需求和实时计算需求,同时也满足纯离线开发及实时线上计算需求。
OpenMLDB生态构建:加速链接DataOps(Pulsar、Kafka等)、ModelOps(TensorFlow、PyTorch、LightGBM等) ,无阻对接ProductionOps(Airflow、DolphinScheduler等) ,围绕OpenMLDB构建面向机器学习应用及上线全流程的上下游生态。
介绍一下我自己,我叫卢冕,目前在第四范式担任系统架构师,主要负责数据库团队和高性能计算团队,同时也是开源项目 OpenMLDB 的主要研发负责人,目前主要专注于数据库系统和异构计算。

1 | 人工智能工程化落地过程中企业面临的数据和特征挑战
首先来看一下背景之一——当前人工智能工程化落地过程中所面对的数据和特征挑战。通过统计数据,我们了解到如今企业在推进人工智能落地的时候,可能会将 95% 的时间都花在数据问题的处理上,数据治理的问题亟待解决。虽然今天我们能在市面上看到非常多的开源或是商业的数据解决方案,例如 Hadoop、MySQL 等已经向大家提供了丰富的解决方案。 但是,在 AI 工程化落地过程当中,这些方案是否已经完全解决了我们所面对的挑战,满足了一切我们所期待的需求?其实目前还是存在很多问题的。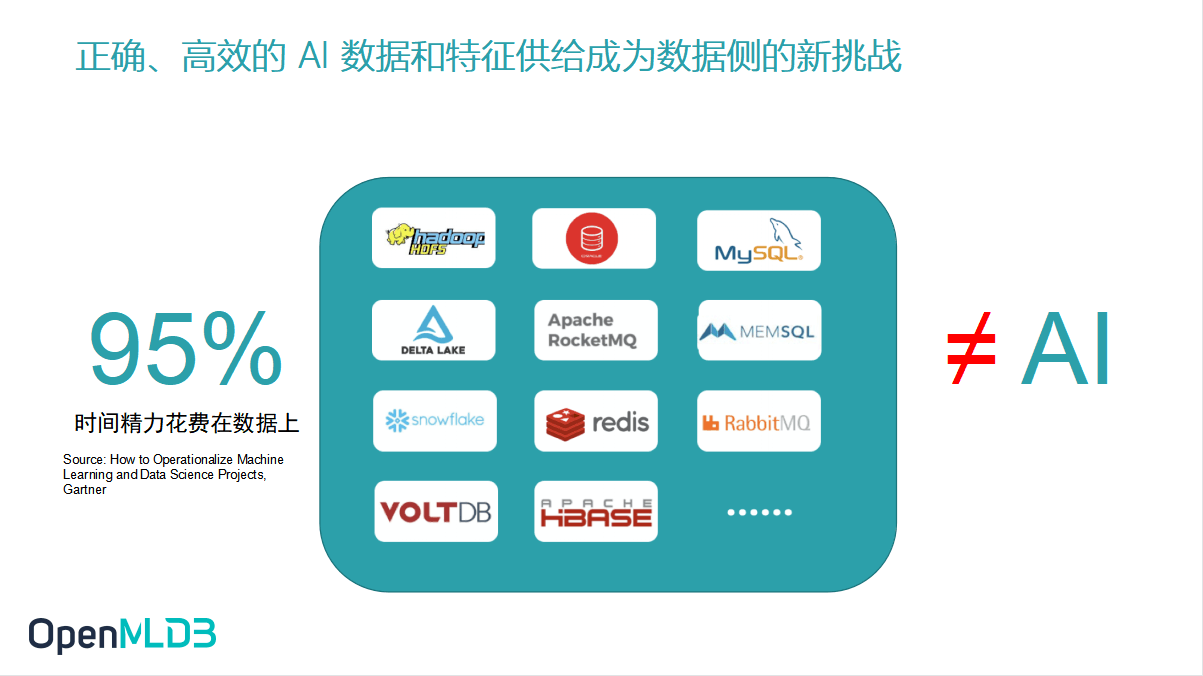
MLOps 完整生命周期
在 AI 工程化落地的这个过程当中,MLOps 成为一个非常流行的概念。相信大家或多或少都对此有些了解。MLOps 概括了人工智能机器学习工程化落地的完整生命周期所需要的一些工具以及服务。
下图展示的是 MLOps 运作的闭环流程,可以看到它会分为离线开发和线上服务两个部分。在机器学习相关的开发中,我们常常会把工作流程拆分为模型的训练和上线,这两套流程存在较大的差异。当我们吧这两套流程放置在企业级的生产场景中,它们可以进一步地拆解为 DataOps、FeatureOps 和 ModelOps。这次分享将集中关注 FeatureOps,谈论如何通过 OpenMLDB 这一个线上线下一致的生产级特征计算平台去解决特征计算、特征存储、线上实时特征计算以及特征服务的问题。
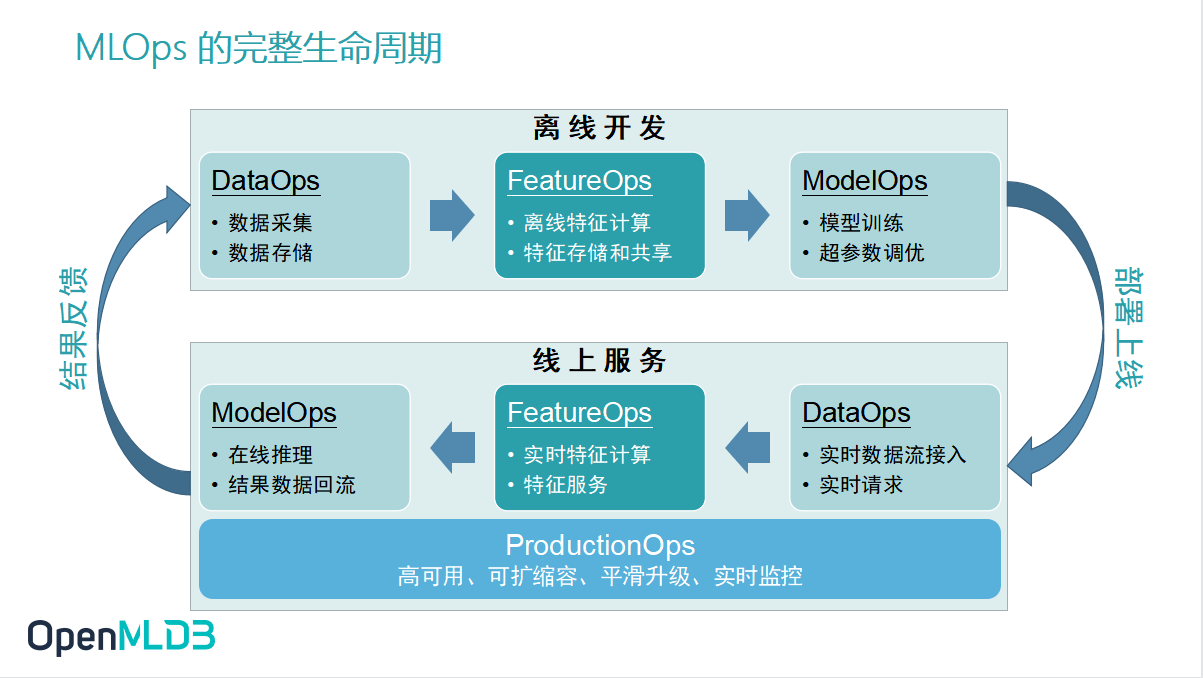 可以注意的是,画面下方线上服务部分这一块还加入了一个环节——ProductionOps,它是企业人工智能工程化落地时一个非常重要的环节。在生产环境之下,企业会非常看重高可用、可扩缩容、平滑升级、实时监控这些企业级核心。所以 ProductionOps 也是我们做 FeatureOps 过程中非常关注的内容。
可以注意的是,画面下方线上服务部分这一块还加入了一个环节——ProductionOps,它是企业人工智能工程化落地时一个非常重要的环节。在生产环境之下,企业会非常看重高可用、可扩缩容、平滑升级、实时监控这些企业级核心。所以 ProductionOps 也是我们做 FeatureOps 过程中非常关注的内容。
面向决策类场景的特征工程
本次内容分享的背景之二是 OpenMLDB 所触发的应用背景。目前 OpenMLDB 面向的主要场景是决策类场景,是基于时序数据的这种特征工程。这里的关键词有三:
- 面向结构化数据和决策类场景
- 处理时序数据
- 基于时间窗口的聚合函数
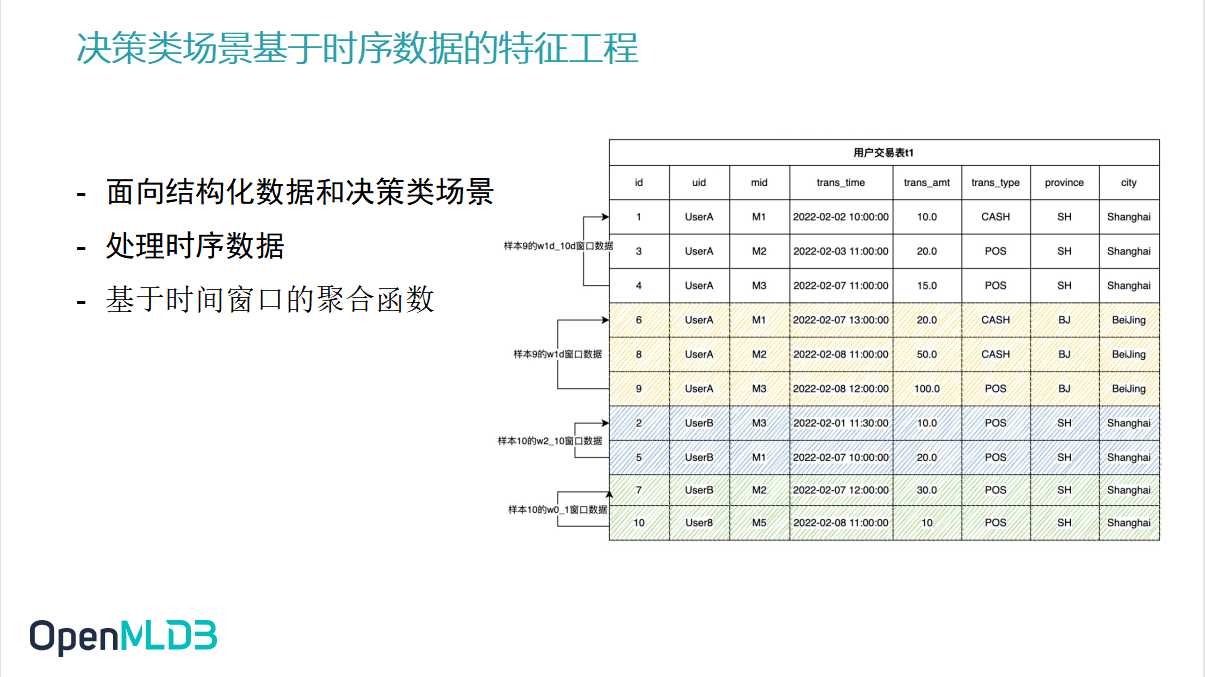 展开说明上述三点。
其中的结构化数据,简单来说指的是表数据。而决策类场景指的是区别于基于深度学习的感知类产品所面向的决策类场景,更多应用于实时推荐系统、风控系统、反欺诈系统等企业业务系统的场景。
所谓的时序数据,就是所有的数据记录都会带有一个时间戳,如图中数据表格里的第四列就包含着时间戳。
在实际生产当中特征工程基本上都是对这种时序数据去做这个时间窗口上的聚合函数,这也是我们处理最多的特征工程。
展开说明上述三点。
其中的结构化数据,简单来说指的是表数据。而决策类场景指的是区别于基于深度学习的感知类产品所面向的决策类场景,更多应用于实时推荐系统、风控系统、反欺诈系统等企业业务系统的场景。
所谓的时序数据,就是所有的数据记录都会带有一个时间戳,如图中数据表格里的第四列就包含着时间戳。
在实际生产当中特征工程基本上都是对这种时序数据去做这个时间窗口上的聚合函数,这也是我们处理最多的特征工程。
生产级特征工程业务需求
下面我们会从业务角度举例,说明生产级特征工程所面向是两大业务需求:
- 线上模型精度符合业务需求
- 特征实时计算,满足低延迟
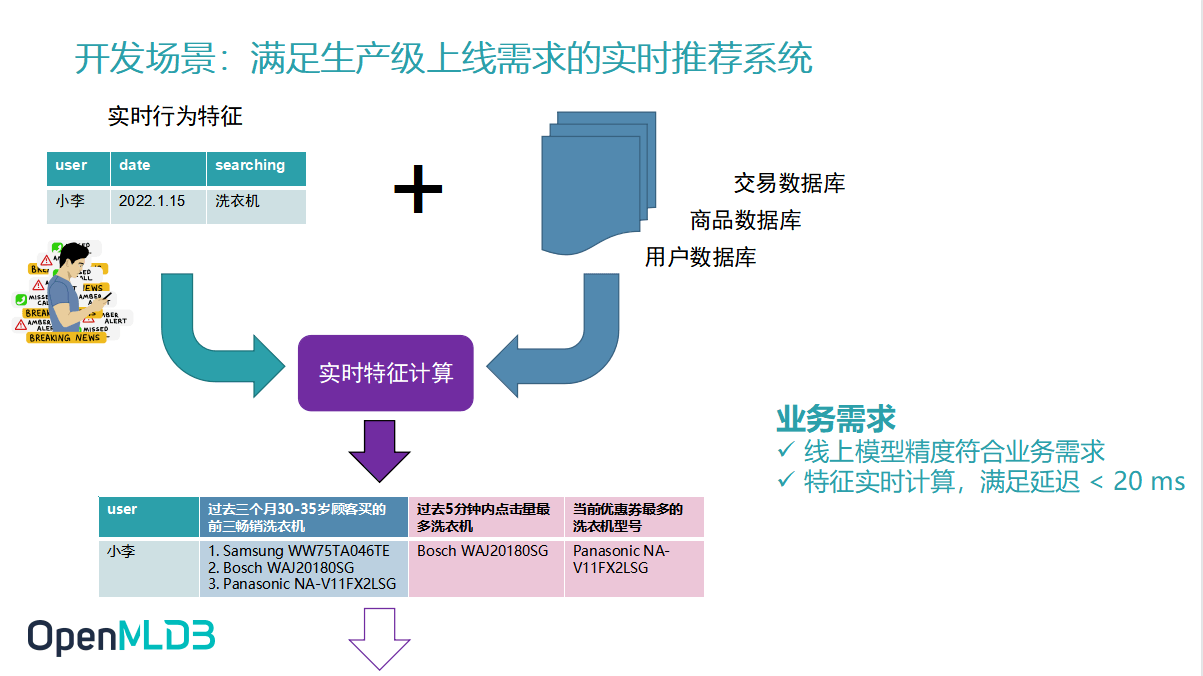 以实时推荐系统为例,比如小李同学,在某个时间点想买洗衣机,去搜索洗衣机,触发了搜索行为以后,后面整个特征计算会做什么?首先进来的实时行为特征,这三个原始的特征就是 User ID,日期以及他在搜索的产品。如果我们只是拿这三个特征去做模型训练和推理,是达不到一个业务需求的模型精度的。
此时我们需要做的是一个特征工程,所谓的特征工程就是我们从数据库里去进一步地拉取一些历史数据,比方说我们从交易数据库、商品数据库、用户数据库去拉取一些历史数据,然后组合、计算,得到一些更完整的更有意义的特征。
图片左下角就是一个实时的特征。假设当前有个主播正在带货,或者网络购物平台正好有一批优惠券正在发放,此时就会存在一个非常实时的特征,比如当前优惠券最多的或者折扣力度最大的洗衣机型号是什么,也可能是过去5分钟内点击量最多的洗衣机是什么,这些特征的计算对实时性的要求非常高。当然抽取的特征中也有一部分特征可能和小李过去的消费行为相结合。比方说小李过去一年买的最多的电子品牌是什么,他的消费平均水平是什么。我们将所有的特征组合起来,衍生出来的新特征,就是通过特征工程(或者叫做特征计算)生产的特征,最后组合成一个完整的特征列表,再将它给到后续的模型预估。
从这个案例我们可以看出,做特征工程包含了非常重要的特征计算步骤。
以实时推荐系统为例,比如小李同学,在某个时间点想买洗衣机,去搜索洗衣机,触发了搜索行为以后,后面整个特征计算会做什么?首先进来的实时行为特征,这三个原始的特征就是 User ID,日期以及他在搜索的产品。如果我们只是拿这三个特征去做模型训练和推理,是达不到一个业务需求的模型精度的。
此时我们需要做的是一个特征工程,所谓的特征工程就是我们从数据库里去进一步地拉取一些历史数据,比方说我们从交易数据库、商品数据库、用户数据库去拉取一些历史数据,然后组合、计算,得到一些更完整的更有意义的特征。
图片左下角就是一个实时的特征。假设当前有个主播正在带货,或者网络购物平台正好有一批优惠券正在发放,此时就会存在一个非常实时的特征,比如当前优惠券最多的或者折扣力度最大的洗衣机型号是什么,也可能是过去5分钟内点击量最多的洗衣机是什么,这些特征的计算对实时性的要求非常高。当然抽取的特征中也有一部分特征可能和小李过去的消费行为相结合。比方说小李过去一年买的最多的电子品牌是什么,他的消费平均水平是什么。我们将所有的特征组合起来,衍生出来的新特征,就是通过特征工程(或者叫做特征计算)生产的特征,最后组合成一个完整的特征列表,再将它给到后续的模型预估。
从这个案例我们可以看出,做特征工程包含了非常重要的特征计算步骤。
特征平台开发上线生命周期
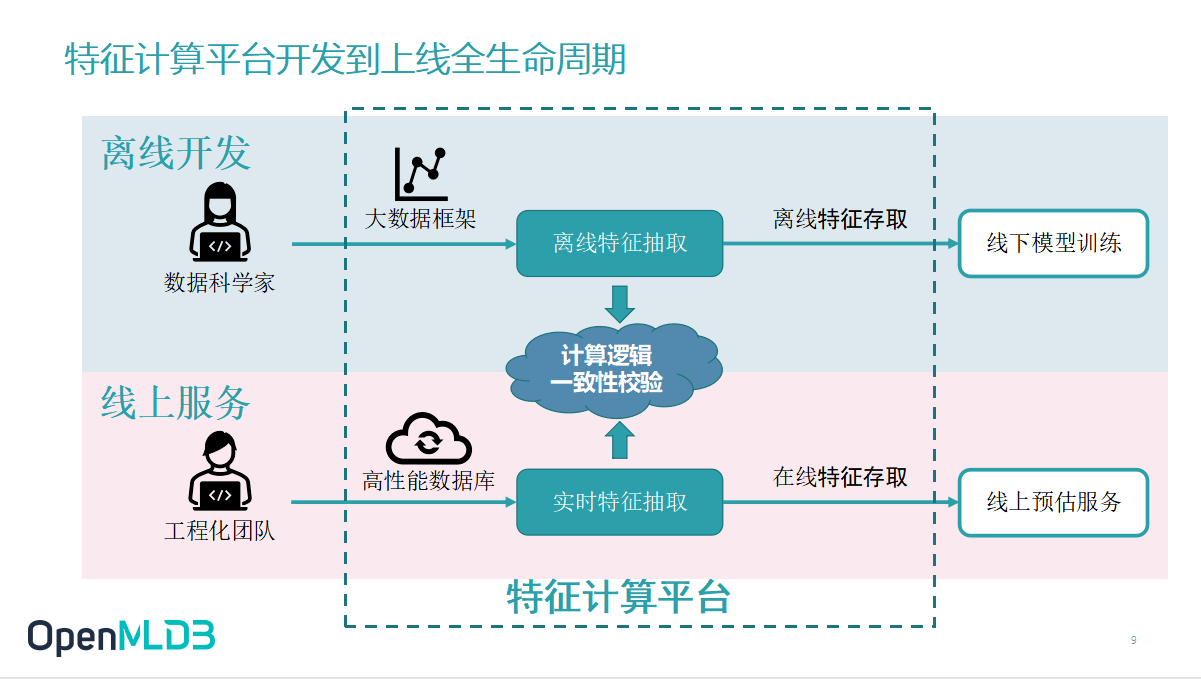 在这两个业务需求之下,特征计算平台从开发到上线的全生命周期是如何完成的呢?
一开始入场的是数据科学家,他们会根据历史数据和业务精度的要求建立一个离线的业务模型,在此过程中设计离线特征脚本。这个特征脚本就是前面提到的过去一段时间内的点击量的特征等等。要如何去抽取这些特征,要定义哪些特征,判断不同的场景中需要开发何种特征脚本是数据科学家的工作,而在这个过程中大部分数据科学家喜欢使用的语言是 Python,一部分科学家也有可能用到 SparkSQL。
对于数据科学家而言,主要任务就是开发出高质量模型,并通过数据验证测试使得最后生成的模型质量是符合预期的。而上线后的工程化需求,例如低延迟、高吞吐、可运维性等等既不在他们的工作职责之内,也不是数据科学家擅长解决的问题。当工作进展到业务上线的部分时,会有工程化团队来负责,并进一步介入 AI 落地。
工程化团队需要去把数据科学家完成的脚本做重构,他们会用一些高性能数据库,甚至用 C++ 重新搭建一套特征抽取的服务,使得上线的产品能够满足业务的实时计算低延迟性能需求。
在这两个业务需求之下,特征计算平台从开发到上线的全生命周期是如何完成的呢?
一开始入场的是数据科学家,他们会根据历史数据和业务精度的要求建立一个离线的业务模型,在此过程中设计离线特征脚本。这个特征脚本就是前面提到的过去一段时间内的点击量的特征等等。要如何去抽取这些特征,要定义哪些特征,判断不同的场景中需要开发何种特征脚本是数据科学家的工作,而在这个过程中大部分数据科学家喜欢使用的语言是 Python,一部分科学家也有可能用到 SparkSQL。
对于数据科学家而言,主要任务就是开发出高质量模型,并通过数据验证测试使得最后生成的模型质量是符合预期的。而上线后的工程化需求,例如低延迟、高吞吐、可运维性等等既不在他们的工作职责之内,也不是数据科学家擅长解决的问题。当工作进展到业务上线的部分时,会有工程化团队来负责,并进一步介入 AI 落地。
工程化团队需要去把数据科学家完成的脚本做重构,他们会用一些高性能数据库,甚至用 C++ 重新搭建一套特征抽取的服务,使得上线的产品能够满足业务的实时计算低延迟性能需求。
线上线下计算逻辑一致性校验
那么是否经过数据科学家和工程化团队的接力开发处理,产品就能完美上线了呢?在实际的工程化落地中,答案是是否定的。因为中间还缺了很重要的一步——线上线下计算逻辑一致性校验。
计算逻辑一致性校验,简单来说就是数据科学家和工程化团队生产的模型的精度需要达成一致。最本质问题在特征计算方面,要保证特征抽取的计算逻辑一致。这个地方大家可能听起来很简单,但实际上做起来是不容易的,对齐联调所需要的人力成本、测试成本和修护成本非常庞大。在我们以往的客户服务实践中,一次性校验往往花费数月甚至接近一年的时间去反复校验。而投入大量成本去反复验证,自然是因为线上线下经常出现不一致性。
线上线下不一致可能的原因
- 工具能力的不一致性。离线开发和线上应用,使用的工具栈和开发栈可能是完全不一样的。
离线开发数据科学家更偏好于像 Python、Spark这种这种工具;做线上应用的时候,讲究高性能、低延迟,就需要用一些高性能的编程语言或者数据库来做。
当我们有两套工具的时候,它们覆盖的功能范围是不一样的,比方说做离线开发的时候,使用的是Python,可以实现很复杂的功能,而线上MySQL的功能就会受限于于SQL。
工具能力的不一致性,就会造成做一些妥协的局面,产生的效果就不同。
- 需求沟通的认知差。这不是一个技术问题,但是在实际工程落地当中非常重要。
这里我们举一个例子,Varo,一家非常有名做线上银行的公司,在美国有很多的用户,他们的工程师提到了需求沟通认知差的问题。关于如何定义account balance,他们就有一个教训。工程化团队认为这个 account balance 即是上线以后实时的账户余额;但是数据科学家团队为了简化,而采用了昨天结束时候的账户余额。很明显两者之间的认知差,就能造成后面的整个训练效果的不一致性,从而导致了他们的应用里出现了非常严重的线上业务问题。其实不光是这家银行,在第四范式整个项目实践的周期经验当中,我们都或多或少都碰到过这种沟通认知差带来的问题。一旦出现这种问题,排查的成本其实还是非常高的。
当然原因是多样的,这里我们只列举了两种最重要的原因。

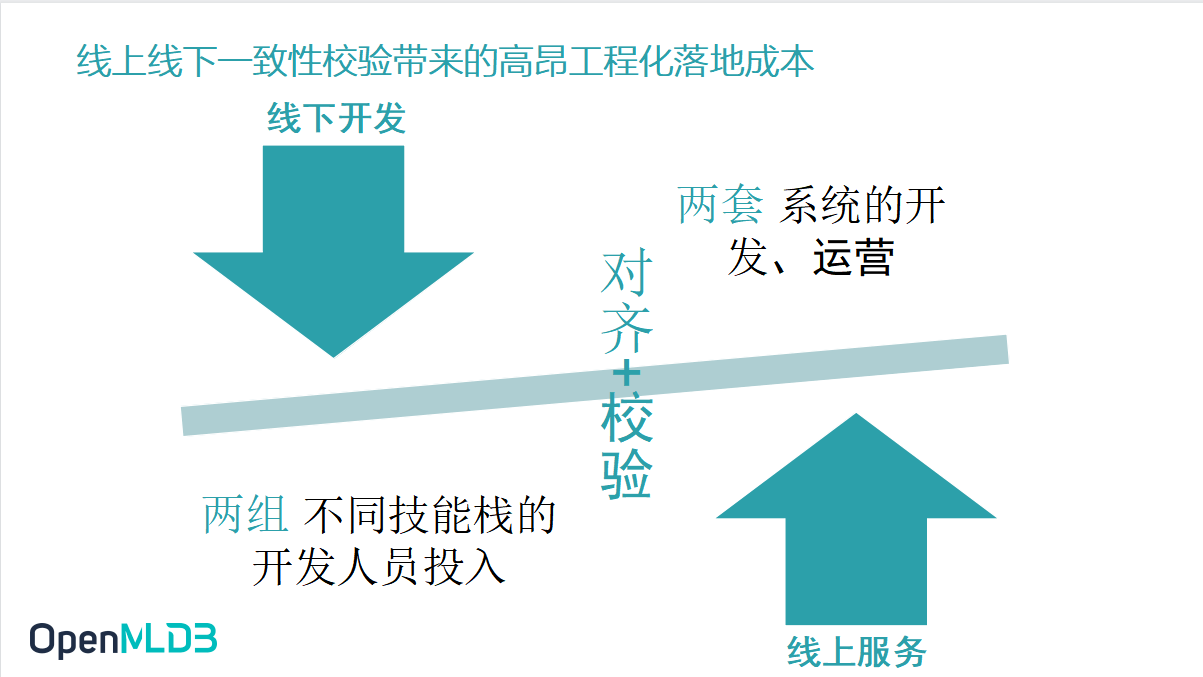
线上线下一致性校验带来的高昂工程化落地成本
因为线上线下的一致性问题的产生,校验是必然的。一次性校验带来了很多成本上的问题:
- 需要两组不同技能栈的开发人员投入,才能去完成从线下到线上的部署的过程。
- 线上线下两套系统的开发和运营。
这两点在工程化落地成本、开发成本、人力成本上面,都有非常大的代价。
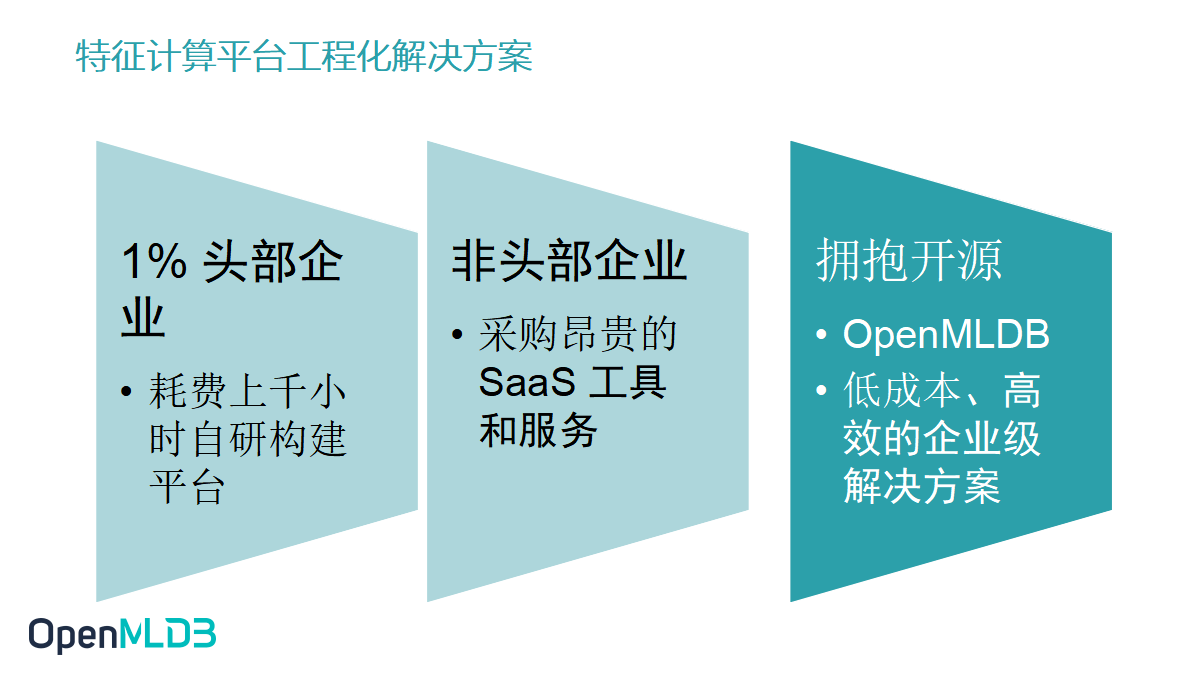
 为了解决这个问题,国内外的头部企业会花费上千个小时自研构建平台保证线上线下一致性,这个平台和企业内部产品是深度耦合的。除了这些有着超强研发能力的头部企业以外,剩下的大部分企业因为投入研发的成本可能比采购的成本更高,更多地会采购一些Saas工具和服务来解决这个问题。
而今天,OpenMLDB 就提供了另外一种可能,我们提供开源的解决方案,提供 FeatureOps 的企业级解决方案,帮助企业去做到低成本高效率地解决痛难点。
为了解决这个问题,国内外的头部企业会花费上千个小时自研构建平台保证线上线下一致性,这个平台和企业内部产品是深度耦合的。除了这些有着超强研发能力的头部企业以外,剩下的大部分企业因为投入研发的成本可能比采购的成本更高,更多地会采购一些Saas工具和服务来解决这个问题。
而今天,OpenMLDB 就提供了另外一种可能,我们提供开源的解决方案,提供 FeatureOps 的企业级解决方案,帮助企业去做到低成本高效率地解决痛难点。
2 | OpenMLDB 为企业提供线上线计算一致的生产级特征计算平台开源解决方案
2.1 OpenMLDB 架构以及说明
这张图展示的是 OpenMLDB 的架构。
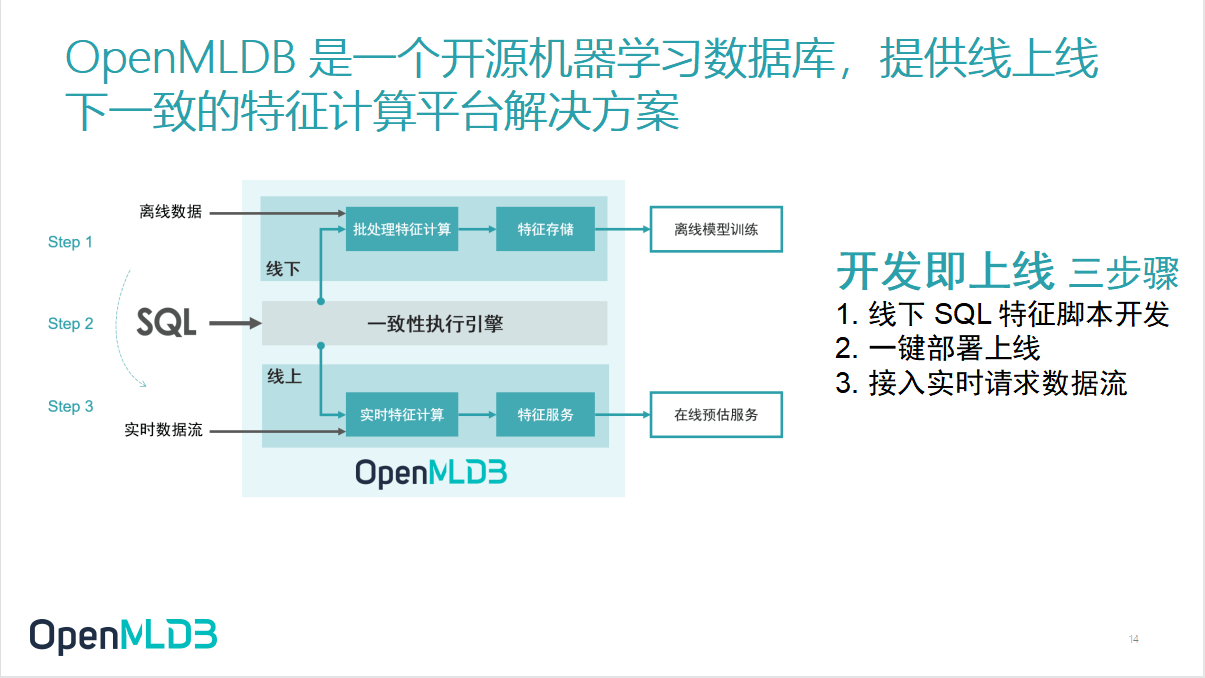 从外围来看,我们提供了统一的 SQL 接口。
对开发人员来讲,开发不再需要两套接口。数据科学家在离线开发过程当中写的 SQL,就是最后上线的 SQL,这两者是天然统一的。对外部的开发者来说,语言转化为同一种,数据科学家写的 SQL 不需要工程化团队翻译,就能直接上线。
为了保证这个功能,OpenMLDB 内部设有统一的计算执行引擎,做统一的底层计算逻辑,以及逻辑计划到物理计划的翻译。拿来同一个 SQL,就能翻译成合适的、保证两者一致性的执行计划给到线上计算引擎。
关注上下结构,可以看到线下和线上的两套计算引擎。
因为前面提到过,线上和线下两者的性能要求其实是完全不一样的,所以计算引擎还是分开的状态。
线下做离线开发的时候,我们看重的是数据规模以及批处理的效率,所以线下模块本质上还是我们在 Spark 的基础上做了一些改进。
线上看重的是线上服务的低延迟、高吞吐、高并发,线上服务可能只能接受十几到几十毫秒这种量级的延迟。为了达到这个目的,线上的整个计算引擎是我们团队从头开发的一套 in memory 的基于纯内存的内存索引结构,是一个非常高效的基于内存运算的时序数据库。
这中间还有一个非常重要的构成——一致性执行引擎。
一致性执行引擎最重要的工作就是保障线上线下执行逻辑的一致性。表面上来看,就是拿一个统一的 SQL,既能转换到 Spark 去做,对离线批处理也能转换到自研的时序数据库,进行线上的高性能SQL查询。
线上线下会共享一些统一的计算函数,更重要的是,会存在一个逻辑计划到物理计划的线上线下执行模式的自适应。因为线上和线下执行的时候,数据形态是非常不一样的,做离线开发的时候,不管是 label 的样本表还是物料表,都是批处理的模式,在线上时一条一条传输过来,我们更看重的是一条一条的内存,所以会做一些细节上的转换,更好地达到性能要求。
那么通过的中间的执行引擎,一方面是达到线上线下的一致性,另一方面也能达到线上和线下的不同的执行效率的要求。也就是说在OpenMLDB内部已经做到了线上线下的一致性,不再需要额外的人力。
总结来说,OpenMLDB 做到了开发及上线的三步骤:
从外围来看,我们提供了统一的 SQL 接口。
对开发人员来讲,开发不再需要两套接口。数据科学家在离线开发过程当中写的 SQL,就是最后上线的 SQL,这两者是天然统一的。对外部的开发者来说,语言转化为同一种,数据科学家写的 SQL 不需要工程化团队翻译,就能直接上线。
为了保证这个功能,OpenMLDB 内部设有统一的计算执行引擎,做统一的底层计算逻辑,以及逻辑计划到物理计划的翻译。拿来同一个 SQL,就能翻译成合适的、保证两者一致性的执行计划给到线上计算引擎。
关注上下结构,可以看到线下和线上的两套计算引擎。
因为前面提到过,线上和线下两者的性能要求其实是完全不一样的,所以计算引擎还是分开的状态。
线下做离线开发的时候,我们看重的是数据规模以及批处理的效率,所以线下模块本质上还是我们在 Spark 的基础上做了一些改进。
线上看重的是线上服务的低延迟、高吞吐、高并发,线上服务可能只能接受十几到几十毫秒这种量级的延迟。为了达到这个目的,线上的整个计算引擎是我们团队从头开发的一套 in memory 的基于纯内存的内存索引结构,是一个非常高效的基于内存运算的时序数据库。
这中间还有一个非常重要的构成——一致性执行引擎。
一致性执行引擎最重要的工作就是保障线上线下执行逻辑的一致性。表面上来看,就是拿一个统一的 SQL,既能转换到 Spark 去做,对离线批处理也能转换到自研的时序数据库,进行线上的高性能SQL查询。
线上线下会共享一些统一的计算函数,更重要的是,会存在一个逻辑计划到物理计划的线上线下执行模式的自适应。因为线上和线下执行的时候,数据形态是非常不一样的,做离线开发的时候,不管是 label 的样本表还是物料表,都是批处理的模式,在线上时一条一条传输过来,我们更看重的是一条一条的内存,所以会做一些细节上的转换,更好地达到性能要求。
那么通过的中间的执行引擎,一方面是达到线上线下的一致性,另一方面也能达到线上和线下的不同的执行效率的要求。也就是说在OpenMLDB内部已经做到了线上线下的一致性,不再需要额外的人力。
总结来说,OpenMLDB 做到了开发及上线的三步骤:
- 线下SQL特征脚本开发
- 一键部署上线
- 接入实时请求数据流
(这里解释一下实时数据流的概念,例如我们需要三月以来的购物数据作为数据流,随着系统外现实世界的时间推移,数据流的内容也会过期,需要更新,那么需要实时的数据流接近,不断把最新的三个月数据保留在内部。这也是我们和 Pulsar 合作打造新的基于数据流的接口的原因,在这方面 OpenMLDB 下一步还会持续优化。)
2.2 OpenMLDB 应用场景和方式
 在应用场景和方式的介绍中,我们使用这样一张图表,越往右离线计算性能需求越高,越往上实时计算需求越高,通过两条虚线,把它划为四个象限。我们暂且不讲左下角的需求,重点介绍其他三个象限。
右上象限就是我们刚才提到的场景,需要从离线开发到实时线上计算的完整流程,可以用我们 OpenMLDB 完整的离线到实时上线流程去做这个开发和业务上线。这个过程中会用到我们的离线引擎和在线引擎,也能享受到线上线下一致性的功能,是我们认为的最典型的一种使用方式。
左上象限的场景也是我们在实际中接触过的应用场景,当很多小伙伴开始试用 OpenMLDB 的时候,其实已经有很多现存的业务逻辑了,这个时候可以只想利用OpenMLDB高性能的线上计算引擎。OpenMLDB 的离线和在线引擎是一个解耦的状态,所以能够满足单独使用在线引擎去做实时特征计算。当然这个地方的线上线下一致性无法得到 非常严格的保证了。如果你后期需要应用到新的场景,或者一致性需要得到非常强的验证,可能还是要通过 OpenMLDB 走完整的离线到实时上线流程。
还有一种需求,如右下象限所示。如果不需要做实时特征计算,或者不需要去做上线,可能只需要做一个探索,或是做模型推理研究,没有上线需求,那也可以用到 OpenMLDB 的离线引擎,就是通过我们改进的 Spark 版本做开发,改进版本会对离线特征抽取的性能起到非常大的改善作用。
这三种使用方式不仅在企业用户还是在社区用户中都有存在。
在应用场景和方式的介绍中,我们使用这样一张图表,越往右离线计算性能需求越高,越往上实时计算需求越高,通过两条虚线,把它划为四个象限。我们暂且不讲左下角的需求,重点介绍其他三个象限。
右上象限就是我们刚才提到的场景,需要从离线开发到实时线上计算的完整流程,可以用我们 OpenMLDB 完整的离线到实时上线流程去做这个开发和业务上线。这个过程中会用到我们的离线引擎和在线引擎,也能享受到线上线下一致性的功能,是我们认为的最典型的一种使用方式。
左上象限的场景也是我们在实际中接触过的应用场景,当很多小伙伴开始试用 OpenMLDB 的时候,其实已经有很多现存的业务逻辑了,这个时候可以只想利用OpenMLDB高性能的线上计算引擎。OpenMLDB 的离线和在线引擎是一个解耦的状态,所以能够满足单独使用在线引擎去做实时特征计算。当然这个地方的线上线下一致性无法得到 非常严格的保证了。如果你后期需要应用到新的场景,或者一致性需要得到非常强的验证,可能还是要通过 OpenMLDB 走完整的离线到实时上线流程。
还有一种需求,如右下象限所示。如果不需要做实时特征计算,或者不需要去做上线,可能只需要做一个探索,或是做模型推理研究,没有上线需求,那也可以用到 OpenMLDB 的离线引擎,就是通过我们改进的 Spark 版本做开发,改进版本会对离线特征抽取的性能起到非常大的改善作用。
这三种使用方式不仅在企业用户还是在社区用户中都有存在。
2.3 从离线开发到线上服务完整流程
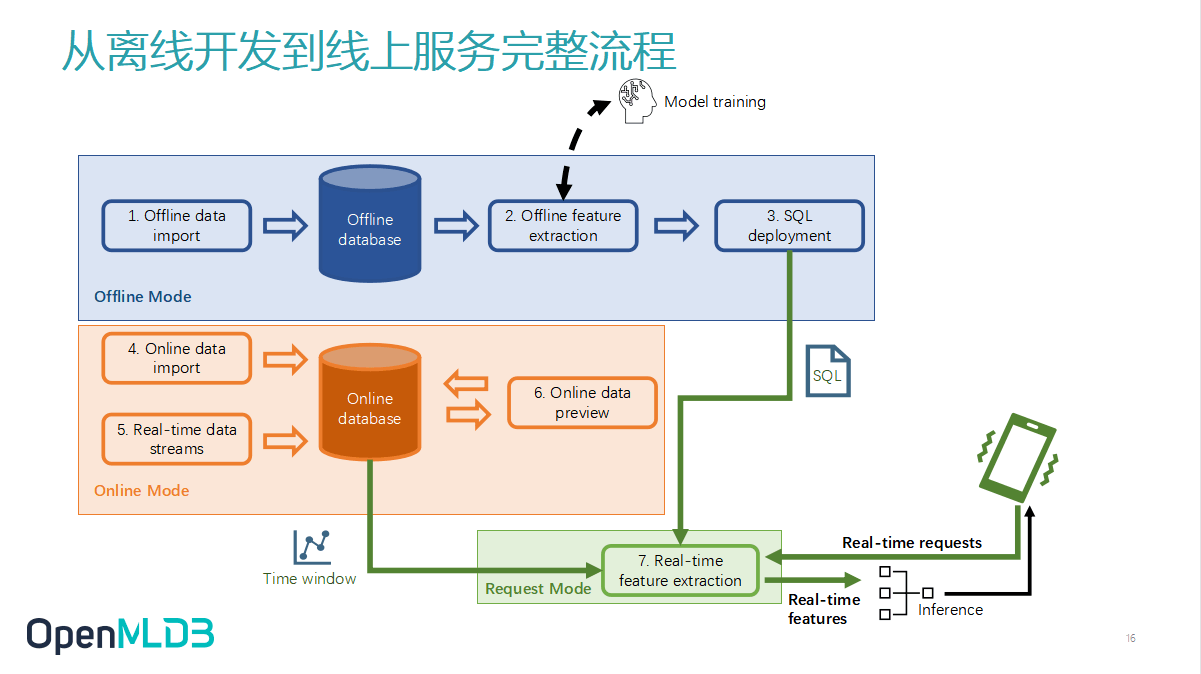 接着,我会从我们最推荐的离线开发到线上服务的完整流程来讲解。
首先,我们会做离线的模式,把离线的数据导到 OpenMLDB,可以是软链的导入方式。此处的 Offline database 是一个虚拟概念化的存在,此时我们就可以做一个离线模型特征脚本的开发,在这个过程中和 Model training 可能也会有一个交互,要反复去调整。待到性能达到预期后,我们可以做一个动作,即 SQL deployment。把 SQL 部署上线,那么 OpenMLDB 的部署模式就会从 Offline 转至 Online。
在 Online 的首要工作是冷启动,导入需要的数据。我们特征脚本一般是面向时序数据的,所以会在窗口上做计算。假设我只需要最近三个月的数据,那我在上线的时间点需要在冷启动的时候把最近三个月的数据导入。而实际上,最近三个月的数据是不够的,因为现实世界的时间是不断推移的,所以需要不断更新这个 Online database。因此,OpenMLDB 需要接入在线的实时数据流。当然这里也提供 SDK,也支持通过 SDK 去实时地插入数据。
做完这一步已经万事具备,此时你可以使用 Preview 功能去看一下线上数据导入是否正确,但这是可选的。
做到这一步呢,整个 OpenMLD B就会转入一个叫做 Request mode,已经处在一个可以做实时计算的这个模式当中了。在我刚才讲述的例子中,小李搜索洗衣机关键字的信息进来后,系统就能结合计算逻辑和数据源坐等返回的特定结果了。这样一个 OpenMLDB 使用流程在我们的产品文档里有更进一步的描述。
接着,我会从我们最推荐的离线开发到线上服务的完整流程来讲解。
首先,我们会做离线的模式,把离线的数据导到 OpenMLDB,可以是软链的导入方式。此处的 Offline database 是一个虚拟概念化的存在,此时我们就可以做一个离线模型特征脚本的开发,在这个过程中和 Model training 可能也会有一个交互,要反复去调整。待到性能达到预期后,我们可以做一个动作,即 SQL deployment。把 SQL 部署上线,那么 OpenMLDB 的部署模式就会从 Offline 转至 Online。
在 Online 的首要工作是冷启动,导入需要的数据。我们特征脚本一般是面向时序数据的,所以会在窗口上做计算。假设我只需要最近三个月的数据,那我在上线的时间点需要在冷启动的时候把最近三个月的数据导入。而实际上,最近三个月的数据是不够的,因为现实世界的时间是不断推移的,所以需要不断更新这个 Online database。因此,OpenMLDB 需要接入在线的实时数据流。当然这里也提供 SDK,也支持通过 SDK 去实时地插入数据。
做完这一步已经万事具备,此时你可以使用 Preview 功能去看一下线上数据导入是否正确,但这是可选的。
做到这一步呢,整个 OpenMLD B就会转入一个叫做 Request mode,已经处在一个可以做实时计算的这个模式当中了。在我刚才讲述的例子中,小李搜索洗衣机关键字的信息进来后,系统就能结合计算逻辑和数据源坐等返回的特定结果了。这样一个 OpenMLDB 使用流程在我们的产品文档里有更进一步的描述。
2.4 OpenMLDB 产品特性
在介绍完 OpenMLDB 整体的架构和使用流程后,我会展开讲解 OpenMLDB 的产品特性。
2.4.1 OpenMLDB 产品特性一:线上线下一致性执行
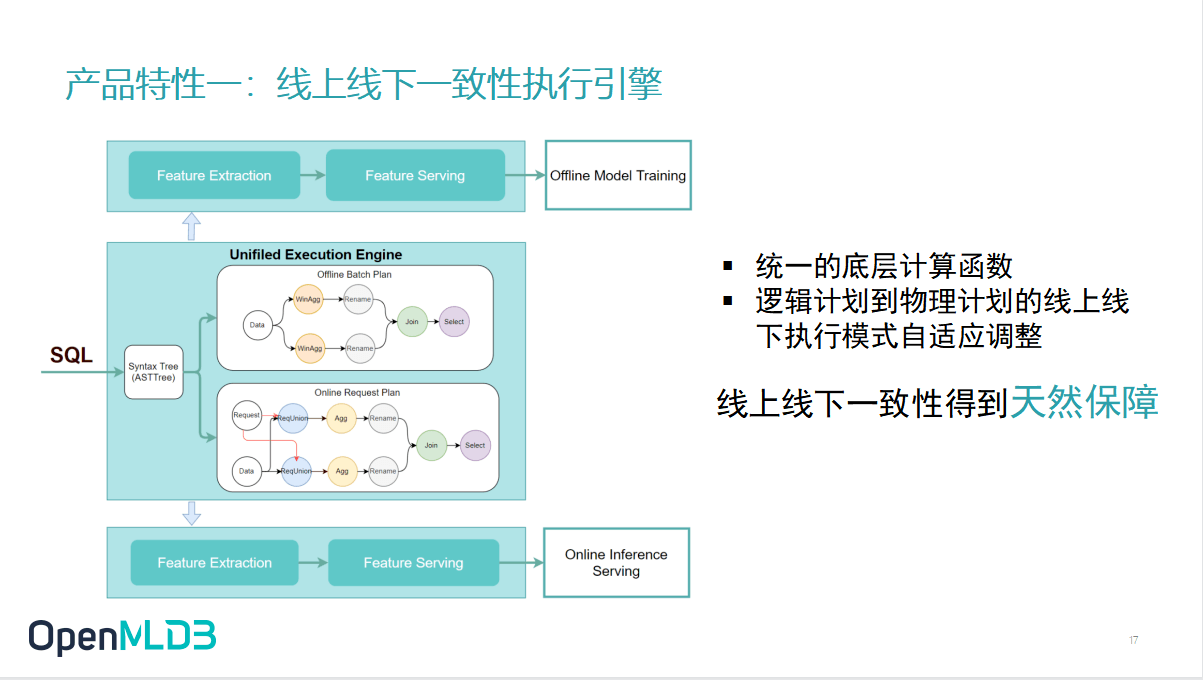 之前讲过的一致性执行引擎,其实就是在内部去把 SQL 做了一个转换,转换成线上的执行计划和线下的执行计划,保证这两个值是从定义和执行逻辑上都是一致的。等于说线上线下一致性是在 OpenMLDB 的内部得到了一个天然的保障。
之前讲过的一致性执行引擎,其实就是在内部去把 SQL 做了一个转换,转换成线上的执行计划和线下的执行计划,保证这两个值是从定义和执行逻辑上都是一致的。等于说线上线下一致性是在 OpenMLDB 的内部得到了一个天然的保障。
2.4.2 OpenMLDB 产品特性二:高性能在线特征计算引擎
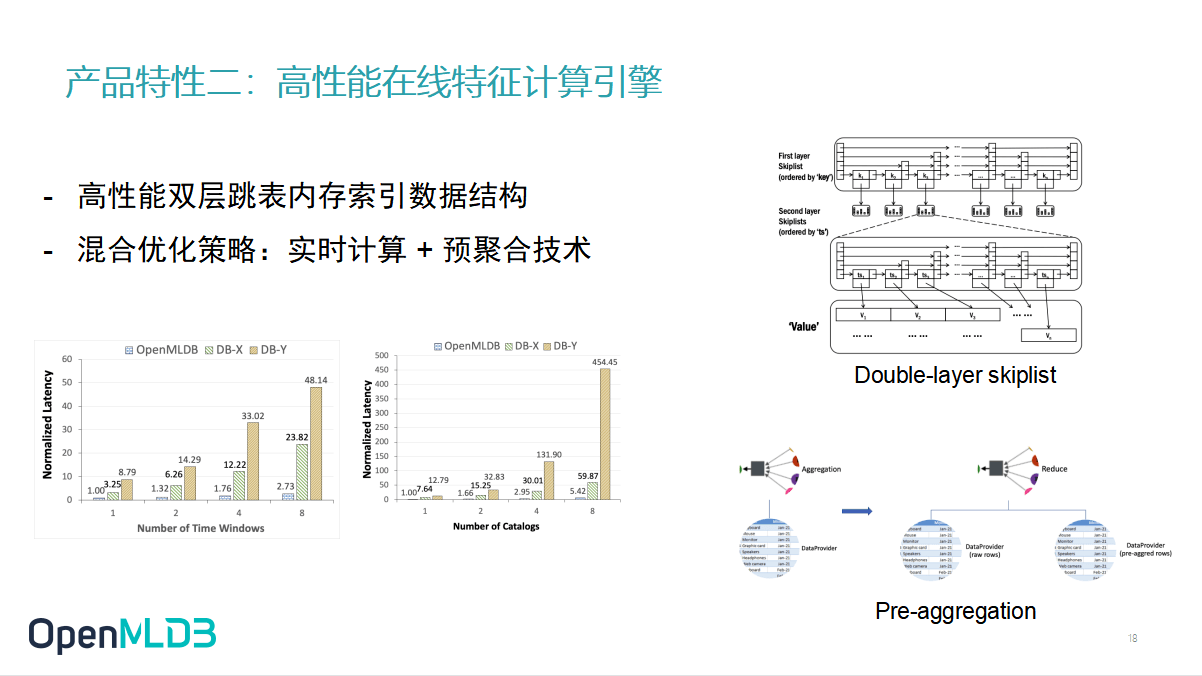 第二个非常重要的特性,就是我们之前讲到的在线特征计算引擎。那我们怎么去保证在的计算的高性能呢?
第一,在线计算引擎加存储引擎都是我们自研的一个时序特征数据库,在内部它是一个双层的跳表结构,这有利于我们去高效地拿到窗口化的数据。
第二,我们做了一些预聚合的处理,部分特征可以提前去聚合计算,不需要等到查询时才准备。比方说需要过去一年内的商品点击量之前,我们可以把每个月的点击量先做好预聚合,当这个线上请求到来的时候,只需把每个月的点击量加起来再补充上最新的特征,就可以达到目的。 在这两种策略的加持下,我们和其他同样是 in memory 的数据库去做比较,可以看到在专门对这个特征工程做的窗口化查询需求下,OpenMLDB的性能会有非常大的优势。
第二个非常重要的特性,就是我们之前讲到的在线特征计算引擎。那我们怎么去保证在的计算的高性能呢?
第一,在线计算引擎加存储引擎都是我们自研的一个时序特征数据库,在内部它是一个双层的跳表结构,这有利于我们去高效地拿到窗口化的数据。
第二,我们做了一些预聚合的处理,部分特征可以提前去聚合计算,不需要等到查询时才准备。比方说需要过去一年内的商品点击量之前,我们可以把每个月的点击量先做好预聚合,当这个线上请求到来的时候,只需把每个月的点击量加起来再补充上最新的特征,就可以达到目的。 在这两种策略的加持下,我们和其他同样是 in memory 的数据库去做比较,可以看到在专门对这个特征工程做的窗口化查询需求下,OpenMLDB的性能会有非常大的优势。
2.4.3 OpenMLDB 产品特性三:面向特征计算的优化的离线计算引擎
 第三个特性就是离线计算引擎的优化。
离线计算引擎是基于 Spark 的优化的版本,我们不是把原始的 Spark 直接拿来的,而是针对特征计优化做了一些措施,比如右边这个图,叫做多窗口的一些并行计算优化:SQL 定义了两个窗口,是在不同的 key 上面,一个是 group by name,一个是 group by age,这是两个时间窗口,在 Spark3.0 上翻译出来,这两个窗口会串行地去执行,有时候没法完全的非常好地利用集群的资源,所以我们在这里就改动了 Spark 的源代码,使其可以并行执行起来的,从而提升效率。这是其中的一个改动,其他的还有比如数据倾斜的优化,都是基于在 Spark 发行版里面去做的一些优化。左下角这个图显示了我们目前的版本和 Spark 原始版本的性能比对,可以看到,达到了一个非常显著的性能提升,特别是针对特征工程相关的操作。
第三个特性就是离线计算引擎的优化。
离线计算引擎是基于 Spark 的优化的版本,我们不是把原始的 Spark 直接拿来的,而是针对特征计优化做了一些措施,比如右边这个图,叫做多窗口的一些并行计算优化:SQL 定义了两个窗口,是在不同的 key 上面,一个是 group by name,一个是 group by age,这是两个时间窗口,在 Spark3.0 上翻译出来,这两个窗口会串行地去执行,有时候没法完全的非常好地利用集群的资源,所以我们在这里就改动了 Spark 的源代码,使其可以并行执行起来的,从而提升效率。这是其中的一个改动,其他的还有比如数据倾斜的优化,都是基于在 Spark 发行版里面去做的一些优化。左下角这个图显示了我们目前的版本和 Spark 原始版本的性能比对,可以看到,达到了一个非常显著的性能提升,特别是针对特征工程相关的操作。
2.4.4 OpenMLDB 产品特性四:针对特征工程的 SQL 扩展
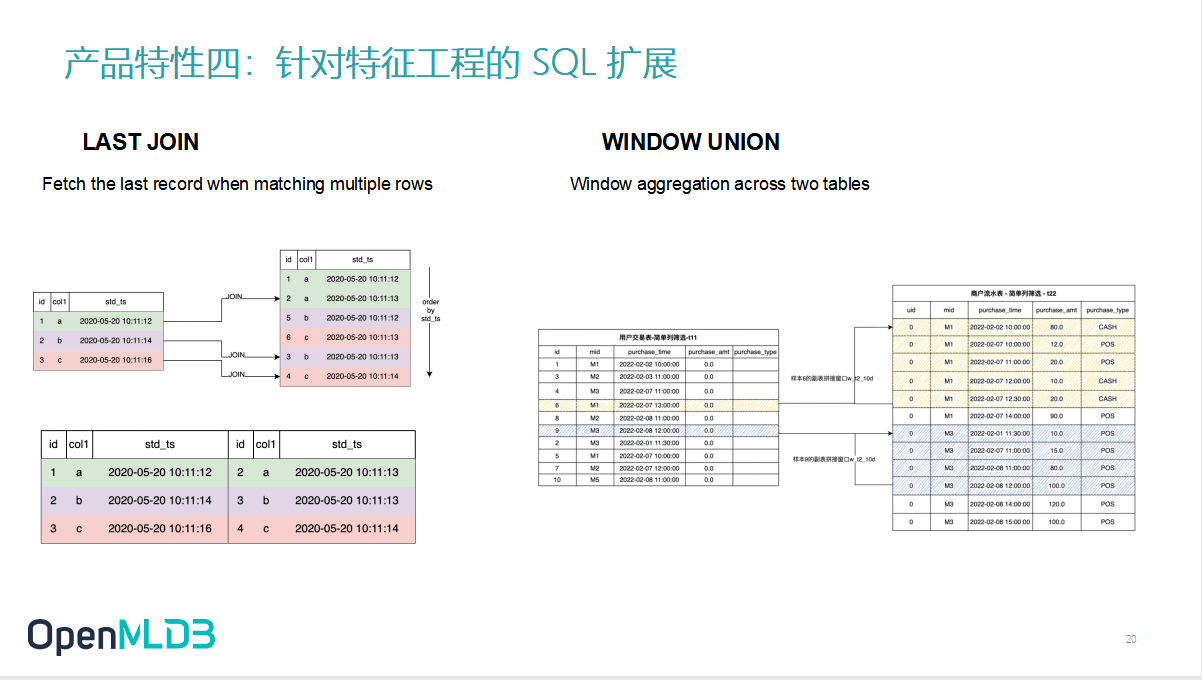 特征四涉及到一个很常听到的疑问。因为我们是基于 SQL 去做这个特征工程,那大家很自然的会有一个问题——SQL 的表达能力是否足够?我们的回答是,原生的标准的 SQL 对某些比较复杂的特征处理逻辑上其实不是那么友好。但是,在 OpenMLDB 中,我们做了SQL语法和功能的扩展。
最典型例子是图片左边展示的 LAST JOIN,它能够在左表匹配到右表多行的时候只取最近的一条或者设定的某一条。这种场景在机器学习的这个训练里面有很多应用。
还有一个例子时 WINDOW UNION 的语法,从直观来理解,其实是做了一个跨表的窗口聚合操作。比方说这个左表(也是主表),左表的这个时间戳可以在右表的匹配的数据集上画一个时间窗口,在右表做一个聚合,然后把聚合结果拼到左表上。跨表聚合是 WINDOW UNION 所要达到最主要目的,当然它还有一些更复杂的用法,大家可以去参考我们的语法文档。
基于语法扩展和功能扩展,OpenMLDB 中 SQL 目前的表达能力是足够的。当然我们也看到社区用户其实可能有一些更高的要求,特别是针对一些这个计算函数,我们也在不断的扩展可能的新语法,包括新的 build in 函数,这块内容也非常欢迎大家来和我们一起做。
特征四涉及到一个很常听到的疑问。因为我们是基于 SQL 去做这个特征工程,那大家很自然的会有一个问题——SQL 的表达能力是否足够?我们的回答是,原生的标准的 SQL 对某些比较复杂的特征处理逻辑上其实不是那么友好。但是,在 OpenMLDB 中,我们做了SQL语法和功能的扩展。
最典型例子是图片左边展示的 LAST JOIN,它能够在左表匹配到右表多行的时候只取最近的一条或者设定的某一条。这种场景在机器学习的这个训练里面有很多应用。
还有一个例子时 WINDOW UNION 的语法,从直观来理解,其实是做了一个跨表的窗口聚合操作。比方说这个左表(也是主表),左表的这个时间戳可以在右表的匹配的数据集上画一个时间窗口,在右表做一个聚合,然后把聚合结果拼到左表上。跨表聚合是 WINDOW UNION 所要达到最主要目的,当然它还有一些更复杂的用法,大家可以去参考我们的语法文档。
基于语法扩展和功能扩展,OpenMLDB 中 SQL 目前的表达能力是足够的。当然我们也看到社区用户其实可能有一些更高的要求,特别是针对一些这个计算函数,我们也在不断的扩展可能的新语法,包括新的 build in 函数,这块内容也非常欢迎大家来和我们一起做。
2.4.5 OpenMLDB 产品特性五:企业级特性支持
 第五个非常重要的特性涉及到 OpenMLDB 的历史,它是从第四范式的商业产品转化而来,在开源之前已经应用于很多大规模的企业级应用里了,且在上百个场景里面都经过了实践。所以我们非常看重如何真正落到企业大规模企业级应用里的一些 feature,比方说高可用、扩缩融、平滑升级和企业级监控在如今的 OpenMLDB 中都是支持的。
最主要的一些企业级的 feature 已经在开源版本里列出来了,还有比如多租户、云原生,已经在我们的 roadmap 中,这一部分功能我们会不断地完善它,去更好的去为企业级应用做服务。
第五个非常重要的特性涉及到 OpenMLDB 的历史,它是从第四范式的商业产品转化而来,在开源之前已经应用于很多大规模的企业级应用里了,且在上百个场景里面都经过了实践。所以我们非常看重如何真正落到企业大规模企业级应用里的一些 feature,比方说高可用、扩缩融、平滑升级和企业级监控在如今的 OpenMLDB 中都是支持的。
最主要的一些企业级的 feature 已经在开源版本里列出来了,还有比如多租户、云原生,已经在我们的 roadmap 中,这一部分功能我们会不断地完善它,去更好的去为企业级应用做服务。
2.4.6 OpenMLDB 产品特性六:以SQL为核心的开发和管理体验
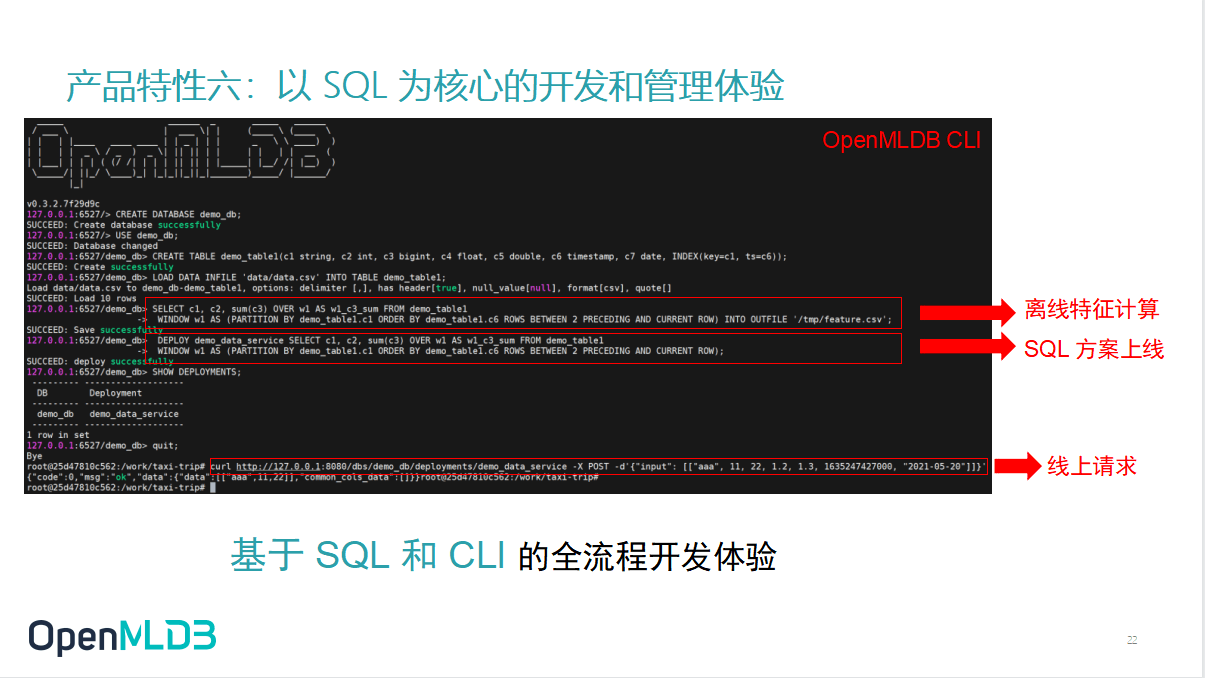 最后给大家分享一下这个 OpenMLDB 的一个非常重要的使用方式。我们认为它是一个数据库,最中心的一点就是 OpenMLDB 是以 SQL 为核心的全流程开发和管理体验,在 CLI 里面去做离线特征方案的开发,开发完离线特征计算,可以一步切换到这个SQL的方案上线,直接用一个 DEPLOY 命令把离线的方案切换到线上,就可以直接进入 serving 的服务。然后按步骤操作,就可以直接做线上请求,进行实时特征计算了。
通过一个 API 做线上请求,或者通过 Python,Java 的 SDK,都可以直接去跟 serving 的服务器做通信和线上请求。可以看到,基于 SQL 和基于 CLI 的开发非常低门槛以及方便。
最后给大家分享一下这个 OpenMLDB 的一个非常重要的使用方式。我们认为它是一个数据库,最中心的一点就是 OpenMLDB 是以 SQL 为核心的全流程开发和管理体验,在 CLI 里面去做离线特征方案的开发,开发完离线特征计算,可以一步切换到这个SQL的方案上线,直接用一个 DEPLOY 命令把离线的方案切换到线上,就可以直接进入 serving 的服务。然后按步骤操作,就可以直接做线上请求,进行实时特征计算了。
通过一个 API 做线上请求,或者通过 Python,Java 的 SDK,都可以直接去跟 serving 的服务器做通信和线上请求。可以看到,基于 SQL 和基于 CLI 的开发非常低门槛以及方便。
2.5 OpenMLDB 上下游生态
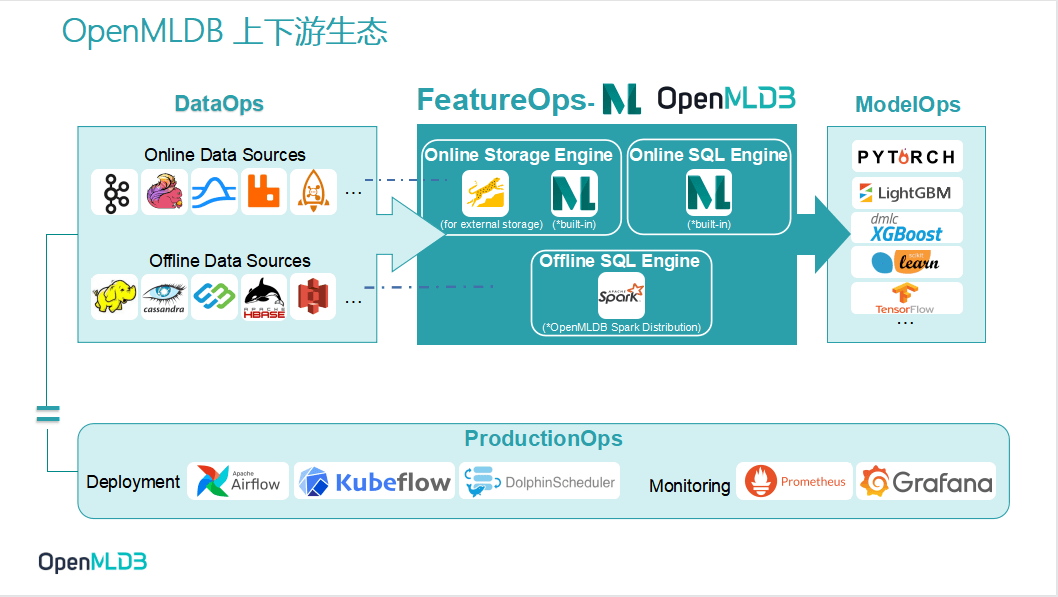 将 OpenMLDB 投射到 MLOps 生命周期中,可以看到 OpenMLDB 占据着其中 FeatureOps 的位置,主要是做特征计算。
将 OpenMLDB 投射到 MLOps 生命周期中,可以看到 OpenMLDB 占据着其中 FeatureOps 的位置,主要是做特征计算。
2.5.1 内部框架
先解析 OpenMLDB 内部框架,我们有这个 Online 引擎和 Offline 引擎。
Online 引擎又可以被细分为存储和执行。在其中的 SQL 执行层面,因为需要储存最新的实时数据的,所以我们会有一个 Storage engine,在默认情况下会有 in memory storage(build in)。它其实是非常高效的、专门面向时序数据库去优化的一个内存数据库。当然我们也可以数据存在磁盘上,把 RocksDB 插进来。所以 OpenMLDB v 0.5.0的版本会同时提供两种不同的 Storage Engine。如果你对性能需求特别高,可以选择 in memory storage engine。如果你对性能不太敏感但是重视成本,那么可以使用基于磁盘的存储(RocksDB)。
Online SQL Engine 这一块是我们自研的,用于高性能进行 SQL 计算。Offline 板块是基于Spark去做了合理的修改,称作这个 OpenMLDB 的 Spark 发行版,未来我们可能也会有其他的一些扩展。
2.5.2 Data sources
左边的是 DataOps,介绍了数据是如何获取的。比方说 Online data sources 板块,我们发布了 OpenMLDB Pulsar connector, 已经可以接入 Pulsar 的数据了。这个月发布的版本中,我们应该还会把 Kafka 的这个 connector 也同时发布出来,更加有利于这个大家数据的接入。在 Offline data sources 这一块呢,OpenMLDB 支持直接接入 HDFS、S3 数据 ,未来我们也会支持更多的数据源。
2.5.3 ModelOps
往右的 ModelOps 这边,其实是一些下游模型。下游模型通过一些标准输出格式,就能直接接入了。这个月会发布的新版本中,我们会把这个模型特征的功能整合进来,让它可以输出这个标准的 LIBSVM 或者 CSV 的格式,可以直接给到 Pytorch 等使用。
2.5.4 ProductionOps
我们也在做部署合和任务编排,OpenMLDB 已经和 Airflow 和 Kubeflow 做了对接,有望在近期完成与 Airflow 的合作内容。监控一块也是非常易于使用的,OpenMLDB 已经和 Prometheus 和 Grafana 做了对接。
2.6 拥抱前沿新硬件技术:基于持久内存的优化
 在前沿技术创新上我们也有产出成果,这个是去年被录用的一个 VLDB 的 paper,VLDB 是国际数据库界最顶尖的学术界的会议,在 paper 里面我们讲了两个事情:
在前沿技术创新上我们也有产出成果,这个是去年被录用的一个 VLDB 的 paper,VLDB 是国际数据库界最顶尖的学术界的会议,在 paper 里面我们讲了两个事情:
- 一是把我们整个 OpenMLDB 的实现架构都去仔细进行了描述,所以大家想了解这个架构的话可以也去参照一下 paper;
- 二是讲了怎么去跟今天的前沿的硬件技术做结合,前沿的硬件技术就是 persistent memory,即持久内存,以前在学术界叫做非易失性内存。
持久内存是英特尔在大概 18、 19 年左右,发布了真正工业界第一款企业级的持久内存应用,奥腾持久内存。那么持久内存有什么优势呢?首先它成本低,它的单位价格是 Dram的 1/3~1/4 左右。当然它的性能也会比 Dram 稍微差 1/2 或 1/3 左右,但是比 SSD 还是会好一个量级的。其次容量大,一条持久内存可以最高到 512 GB,一台服务器上就很容易达到几个 TB。还有一个非常革命性的技术,就是可持久性的内存。现在的 Dram 掉电以后数据都没了,而 Persistent memory 掉电以后这个数据还在,这个是一个非常革命性的技术。
我们把持久内存跟 OpenMLDB 线上执行引擎已经结合了起来。前面提到了线上执行引擎的特点,首先它是一个基本上是基于纯内存的执行引擎,所以把它运行起来的成本有时候还是挺高的,如果场景特别大,为了满足内存需求,需要十几台机器,才能运行起来。同时它也有恢复时间慢的问题,因为它一旦掉电,需要从外部存储重新构建内存镜像,需要较长的时间。
于是我们就把持久内存跟 OpenMLDB 的线上引擎给结合起来,达到了三个非常好的效果:
- 恢复时间从本来的 6 个小时级别降到了 1 分钟。线上业务的意义其实是非常巨大的,线上业务比方说点餐系统,是不允许长时间掉线的,或者不允许某节点掉线以后影响业务的服务质量。结合之后,一分钟就能把这个业务重新拉起来,就不会影响到服务质量。
- 由于一些底层架构的修改,也改进了 20% 的长尾延迟。在 TP9999 的情况下,这就非常显著。
- 减少了总成本。因为内存单台机器内存扩大,使用的机器数量就变少了,原来用 16 台,现在只需要 6 台,成本一下子就降下来了。
2.7 OpenMLDB 典型案例 – 某银行事中反欺诈交易
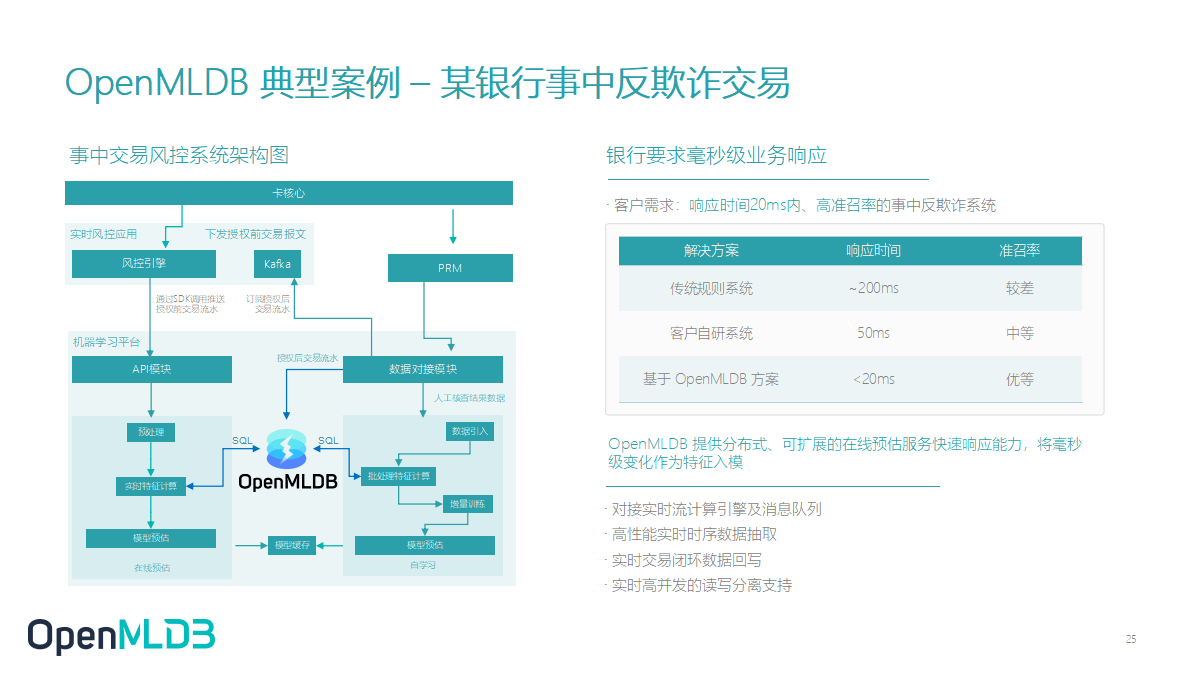 接下来举一个简单的例子,在某银行的事中反欺诈交易场景,OpenMLDB 其实就是处于 FeatureOps 的位置,同时衔接了离线批处理和实时特征计算。然后在某银行的业务场景里,他们对响应的要求是非常高的,需要延迟在 20 ms 以内。可以看到,相比较于它原来传统规则的系统、客户自研的系统,OpenMLDB 提供了一个更好的效果,满足了他们发展的业务需求。
接下来举一个简单的例子,在某银行的事中反欺诈交易场景,OpenMLDB 其实就是处于 FeatureOps 的位置,同时衔接了离线批处理和实时特征计算。然后在某银行的业务场景里,他们对响应的要求是非常高的,需要延迟在 20 ms 以内。可以看到,相比较于它原来传统规则的系统、客户自研的系统,OpenMLDB 提供了一个更好的效果,满足了他们发展的业务需求。
2.8 OpenMLDB 的历史
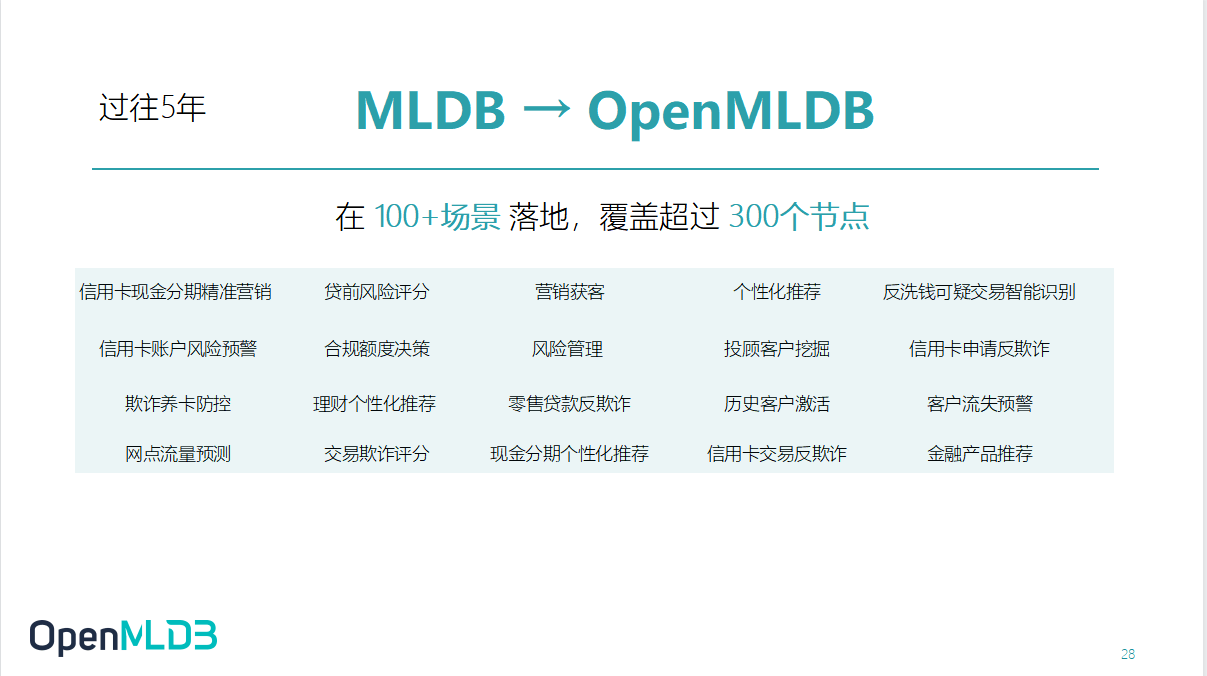
其实 OpenMLDB 是从第四范式成立第一天就开始做的产品。经过了 5 年的研发沉淀,OpenMLDB 跟随着商业产品经历了上百个项目的验证,累积了非常多的案例。
3 | 面向开源开放的 OpenMLDB 社区发展
3.1 OpenMLDB 发展历程
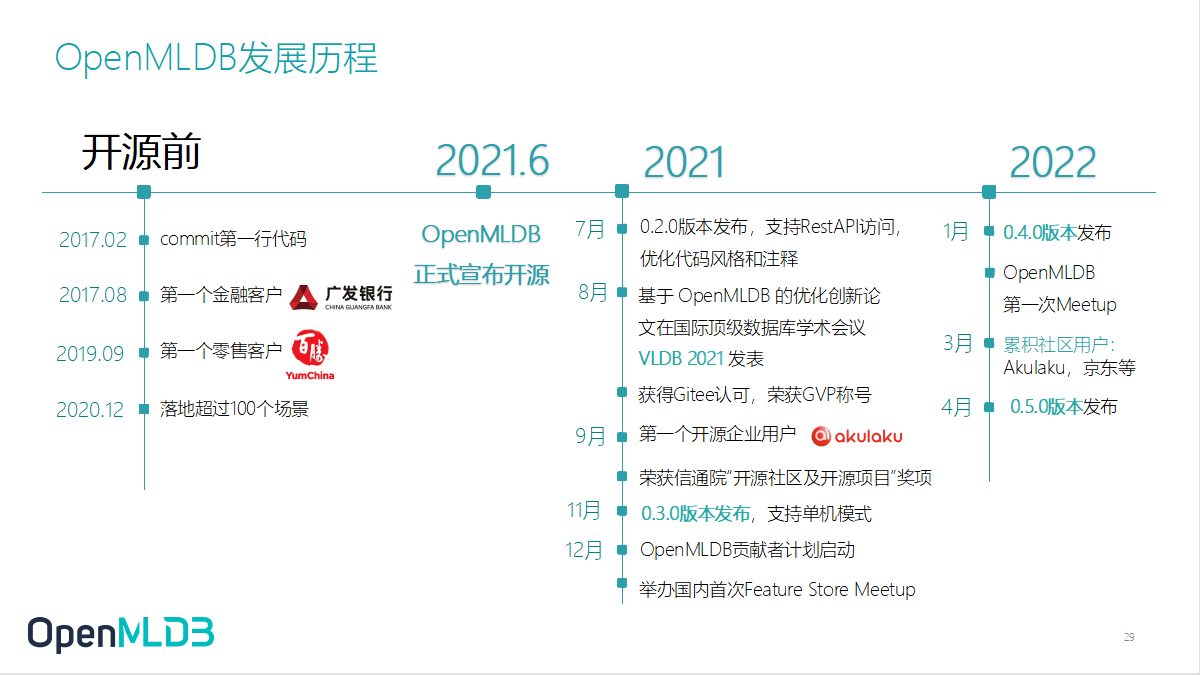 OpenMLDB 真正开源是去年的 6 月,我们其中的关键组件重新从商业平台中抽取出来,做了包装和优化形成了 OpenMLDB 今天的形态,并且对外开源,贡献给社区。我们开源后收获了不错的反馈,去年 9 月收获了第一个开源企业用户 Akulaku,今年我们也看到很多新团队在不断深入使用 OpenMLDB。
OpenMLDB 真正开源是去年的 6 月,我们其中的关键组件重新从商业平台中抽取出来,做了包装和优化形成了 OpenMLDB 今天的形态,并且对外开源,贡献给社区。我们开源后收获了不错的反馈,去年 9 月收获了第一个开源企业用户 Akulaku,今年我们也看到很多新团队在不断深入使用 OpenMLDB。
3.2 OpenMLDB 开源基本信息
 这张图上是 OpenMLDB 的一些基本信息,大家可以简单了解。
这张图上是 OpenMLDB 的一些基本信息,大家可以简单了解。
3.3 感谢OpenMLDB的社区开发者
 趁这个机会,我想再次感谢一下 OpenMLDB 的社区开发者。到目前为止,共有 51 位开发者加入社区。是大家不断地投入时间精力,OpenMLDB 才能被推动着不断往前发展。从 0.4.0 版本以来,又有 15 位新加入的开发者为社区做出了贡献。在这里,我想表示诚挚的感谢。如果大家对 OpenMLDB 感兴趣,也非常欢迎你作为新伙伴加入。
趁这个机会,我想再次感谢一下 OpenMLDB 的社区开发者。到目前为止,共有 51 位开发者加入社区。是大家不断地投入时间精力,OpenMLDB 才能被推动着不断往前发展。从 0.4.0 版本以来,又有 15 位新加入的开发者为社区做出了贡献。在这里,我想表示诚挚的感谢。如果大家对 OpenMLDB 感兴趣,也非常欢迎你作为新伙伴加入。
3.4 OpenMLDB v0.5.0 主要特性
最后想重点给大家介绍 OpenMLDB v0.5.0的新特性,预计在 4 月底发布。

- 预聚合技术应用到长窗口上。这个长窗口指的是时间窗口非常大,包含上百万条数据,针对这块数据做优化处理,我们会把预聚合技术应用进去,指数级提升长窗口聚合性能。
- 提供一个新的针对磁盘的存储引擎。如果你对价格敏感的话,可以选者这种 RocksDB 的外存储存。这样使得线上存储引擎可插拔以适配不同业务需求,既可以支持基于内存的高性能存储引擎,也可以支持基于外存的大容量低成本存储引擎,还可以支持基于持久内存的存储引擎以在性能和成本间保持平衡。
- UDF(用户自定义函数)支持,也会在加入到产品中,大幅提升易用性和适用性。
- 支持基于哈希的离散特征编码,以及编码后特征输出到CSV合LIBSVM格式,直接应用到模型训练合模型推理。
- 完善的监控能力,在企业级应用环境中大幅提升稳定性、可观测性、和可分析性。
- 上下游数据源生态整合,提供多种数据源 connectors,包括线上数据源的 Kafka, Pulsar connectors 等等。
3.5 OpenMLDB 后续重要特性
后续规划中 OpenMLDB 特性会朝着三个主要目标去走,三个主要目标就是降低使用门槛,降低使用成本,以及跟上下游生态的打通。
 后续迭代都会不断地朝着这三个目标走。比方去规划一个 Cloud native 的 OpenMLDB 版本,包括自动特征工程,可能是今天用户还需要写 SQL,而在未来 SQL 可以根据数据去自动生成。以及还有基于异构硬件的优化,非结构化数据的支持,特征版本合血缘关系管理。大家对某个 feature 特别感兴趣或者特别需要的话,可以通过社区、Github 等渠道进行反馈,我们会去根据社区的反馈去看需求的优先级,也非常欢迎来自社区的共同开发。
后续迭代都会不断地朝着这三个目标走。比方去规划一个 Cloud native 的 OpenMLDB 版本,包括自动特征工程,可能是今天用户还需要写 SQL,而在未来 SQL 可以根据数据去自动生成。以及还有基于异构硬件的优化,非结构化数据的支持,特征版本合血缘关系管理。大家对某个 feature 特别感兴趣或者特别需要的话,可以通过社区、Github 等渠道进行反馈,我们会去根据社区的反馈去看需求的优先级,也非常欢迎来自社区的共同开发。
3.6 欢迎加入 OpenMLDB 开源社区
 上次 Meetup 时,我预告了官网的上线。如今 OpenMLDB 官网已经顺利推出,欢迎大家访问。或者也可以访问我们的 Github 页面,加入我们的微信交流群,又或是我的个人微信探讨交流。
今天的分享就到这里了,感谢大家。
上次 Meetup 时,我预告了官网的上线。如今 OpenMLDB 官网已经顺利推出,欢迎大家访问。或者也可以访问我们的 Github 页面,加入我们的微信交流群,又或是我的个人微信探讨交流。
今天的分享就到这里了,感谢大家。
- 面向结构化数据和决策类场景
- 处理时序数据
- 基于时间窗口的聚合函数
展开说明上述三点。
其中的结构化数据,简单来说指的是表数据。而决策类场景指的是区别于基于深度学习的感知类产品所面向的决策类场景,更多应用于实时推荐系统、风控系统、反欺诈系统等企业业务系统的场景。
所谓的时序数据,就是所有的数据记录都会带有一个时间戳,如图中数据表格里的第四列就包含着时间戳。
在实际生产当中特征工程基本上都是对这种时序数据去做这个时间窗口上的聚合函数,这也是我们处理最多的特征工程。
生产级特征工程业务需求
下面我们会从业务角度举例,说明生产级特征工程所面向是两大业务需求:
- 线上模型精度符合业务需求
- 特征实时计算,满足低延迟
以实时推荐系统为例,比如小李同学,在某个时间点想买洗衣机,去搜索洗衣机,触发了搜索行为以后,后面整个特征计算会做什么?首先进来的实时行为特征,这三个原始的特征就是 User ID,日期以及他在搜索的产品。如果我们只是拿这三个特征去做模型训练和推理,是达不到一个业务需求的模型精度的。
此时我们需要做的是一个特征工程,所谓的特征工程就是我们从数据库里去进一步地拉取一些历史数据,比方说我们从交易数据库、商品数据库、用户数据库去拉取一些历史数据,然后组合、计算,得到一些更完整的更有意义的特征。
图片左下角就是一个实时的特征。假设当前有个主播正在带货,或者网络购物平台正好有一批优惠券正在发放,此时就会存在一个非常实时的特征,比如当前优惠券最多的或者折扣力度最大的洗衣机型号是什么,也可能是过去5分钟内点击量最多的洗衣机是什么,这些特征的计算对实时性的要求非常高。当然抽取的特征中也有一部分特征可能和小李过去的消费行为相结合。比方说小李过去一年买的最多的电子品牌是什么,他的消费平均水平是什么。我们将所有的特征组合起来,衍生出来的新特征,就是通过特征工程(或者叫做特征计算)生产的特征,最后组合成一个完整的特征列表,再将它给到后续的模型预估。
从这个案例我们可以看出,做特征工程包含了非常重要的特征计算步骤。
特征平台开发上线生命周期
在这两个业务需求之下,特征计算平台从开发到上线的全生命周期是如何完成的呢?
一开始入场的是数据科学家,他们会根据历史数据和业务精度的要求建立一个离线的业务模型,在此过程中设计离线特征脚本。这个特征脚本就是前面提到的过去一段时间内的点击量的特征等等。要如何去抽取这些特征,要定义哪些特征,判断不同的场景中需要开发何种特征脚本是数据科学家的工作,而在这个过程中大部分数据科学家喜欢使用的语言是 Python,一部分科学家也有可能用到 SparkSQL。
对于数据科学家而言,主要任务就是开发出高质量模型,并通过数据验证测试使得最后生成的模型质量是符合预期的。而上线后的工程化需求,例如低延迟、高吞吐、可运维性等等既不在他们的工作职责之内,也不是数据科学家擅长解决的问题。当工作进展到业务上线的部分时,会有工程化团队来负责,并进一步介入 AI 落地。
工程化团队需要去把数据科学家完成的脚本做重构,他们会用一些高性能数据库,甚至用 C++ 重新搭建一套特征抽取的服务,使得上线的产品能够满足业务的实时计算低延迟性能需求。
线上线下计算逻辑一致性校验
那么是否经过数据科学家和工程化团队的接力开发处理,产品就能完美上线了呢?在实际的工程化落地中,答案是是否定的。因为中间还缺了很重要的一步——线上线下计算逻辑一致性校验。
计算逻辑一致性校验,简单来说就是数据科学家和工程化团队生产的模型的精度需要达成一致。最本质问题在特征计算方面,要保证特征抽取的计算逻辑一致。这个地方大家可能听起来很简单,但实际上做起来是不容易的,对齐联调所需要的人力成本、测试成本和修护成本非常庞大。在我们以往的客户服务实践中,一次性校验往往花费数月甚至接近一年的时间去反复校验。而投入大量成本去反复验证,自然是因为线上线下经常出现不一致性。
线上线下不一致可能的原因
- 工具能力的不一致性。离线开发和线上应用,使用的工具栈和开发栈可能是完全不一样的。
离线开发数据科学家更偏好于像 Python、Spark这种这种工具;做线上应用的时候,讲究高性能、低延迟,就需要用一些高性能的编程语言或者数据库来做。
当我们有两套工具的时候,它们覆盖的功能范围是不一样的,比方说做离线开发的时候,使用的是Python,可以实现很复杂的功能,而线上MySQL的功能就会受限于于SQL。
工具能力的不一致性,就会造成做一些妥协的局面,产生的效果就不同。
- 需求沟通的认知差。这不是一个技术问题,但是在实际工程落地当中非常重要。
这里我们举一个例子,Varo,一家非常有名做线上银行的公司,在美国有很多的用户,他们的工程师提到了需求沟通认知差的问题。关于如何定义account balance,他们就有一个教训。工程化团队认为这个 account balance 即是上线以后实时的账户余额;但是数据科学家团队为了简化,而采用了昨天结束时候的账户余额。很明显两者之间的认知差,就能造成后面的整个训练效果的不一致性,从而导致了他们的应用里出现了非常严重的线上业务问题。其实不光是这家银行,在第四范式整个项目实践的周期经验当中,我们都或多或少都碰到过这种沟通认知差带来的问题。一旦出现这种问题,排查的成本其实还是非常高的。
当然原因是多样的,这里我们只列举了两种最重要的原因。
线上线下一致性校验带来的高昂工程化落地成本
因为线上线下的一致性问题的产生,校验是必然的。一次性校验带来了很多成本上的问题:
- 需要两组不同技能栈的开发人员投入,才能去完成从线下到线上的部署的过程。
- 线上线下两套系统的开发和运营。
这两点在工程化落地成本、开发成本、人力成本上面,都有非常大的代价。
为了解决这个问题,国内外的头部企业会花费上千个小时自研构建平台保证线上线下一致性,这个平台和企业内部产品是深度耦合的。除了这些有着超强研发能力的头部企业以外,剩下的大部分企业因为投入研发的成本可能比采购的成本更高,更多地会采购一些Saas工具和服务来解决这个问题。
而今天,OpenMLDB 就提供了另外一种可能,我们提供开源的解决方案,提供 FeatureOps 的企业级解决方案,帮助企业去做到低成本高效率地解决痛难点。
2 | OpenMLDB 为企业提供线上线计算一致的生产级特征计算平台开源解决方案
2.1 OpenMLDB 架构以及说明
这张图展示的是 OpenMLDB 的架构。
从外围来看,我们提供了统一的 SQL 接口。
对开发人员来讲,开发不再需要两套接口。数据科学家在离线开发过程当中写的 SQL,就是最后上线的 SQL,这两者是天然统一的。对外部的开发者来说,语言转化为同一种,数据科学家写的 SQL 不需要工程化团队翻译,就能直接上线。
为了保证这个功能,OpenMLDB 内部设有统一的计算执行引擎,做统一的底层计算逻辑,以及逻辑计划到物理计划的翻译。拿来同一个 SQL,就能翻译成合适的、保证两者一致性的执行计划给到线上计算引擎。
关注上下结构,可以看到线下和线上的两套计算引擎。
因为前面提到过,线上和线下两者的性能要求其实是完全不一样的,所以计算引擎还是分开的状态。
线下做离线开发的时候,我们看重的是数据规模以及批处理的效率,所以线下模块本质上还是我们在 Spark 的基础上做了一些改进。
线上看重的是线上服务的低延迟、高吞吐、高并发,线上服务可能只能接受十几到几十毫秒这种量级的延迟。为了达到这个目的,线上的整个计算引擎是我们团队从头开发的一套 in memory 的基于纯内存的内存索引结构,是一个非常高效的基于内存运算的时序数据库。
这中间还有一个非常重要的构成——一致性执行引擎。
一致性执行引擎最重要的工作就是保障线上线下执行逻辑的一致性。表面上来看,就是拿一个统一的 SQL,既能转换到 Spark 去做,对离线批处理也能转换到自研的时序数据库,进行线上的高性能SQL查询。
线上线下会共享一些统一的计算函数,更重要的是,会存在一个逻辑计划到物理计划的线上线下执行模式的自适应。因为线上和线下执行的时候,数据形态是非常不一样的,做离线开发的时候,不管是 label 的样本表还是物料表,都是批处理的模式,在线上时一条一条传输过来,我们更看重的是一条一条的内存,所以会做一些细节上的转换,更好地达到性能要求。
那么通过的中间的执行引擎,一方面是达到线上线下的一致性,另一方面也能达到线上和线下的不同的执行效率的要求。也就是说在OpenMLDB内部已经做到了线上线下的一致性,不再需要额外的人力。
总结来说,OpenMLDB 做到了开发及上线的三步骤:
- 线下SQL特征脚本开发
- 一键部署上线
- 接入实时请求数据流
(这里解释一下实时数据流的概念,例如我们需要三月以来的购物数据作为数据流,随着系统外现实世界的时间推移,数据流的内容也会过期,需要更新,那么需要实时的数据流接近,不断把最新的三个月数据保留在内部。这也是我们和 Pulsar 合作打造新的基于数据流的接口的原因,在这方面 OpenMLDB 下一步还会持续优化。)
2.2 OpenMLDB 应用场景和方式
在应用场景和方式的介绍中,我们使用这样一张图表,越往右离线计算性能需求越高,越往上实时计算需求越高,通过两条虚线,把它划为四个象限。我们暂且不讲左下角的需求,重点介绍其他三个象限。
右上象限就是我们刚才提到的场景,需要从离线开发到实时线上计算的完整流程,可以用我们 OpenMLDB 完整的离线到实时上线流程去做这个开发和业务上线。这个过程中会用到我们的离线引擎和在线引擎,也能享受到线上线下一致性的功能,是我们认为的最典型的一种使用方式。
左上象限的场景也是我们在实际中接触过的应用场景,当很多小伙伴开始试用 OpenMLDB 的时候,其实已经有很多现存的业务逻辑了,这个时候可以只想利用OpenMLDB高性能的线上计算引擎。OpenMLDB 的离线和在线引擎是一个解耦的状态,所以能够满足单独使用在线引擎去做实时特征计算。当然这个地方的线上线下一致性无法得到 非常严格的保证了。如果你后期需要应用到新的场景,或者一致性需要得到非常强的验证,可能还是要通过 OpenMLDB 走完整的离线到实时上线流程。
还有一种需求,如右下象限所示。如果不需要做实时特征计算,或者不需要去做上线,可能只需要做一个探索,或是做模型推理研究,没有上线需求,那也可以用到 OpenMLDB 的离线引擎,就是通过我们改进的 Spark 版本做开发,改进版本会对离线特征抽取的性能起到非常大的改善作用。
这三种使用方式不仅在企业用户还是在社区用户中都有存在。
2.3 从离线开发到线上服务完整流程
接着,我会从我们最推荐的离线开发到线上服务的完整流程来讲解。
首先,我们会做离线的模式,把离线的数据导到 OpenMLDB,可以是软链的导入方式。此处的 Offline database 是一个虚拟概念化的存在,此时我们就可以做一个离线模型特征脚本的开发,在这个过程中和 Model training 可能也会有一个交互,要反复去调整。待到性能达到预期后,我们可以做一个动作,即 SQL deployment。把 SQL 部署上线,那么 OpenMLDB 的部署模式就会从 Offline 转至 Online。
在 Online 的首要工作是冷启动,导入需要的数据。我们特征脚本一般是面向时序数据的,所以会在窗口上做计算。假设我只需要最近三个月的数据,那我在上线的时间点需要在冷启动的时候把最近三个月的数据导入。而实际上,最近三个月的数据是不够的,因为现实世界的时间是不断推移的,所以需要不断更新这个 Online database。因此,OpenMLDB 需要接入在线的实时数据流。当然这里也提供 SDK,也支持通过 SDK 去实时地插入数据。
做完这一步已经万事具备,此时你可以使用 Preview 功能去看一下线上数据导入是否正确,但这是可选的。
做到这一步呢,整个 OpenMLD B就会转入一个叫做 Request mode,已经处在一个可以做实时计算的这个模式当中了。在我刚才讲述的例子中,小李搜索洗衣机关键字的信息进来后,系统就能结合计算逻辑和数据源坐等返回的特定结果了。这样一个 OpenMLDB 使用流程在我们的产品文档里有更进一步的描述。
2.4 OpenMLDB 产品特性
在介绍完 OpenMLDB 整体的架构和使用流程后,我会展开讲解 OpenMLDB 的产品特性。
2.4.1 OpenMLDB 产品特性一:线上线下一致性执行
之前讲过的一致性执行引擎,其实就是在内部去把 SQL 做了一个转换,转换成线上的执行计划和线下的执行计划,保证这两个值是从定义和执行逻辑上都是一致的。等于说线上线下一致性是在 OpenMLDB 的内部得到了一个天然的保障。
2.4.2 OpenMLDB 产品特性二:高性能在线特征计算引擎
第二个非常重要的特性,就是我们之前讲到的在线特征计算引擎。那我们怎么去保证在的计算的高性能呢?
第一,在线计算引擎加存储引擎都是我们自研的一个时序特征数据库,在内部它是一个双层的跳表结构,这有利于我们去高效地拿到窗口化的数据。
第二,我们做了一些预聚合的处理,部分特征可以提前去聚合计算,不需要等到查询时才准备。比方说需要过去一年内的商品点击量之前,我们可以把每个月的点击量先做好预聚合,当这个线上请求到来的时候,只需把每个月的点击量加起来再补充上最新的特征,就可以达到目的。 在这两种策略的加持下,我们和其他同样是 in memory 的数据库去做比较,可以看到在专门对这个特征工程做的窗口化查询需求下,OpenMLDB的性能会有非常大的优势。
2.4.3 OpenMLDB 产品特性三:面向特征计算的优化的离线计算引擎
第三个特性就是离线计算引擎的优化。
离线计算引擎是基于 Spark 的优化的版本,我们不是把原始的 Spark 直接拿来的,而是针对特征计优化做了一些措施,比如右边这个图,叫做多窗口的一些并行计算优化:SQL 定义了两个窗口,是在不同的 key 上面,一个是 group by name,一个是 group by age,这是两个时间窗口,在 Spark3.0 上翻译出来,这两个窗口会串行地去执行,有时候没法完全的非常好地利用集群的资源,所以我们在这里就改动了 Spark 的源代码,使其可以并行执行起来的,从而提升效率。这是其中的一个改动,其他的还有比如数据倾斜的优化,都是基于在 Spark 发行版里面去做的一些优化。左下角这个图显示了我们目前的版本和 Spark 原始版本的性能比对,可以看到,达到了一个非常显著的性能提升,特别是针对特征工程相关的操作。
2.4.4 OpenMLDB 产品特性四:针对特征工程的 SQL 扩展
特征四涉及到一个很常听到的疑问。因为我们是基于 SQL 去做这个特征工程,那大家很自然的会有一个问题——SQL 的表达能力是否足够?我们的回答是,原生的标准的 SQL 对某些比较复杂的特征处理逻辑上其实不是那么友好。但是,在 OpenMLDB 中,我们做了SQL语法和功能的扩展。
最典型例子是图片左边展示的 LAST JOIN,它能够在左表匹配到右表多行的时候只取最近的一条或者设定的某一条。这种场景在机器学习的这个训练里面有很多应用。
还有一个例子时 WINDOW UNION 的语法,从直观来理解,其实是做了一个跨表的窗口聚合操作。比方说这个左表(也是主表),左表的这个时间戳可以在右表的匹配的数据集上画一个时间窗口,在右表做一个聚合,然后把聚合结果拼到左表上。跨表聚合是 WINDOW UNION 所要达到最主要目的,当然它还有一些更复杂的用法,大家可以去参考我们的语法文档。
基于语法扩展和功能扩展,OpenMLDB 中 SQL 目前的表达能力是足够的。当然我们也看到社区用户其实可能有一些更高的要求,特别是针对一些这个计算函数,我们也在不断的扩展可能的新语法,包括新的 build in 函数,这块内容也非常欢迎大家来和我们一起做。
2.4.5 OpenMLDB 产品特性五:企业级特性支持
第五个非常重要的特性涉及到 OpenMLDB 的历史,它是从第四范式的商业产品转化而来,在开源之前已经应用于很多大规模的企业级应用里了,且在上百个场景里面都经过了实践。所以我们非常看重如何真正落到企业大规模企业级应用里的一些 feature,比方说高可用、扩缩融、平滑升级和企业级监控在如今的 OpenMLDB 中都是支持的。
最主要的一些企业级的 feature 已经在开源版本里列出来了,还有比如多租户、云原生,已经在我们的 roadmap 中,这一部分功能我们会不断地完善它,去更好的去为企业级应用做服务。
2.4.6 OpenMLDB 产品特性六:以SQL为核心的开发和管理体验
最后给大家分享一下这个 OpenMLDB 的一个非常重要的使用方式。我们认为它是一个数据库,最中心的一点就是 OpenMLDB 是以 SQL 为核心的全流程开发和管理体验,在 CLI 里面去做离线特征方案的开发,开发完离线特征计算,可以一步切换到这个SQL的方案上线,直接用一个 DEPLOY 命令把离线的方案切换到线上,就可以直接进入 serving 的服务。然后按步骤操作,就可以直接做线上请求,进行实时特征计算了。
通过一个 API 做线上请求,或者通过 Python,Java 的 SDK,都可以直接去跟 serving 的服务器做通信和线上请求。可以看到,基于 SQL 和基于 CLI 的开发非常低门槛以及方便。
2.5 OpenMLDB 上下游生态
将 OpenMLDB 投射到 MLOps 生命周期中,可以看到 OpenMLDB 占据着其中 FeatureOps 的位置,主要是做特征计算。
2.5.1 内部框架
先解析 OpenMLDB 内部框架,我们有这个 Online 引擎和 Offline 引擎。
Online 引擎又可以被细分为存储和执行。在其中的 SQL 执行层面,因为需要储存最新的实时数据的,所以我们会有一个 Storage engine,在默认情况下会有 in memory storage(build in)。它其实是非常高效的、专门面向时序数据库去优化的一个内存数据库。当然我们也可以数据存在磁盘上,把 RocksDB 插进来。所以 OpenMLDB v 0.5.0的版本会同时提供两种不同的 Storage Engine。如果你对性能需求特别高,可以选择 in memory storage engine。如果你对性能不太敏感但是重视成本,那么可以使用基于磁盘的存储(RocksDB)。
Online SQL Engine 这一块是我们自研的,用于高性能进行 SQL 计算。Offline 板块是基于Spark去做了合理的修改,称作这个 OpenMLDB 的 Spark 发行版,未来我们可能也会有其他的一些扩展。
2.5.2 Data sources
左边的是 DataOps,介绍了数据是如何获取的。比方说 Online data sources 板块,我们发布了 OpenMLDB Pulsar connector, 已经可以接入 Pulsar 的数据了。这个月发布的版本中,我们应该还会把 Kafka 的这个 connector 也同时发布出来,更加有利于这个大家数据的接入。在 Offline data sources 这一块呢,OpenMLDB 支持直接接入 HDFS、S3 数据 ,未来我们也会支持更多的数据源。
2.5.3 ModelOps
往右的 ModelOps 这边,其实是一些下游模型。下游模型通过一些标准输出格式,就能直接接入了。这个月会发布的新版本中,我们会把这个模型特征的功能整合进来,让它可以输出这个标准的 LIBSVM 或者 CSV 的格式,可以直接给到 Pytorch 等使用。
2.5.4 ProductionOps
我们也在做部署合和任务编排,OpenMLDB 已经和 Airflow 和 Kubeflow 做了对接,有望在近期完成与 Airflow 的合作内容。监控一块也是非常易于使用的,OpenMLDB 已经和 Prometheus 和 Grafana 做了对接。
2.6 拥抱前沿新硬件技术:基于持久内存的优化
在前沿技术创新上我们也有产出成果,这个是去年被录用的一个 VLDB 的 paper,VLDB 是国际数据库界最顶尖的学术界的会议,在 paper 里面我们讲了两个事情:
- 一是把我们整个 OpenMLDB 的实现架构都去仔细进行了描述,所以大家想了解这个架构的话可以也去参照一下 paper;
- 二是讲了怎么去跟今天的前沿的硬件技术做结合,前沿的硬件技术就是 persistent memory,即持久内存,以前在学术界叫做非易失性内存。
持久内存是英特尔在大概 18、 19 年左右,发布了真正工业界第一款企业级的持久内存应用,奥腾持久内存。那么持久内存有什么优势呢?首先它成本低,它的单位价格是 Dram的 1/3~1/4 左右。当然它的性能也会比 Dram 稍微差 1/2 或 1/3 左右,但是比 SSD 还是会好一个量级的。其次容量大,一条持久内存可以最高到 512 GB,一台服务器上就很容易达到几个 TB。还有一个非常革命性的技术,就是可持久性的内存。现在的 Dram 掉电以后数据都没了,而 Persistent memory 掉电以后这个数据还在,这个是一个非常革命性的技术。
我们把持久内存跟 OpenMLDB 线上执行引擎已经结合了起来。前面提到了线上执行引擎的特点,首先它是一个基本上是基于纯内存的执行引擎,所以把它运行起来的成本有时候还是挺高的,如果场景特别大,为了满足内存需求,需要十几台机器,才能运行起来。同时它也有恢复时间慢的问题,因为它一旦掉电,需要从外部存储重新构建内存镜像,需要较长的时间。
于是我们就把持久内存跟 OpenMLDB 的线上引擎给结合起来,达到了三个非常好的效果:
- 恢复时间从本来的 6 个小时级别降到了 1 分钟。线上业务的意义其实是非常巨大的,线上业务比方说点餐系统,是不允许长时间掉线的,或者不允许某节点掉线以后影响业务的服务质量。结合之后,一分钟就能把这个业务重新拉起来,就不会影响到服务质量。
- 由于一些底层架构的修改,也改进了 20% 的长尾延迟。在 TP9999 的情况下,这就非常显著。
- 减少了总成本。因为内存单台机器内存扩大,使用的机器数量就变少了,原来用 16 台,现在只需要 6 台,成本一下子就降下来了。
2.7 OpenMLDB 典型案例 – 某银行事中反欺诈交易
接下来举一个简单的例子,在某银行的事中反欺诈交易场景,OpenMLDB 其实就是处于 FeatureOps 的位置,同时衔接了离线批处理和实时特征计算。然后在某银行的业务场景里,他们对响应的要求是非常高的,需要延迟在 20 ms 以内。可以看到,相比较于它原来传统规则的系统、客户自研的系统,OpenMLDB 提供了一个更好的效果,满足了他们发展的业务需求。
2.8 OpenMLDB 的历史
其实 OpenMLDB 是从第四范式成立第一天就开始做的产品。经过了 5 年的研发沉淀,OpenMLDB 跟随着商业产品经历了上百个项目的验证,累积了非常多的案例。
3 | 面向开源开放的 OpenMLDB 社区发展
3.1 OpenMLDB 发展历程
OpenMLDB 真正开源是去年的 6 月,我们其中的关键组件重新从商业平台中抽取出来,做了包装和优化形成了 OpenMLDB 今天的形态,并且对外开源,贡献给社区。我们开源后收获了不错的反馈,去年 9 月收获了第一个开源企业用户 Akulaku,今年我们也看到很多新团队在不断深入使用 OpenMLDB。
3.2 OpenMLDB 开源基本信息
这张图上是 OpenMLDB 的一些基本信息,大家可以简单了解。
3.3 感谢OpenMLDB的社区开发者
趁这个机会,我想再次感谢一下 OpenMLDB 的社区开发者。到目前为止,共有 51 位开发者加入社区。是大家不断地投入时间精力,OpenMLDB 才能被推动着不断往前发展。从 0.4.0 版本以来,又有 15 位新加入的开发者为社区做出了贡献。在这里,我想表示诚挚的感谢。如果大家对 OpenMLDB 感兴趣,也非常欢迎你作为新伙伴加入。
3.4 OpenMLDB v0.5.0 主要特性
最后想重点给大家介绍 OpenMLDB v0.5.0的新特性,预计在 4 月底发布。
- 预聚合技术应用到长窗口上。这个长窗口指的是时间窗口非常大,包含上百万条数据,针对这块数据做优化处理,我们会把预聚合技术应用进去,指数级提升长窗口聚合性能。
- 提供一个新的针对磁盘的存储引擎。如果你对价格敏感的话,可以选者这种 RocksDB 的外存储存。这样使得线上存储引擎可插拔以适配不同业务需求,既可以支持基于内存的高性能存储引擎,也可以支持基于外存的大容量低成本存储引擎,还可以支持基于持久内存的存储引擎以在性能和成本间保持平衡。
- UDF(用户自定义函数)支持,也会在加入到产品中,大幅提升易用性和适用性。
- 支持基于哈希的离散特征编码,以及编码后特征输出到CSV合LIBSVM格式,直接应用到模型训练合模型推理。
- 完善的监控能力,在企业级应用环境中大幅提升稳定性、可观测性、和可分析性。
- 上下游数据源生态整合,提供多种数据源 connectors,包括线上数据源的 Kafka, Pulsar connectors 等等。
3.5 OpenMLDB 后续重要特性
后续规划中 OpenMLDB 特性会朝着三个主要目标去走,三个主要目标就是降低使用门槛,降低使用成本,以及跟上下游生态的打通。
后续迭代都会不断地朝着这三个目标走。比方去规划一个 Cloud native 的 OpenMLDB 版本,包括自动特征工程,可能是今天用户还需要写 SQL,而在未来 SQL 可以根据数据去自动生成。以及还有基于异构硬件的优化,非结构化数据的支持,特征版本合血缘关系管理。大家对某个 feature 特别感兴趣或者特别需要的话,可以通过社区、Github 等渠道进行反馈,我们会去根据社区的反馈去看需求的优先级,也非常欢迎来自社区的共同开发。
3.6 欢迎加入 OpenMLDB 开源社区
上次 Meetup 时,我预告了官网的上线。如今 OpenMLDB 官网已经顺利推出,欢迎大家访问。或者也可以访问我们的 Github 页面,加入我们的微信交流群,又或是我的个人微信探讨交流。
今天的分享就到这里了,感谢大家。
在这两个业务需求之下,特征计算平台从开发到上线的全生命周期是如何完成的呢?
一开始入场的是数据科学家,他们会根据历史数据和业务精度的要求建立一个离线的业务模型,在此过程中设计离线特征脚本。这个特征脚本就是前面提到的过去一段时间内的点击量的特征等等。要如何去抽取这些特征,要定义哪些特征,判断不同的场景中需要开发何种特征脚本是数据科学家的工作,而在这个过程中大部分数据科学家喜欢使用的语言是 Python,一部分科学家也有可能用到 SparkSQL。
对于数据科学家而言,主要任务就是开发出高质量模型,并通过数据验证测试使得最后生成的模型质量是符合预期的。而上线后的工程化需求,例如低延迟、高吞吐、可运维性等等既不在他们的工作职责之内,也不是数据科学家擅长解决的问题。当工作进展到业务上线的部分时,会有工程化团队来负责,并进一步介入 AI 落地。
工程化团队需要去把数据科学家完成的脚本做重构,他们会用一些高性能数据库,甚至用 C++ 重新搭建一套特征抽取的服务,使得上线的产品能够满足业务的实时计算低延迟性能需求。
线上线下计算逻辑一致性校验
那么是否经过数据科学家和工程化团队的接力开发处理,产品就能完美上线了呢?在实际的工程化落地中,答案是是否定的。因为中间还缺了很重要的一步——线上线下计算逻辑一致性校验。
计算逻辑一致性校验,简单来说就是数据科学家和工程化团队生产的模型的精度需要达成一致。最本质问题在特征计算方面,要保证特征抽取的计算逻辑一致。这个地方大家可能听起来很简单,但实际上做起来是不容易的,对齐联调所需要的人力成本、测试成本和修护成本非常庞大。在我们以往的客户服务实践中,一次性校验往往花费数月甚至接近一年的时间去反复校验。而投入大量成本去反复验证,自然是因为线上线下经常出现不一致性。
线上线下不一致可能的原因
- 工具能力的不一致性。离线开发和线上应用,使用的工具栈和开发栈可能是完全不一样的。
离线开发数据科学家更偏好于像 Python、Spark这种这种工具;做线上应用的时候,讲究高性能、低延迟,就需要用一些高性能的编程语言或者数据库来做。
当我们有两套工具的时候,它们覆盖的功能范围是不一样的,比方说做离线开发的时候,使用的是Python,可以实现很复杂的功能,而线上MySQL的功能就会受限于于SQL。
工具能力的不一致性,就会造成做一些妥协的局面,产生的效果就不同。
- 需求沟通的认知差。这不是一个技术问题,但是在实际工程落地当中非常重要。
这里我们举一个例子,Varo,一家非常有名做线上银行的公司,在美国有很多的用户,他们的工程师提到了需求沟通认知差的问题。关于如何定义account balance,他们就有一个教训。工程化团队认为这个 account balance 即是上线以后实时的账户余额;但是数据科学家团队为了简化,而采用了昨天结束时候的账户余额。很明显两者之间的认知差,就能造成后面的整个训练效果的不一致性,从而导致了他们的应用里出现了非常严重的线上业务问题。其实不光是这家银行,在第四范式整个项目实践的周期经验当中,我们都或多或少都碰到过这种沟通认知差带来的问题。一旦出现这种问题,排查的成本其实还是非常高的。
当然原因是多样的,这里我们只列举了两种最重要的原因。
线上线下一致性校验带来的高昂工程化落地成本
因为线上线下的一致性问题的产生,校验是必然的。一次性校验带来了很多成本上的问题:
- 需要两组不同技能栈的开发人员投入,才能去完成从线下到线上的部署的过程。
- 线上线下两套系统的开发和运营。
这两点在工程化落地成本、开发成本、人力成本上面,都有非常大的代价。
为了解决这个问题,国内外的头部企业会花费上千个小时自研构建平台保证线上线下一致性,这个平台和企业内部产品是深度耦合的。除了这些有着超强研发能力的头部企业以外,剩下的大部分企业因为投入研发的成本可能比采购的成本更高,更多地会采购一些Saas工具和服务来解决这个问题。
而今天,OpenMLDB 就提供了另外一种可能,我们提供开源的解决方案,提供 FeatureOps 的企业级解决方案,帮助企业去做到低成本高效率地解决痛难点。
2 | OpenMLDB 为企业提供线上线计算一致的生产级特征计算平台开源解决方案
2.1 OpenMLDB 架构以及说明
这张图展示的是 OpenMLDB 的架构。
从外围来看,我们提供了统一的 SQL 接口。
对开发人员来讲,开发不再需要两套接口。数据科学家在离线开发过程当中写的 SQL,就是最后上线的 SQL,这两者是天然统一的。对外部的开发者来说,语言转化为同一种,数据科学家写的 SQL 不需要工程化团队翻译,就能直接上线。
为了保证这个功能,OpenMLDB 内部设有统一的计算执行引擎,做统一的底层计算逻辑,以及逻辑计划到物理计划的翻译。拿来同一个 SQL,就能翻译成合适的、保证两者一致性的执行计划给到线上计算引擎。
关注上下结构,可以看到线下和线上的两套计算引擎。
因为前面提到过,线上和线下两者的性能要求其实是完全不一样的,所以计算引擎还是分开的状态。
线下做离线开发的时候,我们看重的是数据规模以及批处理的效率,所以线下模块本质上还是我们在 Spark 的基础上做了一些改进。
线上看重的是线上服务的低延迟、高吞吐、高并发,线上服务可能只能接受十几到几十毫秒这种量级的延迟。为了达到这个目的,线上的整个计算引擎是我们团队从头开发的一套 in memory 的基于纯内存的内存索引结构,是一个非常高效的基于内存运算的时序数据库。
这中间还有一个非常重要的构成——一致性执行引擎。
一致性执行引擎最重要的工作就是保障线上线下执行逻辑的一致性。表面上来看,就是拿一个统一的 SQL,既能转换到 Spark 去做,对离线批处理也能转换到自研的时序数据库,进行线上的高性能SQL查询。
线上线下会共享一些统一的计算函数,更重要的是,会存在一个逻辑计划到物理计划的线上线下执行模式的自适应。因为线上和线下执行的时候,数据形态是非常不一样的,做离线开发的时候,不管是 label 的样本表还是物料表,都是批处理的模式,在线上时一条一条传输过来,我们更看重的是一条一条的内存,所以会做一些细节上的转换,更好地达到性能要求。
那么通过的中间的执行引擎,一方面是达到线上线下的一致性,另一方面也能达到线上和线下的不同的执行效率的要求。也就是说在OpenMLDB内部已经做到了线上线下的一致性,不再需要额外的人力。
总结来说,OpenMLDB 做到了开发及上线的三步骤:
- 线下SQL特征脚本开发
- 一键部署上线
- 接入实时请求数据流
(这里解释一下实时数据流的概念,例如我们需要三月以来的购物数据作为数据流,随着系统外现实世界的时间推移,数据流的内容也会过期,需要更新,那么需要实时的数据流接近,不断把最新的三个月数据保留在内部。这也是我们和 Pulsar 合作打造新的基于数据流的接口的原因,在这方面 OpenMLDB 下一步还会持续优化。)
2.2 OpenMLDB 应用场景和方式
在应用场景和方式的介绍中,我们使用这样一张图表,越往右离线计算性能需求越高,越往上实时计算需求越高,通过两条虚线,把它划为四个象限。我们暂且不讲左下角的需求,重点介绍其他三个象限。
右上象限就是我们刚才提到的场景,需要从离线开发到实时线上计算的完整流程,可以用我们 OpenMLDB 完整的离线到实时上线流程去做这个开发和业务上线。这个过程中会用到我们的离线引擎和在线引擎,也能享受到线上线下一致性的功能,是我们认为的最典型的一种使用方式。
左上象限的场景也是我们在实际中接触过的应用场景,当很多小伙伴开始试用 OpenMLDB 的时候,其实已经有很多现存的业务逻辑了,这个时候可以只想利用OpenMLDB高性能的线上计算引擎。OpenMLDB 的离线和在线引擎是一个解耦的状态,所以能够满足单独使用在线引擎去做实时特征计算。当然这个地方的线上线下一致性无法得到 非常严格的保证了。如果你后期需要应用到新的场景,或者一致性需要得到非常强的验证,可能还是要通过 OpenMLDB 走完整的离线到实时上线流程。
还有一种需求,如右下象限所示。如果不需要做实时特征计算,或者不需要去做上线,可能只需要做一个探索,或是做模型推理研究,没有上线需求,那也可以用到 OpenMLDB 的离线引擎,就是通过我们改进的 Spark 版本做开发,改进版本会对离线特征抽取的性能起到非常大的改善作用。
这三种使用方式不仅在企业用户还是在社区用户中都有存在。
2.3 从离线开发到线上服务完整流程
接着,我会从我们最推荐的离线开发到线上服务的完整流程来讲解。
首先,我们会做离线的模式,把离线的数据导到 OpenMLDB,可以是软链的导入方式。此处的 Offline database 是一个虚拟概念化的存在,此时我们就可以做一个离线模型特征脚本的开发,在这个过程中和 Model training 可能也会有一个交互,要反复去调整。待到性能达到预期后,我们可以做一个动作,即 SQL deployment。把 SQL 部署上线,那么 OpenMLDB 的部署模式就会从 Offline 转至 Online。
在 Online 的首要工作是冷启动,导入需要的数据。我们特征脚本一般是面向时序数据的,所以会在窗口上做计算。假设我只需要最近三个月的数据,那我在上线的时间点需要在冷启动的时候把最近三个月的数据导入。而实际上,最近三个月的数据是不够的,因为现实世界的时间是不断推移的,所以需要不断更新这个 Online database。因此,OpenMLDB 需要接入在线的实时数据流。当然这里也提供 SDK,也支持通过 SDK 去实时地插入数据。
做完这一步已经万事具备,此时你可以使用 Preview 功能去看一下线上数据导入是否正确,但这是可选的。
做到这一步呢,整个 OpenMLD B就会转入一个叫做 Request mode,已经处在一个可以做实时计算的这个模式当中了。在我刚才讲述的例子中,小李搜索洗衣机关键字的信息进来后,系统就能结合计算逻辑和数据源坐等返回的特定结果了。这样一个 OpenMLDB 使用流程在我们的产品文档里有更进一步的描述。
2.4 OpenMLDB 产品特性
在介绍完 OpenMLDB 整体的架构和使用流程后,我会展开讲解 OpenMLDB 的产品特性。
2.4.1 OpenMLDB 产品特性一:线上线下一致性执行
之前讲过的一致性执行引擎,其实就是在内部去把 SQL 做了一个转换,转换成线上的执行计划和线下的执行计划,保证这两个值是从定义和执行逻辑上都是一致的。等于说线上线下一致性是在 OpenMLDB 的内部得到了一个天然的保障。
2.4.2 OpenMLDB 产品特性二:高性能在线特征计算引擎
第二个非常重要的特性,就是我们之前讲到的在线特征计算引擎。那我们怎么去保证在的计算的高性能呢?
第一,在线计算引擎加存储引擎都是我们自研的一个时序特征数据库,在内部它是一个双层的跳表结构,这有利于我们去高效地拿到窗口化的数据。
第二,我们做了一些预聚合的处理,部分特征可以提前去聚合计算,不需要等到查询时才准备。比方说需要过去一年内的商品点击量之前,我们可以把每个月的点击量先做好预聚合,当这个线上请求到来的时候,只需把每个月的点击量加起来再补充上最新的特征,就可以达到目的。 在这两种策略的加持下,我们和其他同样是 in memory 的数据库去做比较,可以看到在专门对这个特征工程做的窗口化查询需求下,OpenMLDB的性能会有非常大的优势。
2.4.3 OpenMLDB 产品特性三:面向特征计算的优化的离线计算引擎
第三个特性就是离线计算引擎的优化。
离线计算引擎是基于 Spark 的优化的版本,我们不是把原始的 Spark 直接拿来的,而是针对特征计优化做了一些措施,比如右边这个图,叫做多窗口的一些并行计算优化:SQL 定义了两个窗口,是在不同的 key 上面,一个是 group by name,一个是 group by age,这是两个时间窗口,在 Spark3.0 上翻译出来,这两个窗口会串行地去执行,有时候没法完全的非常好地利用集群的资源,所以我们在这里就改动了 Spark 的源代码,使其可以并行执行起来的,从而提升效率。这是其中的一个改动,其他的还有比如数据倾斜的优化,都是基于在 Spark 发行版里面去做的一些优化。左下角这个图显示了我们目前的版本和 Spark 原始版本的性能比对,可以看到,达到了一个非常显著的性能提升,特别是针对特征工程相关的操作。
2.4.4 OpenMLDB 产品特性四:针对特征工程的 SQL 扩展
特征四涉及到一个很常听到的疑问。因为我们是基于 SQL 去做这个特征工程,那大家很自然的会有一个问题——SQL 的表达能力是否足够?我们的回答是,原生的标准的 SQL 对某些比较复杂的特征处理逻辑上其实不是那么友好。但是,在 OpenMLDB 中,我们做了SQL语法和功能的扩展。
最典型例子是图片左边展示的 LAST JOIN,它能够在左表匹配到右表多行的时候只取最近的一条或者设定的某一条。这种场景在机器学习的这个训练里面有很多应用。
还有一个例子时 WINDOW UNION 的语法,从直观来理解,其实是做了一个跨表的窗口聚合操作。比方说这个左表(也是主表),左表的这个时间戳可以在右表的匹配的数据集上画一个时间窗口,在右表做一个聚合,然后把聚合结果拼到左表上。跨表聚合是 WINDOW UNION 所要达到最主要目的,当然它还有一些更复杂的用法,大家可以去参考我们的语法文档。
基于语法扩展和功能扩展,OpenMLDB 中 SQL 目前的表达能力是足够的。当然我们也看到社区用户其实可能有一些更高的要求,特别是针对一些这个计算函数,我们也在不断的扩展可能的新语法,包括新的 build in 函数,这块内容也非常欢迎大家来和我们一起做。
2.4.5 OpenMLDB 产品特性五:企业级特性支持
第五个非常重要的特性涉及到 OpenMLDB 的历史,它是从第四范式的商业产品转化而来,在开源之前已经应用于很多大规模的企业级应用里了,且在上百个场景里面都经过了实践。所以我们非常看重如何真正落到企业大规模企业级应用里的一些 feature,比方说高可用、扩缩融、平滑升级和企业级监控在如今的 OpenMLDB 中都是支持的。
最主要的一些企业级的 feature 已经在开源版本里列出来了,还有比如多租户、云原生,已经在我们的 roadmap 中,这一部分功能我们会不断地完善它,去更好的去为企业级应用做服务。
2.4.6 OpenMLDB 产品特性六:以SQL为核心的开发和管理体验
最后给大家分享一下这个 OpenMLDB 的一个非常重要的使用方式。我们认为它是一个数据库,最中心的一点就是 OpenMLDB 是以 SQL 为核心的全流程开发和管理体验,在 CLI 里面去做离线特征方案的开发,开发完离线特征计算,可以一步切换到这个SQL的方案上线,直接用一个 DEPLOY 命令把离线的方案切换到线上,就可以直接进入 serving 的服务。然后按步骤操作,就可以直接做线上请求,进行实时特征计算了。
通过一个 API 做线上请求,或者通过 Python,Java 的 SDK,都可以直接去跟 serving 的服务器做通信和线上请求。可以看到,基于 SQL 和基于 CLI 的开发非常低门槛以及方便。
2.5 OpenMLDB 上下游生态
将 OpenMLDB 投射到 MLOps 生命周期中,可以看到 OpenMLDB 占据着其中 FeatureOps 的位置,主要是做特征计算。
2.5.1 内部框架
先解析 OpenMLDB 内部框架,我们有这个 Online 引擎和 Offline 引擎。
Online 引擎又可以被细分为存储和执行。在其中的 SQL 执行层面,因为需要储存最新的实时数据的,所以我们会有一个 Storage engine,在默认情况下会有 in memory storage(build in)。它其实是非常高效的、专门面向时序数据库去优化的一个内存数据库。当然我们也可以数据存在磁盘上,把 RocksDB 插进来。所以 OpenMLDB v 0.5.0的版本会同时提供两种不同的 Storage Engine。如果你对性能需求特别高,可以选择 in memory storage engine。如果你对性能不太敏感但是重视成本,那么可以使用基于磁盘的存储(RocksDB)。
Online SQL Engine 这一块是我们自研的,用于高性能进行 SQL 计算。Offline 板块是基于Spark去做了合理的修改,称作这个 OpenMLDB 的 Spark 发行版,未来我们可能也会有其他的一些扩展。
2.5.2 Data sources
左边的是 DataOps,介绍了数据是如何获取的。比方说 Online data sources 板块,我们发布了 OpenMLDB Pulsar connector, 已经可以接入 Pulsar 的数据了。这个月发布的版本中,我们应该还会把 Kafka 的这个 connector 也同时发布出来,更加有利于这个大家数据的接入。在 Offline data sources 这一块呢,OpenMLDB 支持直接接入 HDFS、S3 数据 ,未来我们也会支持更多的数据源。
2.5.3 ModelOps
往右的 ModelOps 这边,其实是一些下游模型。下游模型通过一些标准输出格式,就能直接接入了。这个月会发布的新版本中,我们会把这个模型特征的功能整合进来,让它可以输出这个标准的 LIBSVM 或者 CSV 的格式,可以直接给到 Pytorch 等使用。
2.5.4 ProductionOps
我们也在做部署合和任务编排,OpenMLDB 已经和 Airflow 和 Kubeflow 做了对接,有望在近期完成与 Airflow 的合作内容。监控一块也是非常易于使用的,OpenMLDB 已经和 Prometheus 和 Grafana 做了对接。
2.6 拥抱前沿新硬件技术:基于持久内存的优化
在前沿技术创新上我们也有产出成果,这个是去年被录用的一个 VLDB 的 paper,VLDB 是国际数据库界最顶尖的学术界的会议,在 paper 里面我们讲了两个事情:
- 一是把我们整个 OpenMLDB 的实现架构都去仔细进行了描述,所以大家想了解这个架构的话可以也去参照一下 paper;
- 二是讲了怎么去跟今天的前沿的硬件技术做结合,前沿的硬件技术就是 persistent memory,即持久内存,以前在学术界叫做非易失性内存。
持久内存是英特尔在大概 18、 19 年左右,发布了真正工业界第一款企业级的持久内存应用,奥腾持久内存。那么持久内存有什么优势呢?首先它成本低,它的单位价格是 Dram的 1/3~1/4 左右。当然它的性能也会比 Dram 稍微差 1/2 或 1/3 左右,但是比 SSD 还是会好一个量级的。其次容量大,一条持久内存可以最高到 512 GB,一台服务器上就很容易达到几个 TB。还有一个非常革命性的技术,就是可持久性的内存。现在的 Dram 掉电以后数据都没了,而 Persistent memory 掉电以后这个数据还在,这个是一个非常革命性的技术。
我们把持久内存跟 OpenMLDB 线上执行引擎已经结合了起来。前面提到了线上执行引擎的特点,首先它是一个基本上是基于纯内存的执行引擎,所以把它运行起来的成本有时候还是挺高的,如果场景特别大,为了满足内存需求,需要十几台机器,才能运行起来。同时它也有恢复时间慢的问题,因为它一旦掉电,需要从外部存储重新构建内存镜像,需要较长的时间。
于是我们就把持久内存跟 OpenMLDB 的线上引擎给结合起来,达到了三个非常好的效果:
- 恢复时间从本来的 6 个小时级别降到了 1 分钟。线上业务的意义其实是非常巨大的,线上业务比方说点餐系统,是不允许长时间掉线的,或者不允许某节点掉线以后影响业务的服务质量。结合之后,一分钟就能把这个业务重新拉起来,就不会影响到服务质量。
- 由于一些底层架构的修改,也改进了 20% 的长尾延迟。在 TP9999 的情况下,这就非常显著。
- 减少了总成本。因为内存单台机器内存扩大,使用的机器数量就变少了,原来用 16 台,现在只需要 6 台,成本一下子就降下来了。
2.7 OpenMLDB 典型案例 – 某银行事中反欺诈交易
接下来举一个简单的例子,在某银行的事中反欺诈交易场景,OpenMLDB 其实就是处于 FeatureOps 的位置,同时衔接了离线批处理和实时特征计算。然后在某银行的业务场景里,他们对响应的要求是非常高的,需要延迟在 20 ms 以内。可以看到,相比较于它原来传统规则的系统、客户自研的系统,OpenMLDB 提供了一个更好的效果,满足了他们发展的业务需求。
2.8 OpenMLDB 的历史
其实 OpenMLDB 是从第四范式成立第一天就开始做的产品。经过了 5 年的研发沉淀,OpenMLDB 跟随着商业产品经历了上百个项目的验证,累积了非常多的案例。
3 | 面向开源开放的 OpenMLDB 社区发展
3.1 OpenMLDB 发展历程
OpenMLDB 真正开源是去年的 6 月,我们其中的关键组件重新从商业平台中抽取出来,做了包装和优化形成了 OpenMLDB 今天的形态,并且对外开源,贡献给社区。我们开源后收获了不错的反馈,去年 9 月收获了第一个开源企业用户 Akulaku,今年我们也看到很多新团队在不断深入使用 OpenMLDB。
3.2 OpenMLDB 开源基本信息
这张图上是 OpenMLDB 的一些基本信息,大家可以简单了解。
3.3 感谢OpenMLDB的社区开发者
趁这个机会,我想再次感谢一下 OpenMLDB 的社区开发者。到目前为止,共有 51 位开发者加入社区。是大家不断地投入时间精力,OpenMLDB 才能被推动着不断往前发展。从 0.4.0 版本以来,又有 15 位新加入的开发者为社区做出了贡献。在这里,我想表示诚挚的感谢。如果大家对 OpenMLDB 感兴趣,也非常欢迎你作为新伙伴加入。
3.4 OpenMLDB v0.5.0 主要特性
最后想重点给大家介绍 OpenMLDB v0.5.0的新特性,预计在 4 月底发布。
- 预聚合技术应用到长窗口上。这个长窗口指的是时间窗口非常大,包含上百万条数据,针对这块数据做优化处理,我们会把预聚合技术应用进去,指数级提升长窗口聚合性能。
- 提供一个新的针对磁盘的存储引擎。如果你对价格敏感的话,可以选者这种 RocksDB 的外存储存。这样使得线上存储引擎可插拔以适配不同业务需求,既可以支持基于内存的高性能存储引擎,也可以支持基于外存的大容量低成本存储引擎,还可以支持基于持久内存的存储引擎以在性能和成本间保持平衡。
- UDF(用户自定义函数)支持,也会在加入到产品中,大幅提升易用性和适用性。
- 支持基于哈希的离散特征编码,以及编码后特征输出到CSV合LIBSVM格式,直接应用到模型训练合模型推理。
- 完善的监控能力,在企业级应用环境中大幅提升稳定性、可观测性、和可分析性。
- 上下游数据源生态整合,提供多种数据源 connectors,包括线上数据源的 Kafka, Pulsar connectors 等等。
3.5 OpenMLDB 后续重要特性
后续规划中 OpenMLDB 特性会朝着三个主要目标去走,三个主要目标就是降低使用门槛,降低使用成本,以及跟上下游生态的打通。
后续迭代都会不断地朝着这三个目标走。比方去规划一个 Cloud native 的 OpenMLDB 版本,包括自动特征工程,可能是今天用户还需要写 SQL,而在未来 SQL 可以根据数据去自动生成。以及还有基于异构硬件的优化,非结构化数据的支持,特征版本合血缘关系管理。大家对某个 feature 特别感兴趣或者特别需要的话,可以通过社区、Github 等渠道进行反馈,我们会去根据社区的反馈去看需求的优先级,也非常欢迎来自社区的共同开发。
3.6 欢迎加入 OpenMLDB 开源社区
上次 Meetup 时,我预告了官网的上线。如今 OpenMLDB 官网已经顺利推出,欢迎大家访问。或者也可以访问我们的 Github 页面,加入我们的微信交流群,又或是我的个人微信探讨交流。
今天的分享就到这里了,感谢大家。
- 工具能力的不一致性。离线开发和线上应用,使用的工具栈和开发栈可能是完全不一样的。
- 需求沟通的认知差。这不是一个技术问题,但是在实际工程落地当中非常重要。
线上线下一致性校验带来的高昂工程化落地成本
因为线上线下的一致性问题的产生,校验是必然的。一次性校验带来了很多成本上的问题:
- 需要两组不同技能栈的开发人员投入,才能去完成从线下到线上的部署的过程。
- 线上线下两套系统的开发和运营。
这两点在工程化落地成本、开发成本、人力成本上面,都有非常大的代价。
为了解决这个问题,国内外的头部企业会花费上千个小时自研构建平台保证线上线下一致性,这个平台和企业内部产品是深度耦合的。除了这些有着超强研发能力的头部企业以外,剩下的大部分企业因为投入研发的成本可能比采购的成本更高,更多地会采购一些Saas工具和服务来解决这个问题。
而今天,OpenMLDB 就提供了另外一种可能,我们提供开源的解决方案,提供 FeatureOps 的企业级解决方案,帮助企业去做到低成本高效率地解决痛难点。
2 | OpenMLDB 为企业提供线上线计算一致的生产级特征计算平台开源解决方案
2.1 OpenMLDB 架构以及说明
这张图展示的是 OpenMLDB 的架构。
从外围来看,我们提供了统一的 SQL 接口。
对开发人员来讲,开发不再需要两套接口。数据科学家在离线开发过程当中写的 SQL,就是最后上线的 SQL,这两者是天然统一的。对外部的开发者来说,语言转化为同一种,数据科学家写的 SQL 不需要工程化团队翻译,就能直接上线。
为了保证这个功能,OpenMLDB 内部设有统一的计算执行引擎,做统一的底层计算逻辑,以及逻辑计划到物理计划的翻译。拿来同一个 SQL,就能翻译成合适的、保证两者一致性的执行计划给到线上计算引擎。
关注上下结构,可以看到线下和线上的两套计算引擎。
因为前面提到过,线上和线下两者的性能要求其实是完全不一样的,所以计算引擎还是分开的状态。
线下做离线开发的时候,我们看重的是数据规模以及批处理的效率,所以线下模块本质上还是我们在 Spark 的基础上做了一些改进。
线上看重的是线上服务的低延迟、高吞吐、高并发,线上服务可能只能接受十几到几十毫秒这种量级的延迟。为了达到这个目的,线上的整个计算引擎是我们团队从头开发的一套 in memory 的基于纯内存的内存索引结构,是一个非常高效的基于内存运算的时序数据库。
这中间还有一个非常重要的构成——一致性执行引擎。
一致性执行引擎最重要的工作就是保障线上线下执行逻辑的一致性。表面上来看,就是拿一个统一的 SQL,既能转换到 Spark 去做,对离线批处理也能转换到自研的时序数据库,进行线上的高性能SQL查询。
线上线下会共享一些统一的计算函数,更重要的是,会存在一个逻辑计划到物理计划的线上线下执行模式的自适应。因为线上和线下执行的时候,数据形态是非常不一样的,做离线开发的时候,不管是 label 的样本表还是物料表,都是批处理的模式,在线上时一条一条传输过来,我们更看重的是一条一条的内存,所以会做一些细节上的转换,更好地达到性能要求。
那么通过的中间的执行引擎,一方面是达到线上线下的一致性,另一方面也能达到线上和线下的不同的执行效率的要求。也就是说在OpenMLDB内部已经做到了线上线下的一致性,不再需要额外的人力。
总结来说,OpenMLDB 做到了开发及上线的三步骤:
- 线下SQL特征脚本开发
- 一键部署上线
- 接入实时请求数据流
(这里解释一下实时数据流的概念,例如我们需要三月以来的购物数据作为数据流,随着系统外现实世界的时间推移,数据流的内容也会过期,需要更新,那么需要实时的数据流接近,不断把最新的三个月数据保留在内部。这也是我们和 Pulsar 合作打造新的基于数据流的接口的原因,在这方面 OpenMLDB 下一步还会持续优化。)
2.2 OpenMLDB 应用场景和方式
在应用场景和方式的介绍中,我们使用这样一张图表,越往右离线计算性能需求越高,越往上实时计算需求越高,通过两条虚线,把它划为四个象限。我们暂且不讲左下角的需求,重点介绍其他三个象限。
右上象限就是我们刚才提到的场景,需要从离线开发到实时线上计算的完整流程,可以用我们 OpenMLDB 完整的离线到实时上线流程去做这个开发和业务上线。这个过程中会用到我们的离线引擎和在线引擎,也能享受到线上线下一致性的功能,是我们认为的最典型的一种使用方式。
左上象限的场景也是我们在实际中接触过的应用场景,当很多小伙伴开始试用 OpenMLDB 的时候,其实已经有很多现存的业务逻辑了,这个时候可以只想利用OpenMLDB高性能的线上计算引擎。OpenMLDB 的离线和在线引擎是一个解耦的状态,所以能够满足单独使用在线引擎去做实时特征计算。当然这个地方的线上线下一致性无法得到 非常严格的保证了。如果你后期需要应用到新的场景,或者一致性需要得到非常强的验证,可能还是要通过 OpenMLDB 走完整的离线到实时上线流程。
还有一种需求,如右下象限所示。如果不需要做实时特征计算,或者不需要去做上线,可能只需要做一个探索,或是做模型推理研究,没有上线需求,那也可以用到 OpenMLDB 的离线引擎,就是通过我们改进的 Spark 版本做开发,改进版本会对离线特征抽取的性能起到非常大的改善作用。
这三种使用方式不仅在企业用户还是在社区用户中都有存在。
2.3 从离线开发到线上服务完整流程
接着,我会从我们最推荐的离线开发到线上服务的完整流程来讲解。
首先,我们会做离线的模式,把离线的数据导到 OpenMLDB,可以是软链的导入方式。此处的 Offline database 是一个虚拟概念化的存在,此时我们就可以做一个离线模型特征脚本的开发,在这个过程中和 Model training 可能也会有一个交互,要反复去调整。待到性能达到预期后,我们可以做一个动作,即 SQL deployment。把 SQL 部署上线,那么 OpenMLDB 的部署模式就会从 Offline 转至 Online。
在 Online 的首要工作是冷启动,导入需要的数据。我们特征脚本一般是面向时序数据的,所以会在窗口上做计算。假设我只需要最近三个月的数据,那我在上线的时间点需要在冷启动的时候把最近三个月的数据导入。而实际上,最近三个月的数据是不够的,因为现实世界的时间是不断推移的,所以需要不断更新这个 Online database。因此,OpenMLDB 需要接入在线的实时数据流。当然这里也提供 SDK,也支持通过 SDK 去实时地插入数据。
做完这一步已经万事具备,此时你可以使用 Preview 功能去看一下线上数据导入是否正确,但这是可选的。
做到这一步呢,整个 OpenMLD B就会转入一个叫做 Request mode,已经处在一个可以做实时计算的这个模式当中了。在我刚才讲述的例子中,小李搜索洗衣机关键字的信息进来后,系统就能结合计算逻辑和数据源坐等返回的特定结果了。这样一个 OpenMLDB 使用流程在我们的产品文档里有更进一步的描述。
2.4 OpenMLDB 产品特性
在介绍完 OpenMLDB 整体的架构和使用流程后,我会展开讲解 OpenMLDB 的产品特性。
2.4.1 OpenMLDB 产品特性一:线上线下一致性执行
之前讲过的一致性执行引擎,其实就是在内部去把 SQL 做了一个转换,转换成线上的执行计划和线下的执行计划,保证这两个值是从定义和执行逻辑上都是一致的。等于说线上线下一致性是在 OpenMLDB 的内部得到了一个天然的保障。
2.4.2 OpenMLDB 产品特性二:高性能在线特征计算引擎
第二个非常重要的特性,就是我们之前讲到的在线特征计算引擎。那我们怎么去保证在的计算的高性能呢?
第一,在线计算引擎加存储引擎都是我们自研的一个时序特征数据库,在内部它是一个双层的跳表结构,这有利于我们去高效地拿到窗口化的数据。
第二,我们做了一些预聚合的处理,部分特征可以提前去聚合计算,不需要等到查询时才准备。比方说需要过去一年内的商品点击量之前,我们可以把每个月的点击量先做好预聚合,当这个线上请求到来的时候,只需把每个月的点击量加起来再补充上最新的特征,就可以达到目的。 在这两种策略的加持下,我们和其他同样是 in memory 的数据库去做比较,可以看到在专门对这个特征工程做的窗口化查询需求下,OpenMLDB的性能会有非常大的优势。
2.4.3 OpenMLDB 产品特性三:面向特征计算的优化的离线计算引擎
第三个特性就是离线计算引擎的优化。
离线计算引擎是基于 Spark 的优化的版本,我们不是把原始的 Spark 直接拿来的,而是针对特征计优化做了一些措施,比如右边这个图,叫做多窗口的一些并行计算优化:SQL 定义了两个窗口,是在不同的 key 上面,一个是 group by name,一个是 group by age,这是两个时间窗口,在 Spark3.0 上翻译出来,这两个窗口会串行地去执行,有时候没法完全的非常好地利用集群的资源,所以我们在这里就改动了 Spark 的源代码,使其可以并行执行起来的,从而提升效率。这是其中的一个改动,其他的还有比如数据倾斜的优化,都是基于在 Spark 发行版里面去做的一些优化。左下角这个图显示了我们目前的版本和 Spark 原始版本的性能比对,可以看到,达到了一个非常显著的性能提升,特别是针对特征工程相关的操作。
2.4.4 OpenMLDB 产品特性四:针对特征工程的 SQL 扩展
特征四涉及到一个很常听到的疑问。因为我们是基于 SQL 去做这个特征工程,那大家很自然的会有一个问题——SQL 的表达能力是否足够?我们的回答是,原生的标准的 SQL 对某些比较复杂的特征处理逻辑上其实不是那么友好。但是,在 OpenMLDB 中,我们做了SQL语法和功能的扩展。
最典型例子是图片左边展示的 LAST JOIN,它能够在左表匹配到右表多行的时候只取最近的一条或者设定的某一条。这种场景在机器学习的这个训练里面有很多应用。
还有一个例子时 WINDOW UNION 的语法,从直观来理解,其实是做了一个跨表的窗口聚合操作。比方说这个左表(也是主表),左表的这个时间戳可以在右表的匹配的数据集上画一个时间窗口,在右表做一个聚合,然后把聚合结果拼到左表上。跨表聚合是 WINDOW UNION 所要达到最主要目的,当然它还有一些更复杂的用法,大家可以去参考我们的语法文档。
基于语法扩展和功能扩展,OpenMLDB 中 SQL 目前的表达能力是足够的。当然我们也看到社区用户其实可能有一些更高的要求,特别是针对一些这个计算函数,我们也在不断的扩展可能的新语法,包括新的 build in 函数,这块内容也非常欢迎大家来和我们一起做。
2.4.5 OpenMLDB 产品特性五:企业级特性支持
第五个非常重要的特性涉及到 OpenMLDB 的历史,它是从第四范式的商业产品转化而来,在开源之前已经应用于很多大规模的企业级应用里了,且在上百个场景里面都经过了实践。所以我们非常看重如何真正落到企业大规模企业级应用里的一些 feature,比方说高可用、扩缩融、平滑升级和企业级监控在如今的 OpenMLDB 中都是支持的。
最主要的一些企业级的 feature 已经在开源版本里列出来了,还有比如多租户、云原生,已经在我们的 roadmap 中,这一部分功能我们会不断地完善它,去更好的去为企业级应用做服务。
2.4.6 OpenMLDB 产品特性六:以SQL为核心的开发和管理体验
最后给大家分享一下这个 OpenMLDB 的一个非常重要的使用方式。我们认为它是一个数据库,最中心的一点就是 OpenMLDB 是以 SQL 为核心的全流程开发和管理体验,在 CLI 里面去做离线特征方案的开发,开发完离线特征计算,可以一步切换到这个SQL的方案上线,直接用一个 DEPLOY 命令把离线的方案切换到线上,就可以直接进入 serving 的服务。然后按步骤操作,就可以直接做线上请求,进行实时特征计算了。
通过一个 API 做线上请求,或者通过 Python,Java 的 SDK,都可以直接去跟 serving 的服务器做通信和线上请求。可以看到,基于 SQL 和基于 CLI 的开发非常低门槛以及方便。
2.5 OpenMLDB 上下游生态
将 OpenMLDB 投射到 MLOps 生命周期中,可以看到 OpenMLDB 占据着其中 FeatureOps 的位置,主要是做特征计算。
2.5.1 内部框架
先解析 OpenMLDB 内部框架,我们有这个 Online 引擎和 Offline 引擎。
Online 引擎又可以被细分为存储和执行。在其中的 SQL 执行层面,因为需要储存最新的实时数据的,所以我们会有一个 Storage engine,在默认情况下会有 in memory storage(build in)。它其实是非常高效的、专门面向时序数据库去优化的一个内存数据库。当然我们也可以数据存在磁盘上,把 RocksDB 插进来。所以 OpenMLDB v 0.5.0的版本会同时提供两种不同的 Storage Engine。如果你对性能需求特别高,可以选择 in memory storage engine。如果你对性能不太敏感但是重视成本,那么可以使用基于磁盘的存储(RocksDB)。
Online SQL Engine 这一块是我们自研的,用于高性能进行 SQL 计算。Offline 板块是基于Spark去做了合理的修改,称作这个 OpenMLDB 的 Spark 发行版,未来我们可能也会有其他的一些扩展。
2.5.2 Data sources
左边的是 DataOps,介绍了数据是如何获取的。比方说 Online data sources 板块,我们发布了 OpenMLDB Pulsar connector, 已经可以接入 Pulsar 的数据了。这个月发布的版本中,我们应该还会把 Kafka 的这个 connector 也同时发布出来,更加有利于这个大家数据的接入。在 Offline data sources 这一块呢,OpenMLDB 支持直接接入 HDFS、S3 数据 ,未来我们也会支持更多的数据源。
2.5.3 ModelOps
往右的 ModelOps 这边,其实是一些下游模型。下游模型通过一些标准输出格式,就能直接接入了。这个月会发布的新版本中,我们会把这个模型特征的功能整合进来,让它可以输出这个标准的 LIBSVM 或者 CSV 的格式,可以直接给到 Pytorch 等使用。
2.5.4 ProductionOps
我们也在做部署合和任务编排,OpenMLDB 已经和 Airflow 和 Kubeflow 做了对接,有望在近期完成与 Airflow 的合作内容。监控一块也是非常易于使用的,OpenMLDB 已经和 Prometheus 和 Grafana 做了对接。
2.6 拥抱前沿新硬件技术:基于持久内存的优化
在前沿技术创新上我们也有产出成果,这个是去年被录用的一个 VLDB 的 paper,VLDB 是国际数据库界最顶尖的学术界的会议,在 paper 里面我们讲了两个事情:
- 一是把我们整个 OpenMLDB 的实现架构都去仔细进行了描述,所以大家想了解这个架构的话可以也去参照一下 paper;
- 二是讲了怎么去跟今天的前沿的硬件技术做结合,前沿的硬件技术就是 persistent memory,即持久内存,以前在学术界叫做非易失性内存。
持久内存是英特尔在大概 18、 19 年左右,发布了真正工业界第一款企业级的持久内存应用,奥腾持久内存。那么持久内存有什么优势呢?首先它成本低,它的单位价格是 Dram的 1/3~1/4 左右。当然它的性能也会比 Dram 稍微差 1/2 或 1/3 左右,但是比 SSD 还是会好一个量级的。其次容量大,一条持久内存可以最高到 512 GB,一台服务器上就很容易达到几个 TB。还有一个非常革命性的技术,就是可持久性的内存。现在的 Dram 掉电以后数据都没了,而 Persistent memory 掉电以后这个数据还在,这个是一个非常革命性的技术。
我们把持久内存跟 OpenMLDB 线上执行引擎已经结合了起来。前面提到了线上执行引擎的特点,首先它是一个基本上是基于纯内存的执行引擎,所以把它运行起来的成本有时候还是挺高的,如果场景特别大,为了满足内存需求,需要十几台机器,才能运行起来。同时它也有恢复时间慢的问题,因为它一旦掉电,需要从外部存储重新构建内存镜像,需要较长的时间。
于是我们就把持久内存跟 OpenMLDB 的线上引擎给结合起来,达到了三个非常好的效果:
- 恢复时间从本来的 6 个小时级别降到了 1 分钟。线上业务的意义其实是非常巨大的,线上业务比方说点餐系统,是不允许长时间掉线的,或者不允许某节点掉线以后影响业务的服务质量。结合之后,一分钟就能把这个业务重新拉起来,就不会影响到服务质量。
- 由于一些底层架构的修改,也改进了 20% 的长尾延迟。在 TP9999 的情况下,这就非常显著。
- 减少了总成本。因为内存单台机器内存扩大,使用的机器数量就变少了,原来用 16 台,现在只需要 6 台,成本一下子就降下来了。
2.7 OpenMLDB 典型案例 – 某银行事中反欺诈交易
接下来举一个简单的例子,在某银行的事中反欺诈交易场景,OpenMLDB 其实就是处于 FeatureOps 的位置,同时衔接了离线批处理和实时特征计算。然后在某银行的业务场景里,他们对响应的要求是非常高的,需要延迟在 20 ms 以内。可以看到,相比较于它原来传统规则的系统、客户自研的系统,OpenMLDB 提供了一个更好的效果,满足了他们发展的业务需求。
2.8 OpenMLDB 的历史
其实 OpenMLDB 是从第四范式成立第一天就开始做的产品。经过了 5 年的研发沉淀,OpenMLDB 跟随着商业产品经历了上百个项目的验证,累积了非常多的案例。
3 | 面向开源开放的 OpenMLDB 社区发展
3.1 OpenMLDB 发展历程
OpenMLDB 真正开源是去年的 6 月,我们其中的关键组件重新从商业平台中抽取出来,做了包装和优化形成了 OpenMLDB 今天的形态,并且对外开源,贡献给社区。我们开源后收获了不错的反馈,去年 9 月收获了第一个开源企业用户 Akulaku,今年我们也看到很多新团队在不断深入使用 OpenMLDB。
3.2 OpenMLDB 开源基本信息
这张图上是 OpenMLDB 的一些基本信息,大家可以简单了解。
3.3 感谢OpenMLDB的社区开发者
趁这个机会,我想再次感谢一下 OpenMLDB 的社区开发者。到目前为止,共有 51 位开发者加入社区。是大家不断地投入时间精力,OpenMLDB 才能被推动着不断往前发展。从 0.4.0 版本以来,又有 15 位新加入的开发者为社区做出了贡献。在这里,我想表示诚挚的感谢。如果大家对 OpenMLDB 感兴趣,也非常欢迎你作为新伙伴加入。
3.4 OpenMLDB v0.5.0 主要特性
最后想重点给大家介绍 OpenMLDB v0.5.0的新特性,预计在 4 月底发布。
- 预聚合技术应用到长窗口上。这个长窗口指的是时间窗口非常大,包含上百万条数据,针对这块数据做优化处理,我们会把预聚合技术应用进去,指数级提升长窗口聚合性能。
- 提供一个新的针对磁盘的存储引擎。如果你对价格敏感的话,可以选者这种 RocksDB 的外存储存。这样使得线上存储引擎可插拔以适配不同业务需求,既可以支持基于内存的高性能存储引擎,也可以支持基于外存的大容量低成本存储引擎,还可以支持基于持久内存的存储引擎以在性能和成本间保持平衡。
- UDF(用户自定义函数)支持,也会在加入到产品中,大幅提升易用性和适用性。
- 支持基于哈希的离散特征编码,以及编码后特征输出到CSV合LIBSVM格式,直接应用到模型训练合模型推理。
- 完善的监控能力,在企业级应用环境中大幅提升稳定性、可观测性、和可分析性。
- 上下游数据源生态整合,提供多种数据源 connectors,包括线上数据源的 Kafka, Pulsar connectors 等等。
3.5 OpenMLDB 后续重要特性
后续规划中 OpenMLDB 特性会朝着三个主要目标去走,三个主要目标就是降低使用门槛,降低使用成本,以及跟上下游生态的打通。
后续迭代都会不断地朝着这三个目标走。比方去规划一个 Cloud native 的 OpenMLDB 版本,包括自动特征工程,可能是今天用户还需要写 SQL,而在未来 SQL 可以根据数据去自动生成。以及还有基于异构硬件的优化,非结构化数据的支持,特征版本合血缘关系管理。大家对某个 feature 特别感兴趣或者特别需要的话,可以通过社区、Github 等渠道进行反馈,我们会去根据社区的反馈去看需求的优先级,也非常欢迎来自社区的共同开发。
3.6 欢迎加入 OpenMLDB 开源社区
上次 Meetup 时,我预告了官网的上线。如今 OpenMLDB 官网已经顺利推出,欢迎大家访问。或者也可以访问我们的 Github 页面,加入我们的微信交流群,又或是我的个人微信探讨交流。
今天的分享就到这里了,感谢大家。
从外围来看,我们提供了统一的 SQL 接口。
对开发人员来讲,开发不再需要两套接口。数据科学家在离线开发过程当中写的 SQL,就是最后上线的 SQL,这两者是天然统一的。对外部的开发者来说,语言转化为同一种,数据科学家写的 SQL 不需要工程化团队翻译,就能直接上线。
为了保证这个功能,OpenMLDB 内部设有统一的计算执行引擎,做统一的底层计算逻辑,以及逻辑计划到物理计划的翻译。拿来同一个 SQL,就能翻译成合适的、保证两者一致性的执行计划给到线上计算引擎。
关注上下结构,可以看到线下和线上的两套计算引擎。
因为前面提到过,线上和线下两者的性能要求其实是完全不一样的,所以计算引擎还是分开的状态。
线下做离线开发的时候,我们看重的是数据规模以及批处理的效率,所以线下模块本质上还是我们在 Spark 的基础上做了一些改进。
线上看重的是线上服务的低延迟、高吞吐、高并发,线上服务可能只能接受十几到几十毫秒这种量级的延迟。为了达到这个目的,线上的整个计算引擎是我们团队从头开发的一套 in memory 的基于纯内存的内存索引结构,是一个非常高效的基于内存运算的时序数据库。
这中间还有一个非常重要的构成——一致性执行引擎。
一致性执行引擎最重要的工作就是保障线上线下执行逻辑的一致性。表面上来看,就是拿一个统一的 SQL,既能转换到 Spark 去做,对离线批处理也能转换到自研的时序数据库,进行线上的高性能SQL查询。
线上线下会共享一些统一的计算函数,更重要的是,会存在一个逻辑计划到物理计划的线上线下执行模式的自适应。因为线上和线下执行的时候,数据形态是非常不一样的,做离线开发的时候,不管是 label 的样本表还是物料表,都是批处理的模式,在线上时一条一条传输过来,我们更看重的是一条一条的内存,所以会做一些细节上的转换,更好地达到性能要求。
那么通过的中间的执行引擎,一方面是达到线上线下的一致性,另一方面也能达到线上和线下的不同的执行效率的要求。也就是说在OpenMLDB内部已经做到了线上线下的一致性,不再需要额外的人力。
总结来说,OpenMLDB 做到了开发及上线的三步骤:
- 线下SQL特征脚本开发
- 一键部署上线
- 接入实时请求数据流
2.2 OpenMLDB 应用场景和方式
在应用场景和方式的介绍中,我们使用这样一张图表,越往右离线计算性能需求越高,越往上实时计算需求越高,通过两条虚线,把它划为四个象限。我们暂且不讲左下角的需求,重点介绍其他三个象限。
右上象限就是我们刚才提到的场景,需要从离线开发到实时线上计算的完整流程,可以用我们 OpenMLDB 完整的离线到实时上线流程去做这个开发和业务上线。这个过程中会用到我们的离线引擎和在线引擎,也能享受到线上线下一致性的功能,是我们认为的最典型的一种使用方式。
左上象限的场景也是我们在实际中接触过的应用场景,当很多小伙伴开始试用 OpenMLDB 的时候,其实已经有很多现存的业务逻辑了,这个时候可以只想利用OpenMLDB高性能的线上计算引擎。OpenMLDB 的离线和在线引擎是一个解耦的状态,所以能够满足单独使用在线引擎去做实时特征计算。当然这个地方的线上线下一致性无法得到 非常严格的保证了。如果你后期需要应用到新的场景,或者一致性需要得到非常强的验证,可能还是要通过 OpenMLDB 走完整的离线到实时上线流程。
还有一种需求,如右下象限所示。如果不需要做实时特征计算,或者不需要去做上线,可能只需要做一个探索,或是做模型推理研究,没有上线需求,那也可以用到 OpenMLDB 的离线引擎,就是通过我们改进的 Spark 版本做开发,改进版本会对离线特征抽取的性能起到非常大的改善作用。
这三种使用方式不仅在企业用户还是在社区用户中都有存在。
2.3 从离线开发到线上服务完整流程
接着,我会从我们最推荐的离线开发到线上服务的完整流程来讲解。
首先,我们会做离线的模式,把离线的数据导到 OpenMLDB,可以是软链的导入方式。此处的 Offline database 是一个虚拟概念化的存在,此时我们就可以做一个离线模型特征脚本的开发,在这个过程中和 Model training 可能也会有一个交互,要反复去调整。待到性能达到预期后,我们可以做一个动作,即 SQL deployment。把 SQL 部署上线,那么 OpenMLDB 的部署模式就会从 Offline 转至 Online。
在 Online 的首要工作是冷启动,导入需要的数据。我们特征脚本一般是面向时序数据的,所以会在窗口上做计算。假设我只需要最近三个月的数据,那我在上线的时间点需要在冷启动的时候把最近三个月的数据导入。而实际上,最近三个月的数据是不够的,因为现实世界的时间是不断推移的,所以需要不断更新这个 Online database。因此,OpenMLDB 需要接入在线的实时数据流。当然这里也提供 SDK,也支持通过 SDK 去实时地插入数据。
做完这一步已经万事具备,此时你可以使用 Preview 功能去看一下线上数据导入是否正确,但这是可选的。
做到这一步呢,整个 OpenMLD B就会转入一个叫做 Request mode,已经处在一个可以做实时计算的这个模式当中了。在我刚才讲述的例子中,小李搜索洗衣机关键字的信息进来后,系统就能结合计算逻辑和数据源坐等返回的特定结果了。这样一个 OpenMLDB 使用流程在我们的产品文档里有更进一步的描述。
2.4 OpenMLDB 产品特性
在介绍完 OpenMLDB 整体的架构和使用流程后,我会展开讲解 OpenMLDB 的产品特性。
2.4.1 OpenMLDB 产品特性一:线上线下一致性执行
之前讲过的一致性执行引擎,其实就是在内部去把 SQL 做了一个转换,转换成线上的执行计划和线下的执行计划,保证这两个值是从定义和执行逻辑上都是一致的。等于说线上线下一致性是在 OpenMLDB 的内部得到了一个天然的保障。
2.4.2 OpenMLDB 产品特性二:高性能在线特征计算引擎
第二个非常重要的特性,就是我们之前讲到的在线特征计算引擎。那我们怎么去保证在的计算的高性能呢?
第一,在线计算引擎加存储引擎都是我们自研的一个时序特征数据库,在内部它是一个双层的跳表结构,这有利于我们去高效地拿到窗口化的数据。
第二,我们做了一些预聚合的处理,部分特征可以提前去聚合计算,不需要等到查询时才准备。比方说需要过去一年内的商品点击量之前,我们可以把每个月的点击量先做好预聚合,当这个线上请求到来的时候,只需把每个月的点击量加起来再补充上最新的特征,就可以达到目的。 在这两种策略的加持下,我们和其他同样是 in memory 的数据库去做比较,可以看到在专门对这个特征工程做的窗口化查询需求下,OpenMLDB的性能会有非常大的优势。
2.4.3 OpenMLDB 产品特性三:面向特征计算的优化的离线计算引擎
第三个特性就是离线计算引擎的优化。
离线计算引擎是基于 Spark 的优化的版本,我们不是把原始的 Spark 直接拿来的,而是针对特征计优化做了一些措施,比如右边这个图,叫做多窗口的一些并行计算优化:SQL 定义了两个窗口,是在不同的 key 上面,一个是 group by name,一个是 group by age,这是两个时间窗口,在 Spark3.0 上翻译出来,这两个窗口会串行地去执行,有时候没法完全的非常好地利用集群的资源,所以我们在这里就改动了 Spark 的源代码,使其可以并行执行起来的,从而提升效率。这是其中的一个改动,其他的还有比如数据倾斜的优化,都是基于在 Spark 发行版里面去做的一些优化。左下角这个图显示了我们目前的版本和 Spark 原始版本的性能比对,可以看到,达到了一个非常显著的性能提升,特别是针对特征工程相关的操作。
2.4.4 OpenMLDB 产品特性四:针对特征工程的 SQL 扩展
特征四涉及到一个很常听到的疑问。因为我们是基于 SQL 去做这个特征工程,那大家很自然的会有一个问题——SQL 的表达能力是否足够?我们的回答是,原生的标准的 SQL 对某些比较复杂的特征处理逻辑上其实不是那么友好。但是,在 OpenMLDB 中,我们做了SQL语法和功能的扩展。
最典型例子是图片左边展示的 LAST JOIN,它能够在左表匹配到右表多行的时候只取最近的一条或者设定的某一条。这种场景在机器学习的这个训练里面有很多应用。
还有一个例子时 WINDOW UNION 的语法,从直观来理解,其实是做了一个跨表的窗口聚合操作。比方说这个左表(也是主表),左表的这个时间戳可以在右表的匹配的数据集上画一个时间窗口,在右表做一个聚合,然后把聚合结果拼到左表上。跨表聚合是 WINDOW UNION 所要达到最主要目的,当然它还有一些更复杂的用法,大家可以去参考我们的语法文档。
基于语法扩展和功能扩展,OpenMLDB 中 SQL 目前的表达能力是足够的。当然我们也看到社区用户其实可能有一些更高的要求,特别是针对一些这个计算函数,我们也在不断的扩展可能的新语法,包括新的 build in 函数,这块内容也非常欢迎大家来和我们一起做。
2.4.5 OpenMLDB 产品特性五:企业级特性支持
第五个非常重要的特性涉及到 OpenMLDB 的历史,它是从第四范式的商业产品转化而来,在开源之前已经应用于很多大规模的企业级应用里了,且在上百个场景里面都经过了实践。所以我们非常看重如何真正落到企业大规模企业级应用里的一些 feature,比方说高可用、扩缩融、平滑升级和企业级监控在如今的 OpenMLDB 中都是支持的。
最主要的一些企业级的 feature 已经在开源版本里列出来了,还有比如多租户、云原生,已经在我们的 roadmap 中,这一部分功能我们会不断地完善它,去更好的去为企业级应用做服务。
2.4.6 OpenMLDB 产品特性六:以SQL为核心的开发和管理体验
最后给大家分享一下这个 OpenMLDB 的一个非常重要的使用方式。我们认为它是一个数据库,最中心的一点就是 OpenMLDB 是以 SQL 为核心的全流程开发和管理体验,在 CLI 里面去做离线特征方案的开发,开发完离线特征计算,可以一步切换到这个SQL的方案上线,直接用一个 DEPLOY 命令把离线的方案切换到线上,就可以直接进入 serving 的服务。然后按步骤操作,就可以直接做线上请求,进行实时特征计算了。
通过一个 API 做线上请求,或者通过 Python,Java 的 SDK,都可以直接去跟 serving 的服务器做通信和线上请求。可以看到,基于 SQL 和基于 CLI 的开发非常低门槛以及方便。
2.5 OpenMLDB 上下游生态
将 OpenMLDB 投射到 MLOps 生命周期中,可以看到 OpenMLDB 占据着其中 FeatureOps 的位置,主要是做特征计算。
2.5.1 内部框架
先解析 OpenMLDB 内部框架,我们有这个 Online 引擎和 Offline 引擎。
Online 引擎又可以被细分为存储和执行。在其中的 SQL 执行层面,因为需要储存最新的实时数据的,所以我们会有一个 Storage engine,在默认情况下会有 in memory storage(build in)。它其实是非常高效的、专门面向时序数据库去优化的一个内存数据库。当然我们也可以数据存在磁盘上,把 RocksDB 插进来。所以 OpenMLDB v 0.5.0的版本会同时提供两种不同的 Storage Engine。如果你对性能需求特别高,可以选择 in memory storage engine。如果你对性能不太敏感但是重视成本,那么可以使用基于磁盘的存储(RocksDB)。
Online SQL Engine 这一块是我们自研的,用于高性能进行 SQL 计算。Offline 板块是基于Spark去做了合理的修改,称作这个 OpenMLDB 的 Spark 发行版,未来我们可能也会有其他的一些扩展。
2.5.2 Data sources
左边的是 DataOps,介绍了数据是如何获取的。比方说 Online data sources 板块,我们发布了 OpenMLDB Pulsar connector, 已经可以接入 Pulsar 的数据了。这个月发布的版本中,我们应该还会把 Kafka 的这个 connector 也同时发布出来,更加有利于这个大家数据的接入。在 Offline data sources 这一块呢,OpenMLDB 支持直接接入 HDFS、S3 数据 ,未来我们也会支持更多的数据源。
2.5.3 ModelOps
往右的 ModelOps 这边,其实是一些下游模型。下游模型通过一些标准输出格式,就能直接接入了。这个月会发布的新版本中,我们会把这个模型特征的功能整合进来,让它可以输出这个标准的 LIBSVM 或者 CSV 的格式,可以直接给到 Pytorch 等使用。
2.5.4 ProductionOps
我们也在做部署合和任务编排,OpenMLDB 已经和 Airflow 和 Kubeflow 做了对接,有望在近期完成与 Airflow 的合作内容。监控一块也是非常易于使用的,OpenMLDB 已经和 Prometheus 和 Grafana 做了对接。
2.6 拥抱前沿新硬件技术:基于持久内存的优化
在前沿技术创新上我们也有产出成果,这个是去年被录用的一个 VLDB 的 paper,VLDB 是国际数据库界最顶尖的学术界的会议,在 paper 里面我们讲了两个事情:
- 一是把我们整个 OpenMLDB 的实现架构都去仔细进行了描述,所以大家想了解这个架构的话可以也去参照一下 paper;
- 二是讲了怎么去跟今天的前沿的硬件技术做结合,前沿的硬件技术就是 persistent memory,即持久内存,以前在学术界叫做非易失性内存。
持久内存是英特尔在大概 18、 19 年左右,发布了真正工业界第一款企业级的持久内存应用,奥腾持久内存。那么持久内存有什么优势呢?首先它成本低,它的单位价格是 Dram的 1/3~1/4 左右。当然它的性能也会比 Dram 稍微差 1/2 或 1/3 左右,但是比 SSD 还是会好一个量级的。其次容量大,一条持久内存可以最高到 512 GB,一台服务器上就很容易达到几个 TB。还有一个非常革命性的技术,就是可持久性的内存。现在的 Dram 掉电以后数据都没了,而 Persistent memory 掉电以后这个数据还在,这个是一个非常革命性的技术。
我们把持久内存跟 OpenMLDB 线上执行引擎已经结合了起来。前面提到了线上执行引擎的特点,首先它是一个基本上是基于纯内存的执行引擎,所以把它运行起来的成本有时候还是挺高的,如果场景特别大,为了满足内存需求,需要十几台机器,才能运行起来。同时它也有恢复时间慢的问题,因为它一旦掉电,需要从外部存储重新构建内存镜像,需要较长的时间。
于是我们就把持久内存跟 OpenMLDB 的线上引擎给结合起来,达到了三个非常好的效果:
- 恢复时间从本来的 6 个小时级别降到了 1 分钟。线上业务的意义其实是非常巨大的,线上业务比方说点餐系统,是不允许长时间掉线的,或者不允许某节点掉线以后影响业务的服务质量。结合之后,一分钟就能把这个业务重新拉起来,就不会影响到服务质量。
- 由于一些底层架构的修改,也改进了 20% 的长尾延迟。在 TP9999 的情况下,这就非常显著。
- 减少了总成本。因为内存单台机器内存扩大,使用的机器数量就变少了,原来用 16 台,现在只需要 6 台,成本一下子就降下来了。
2.7 OpenMLDB 典型案例 – 某银行事中反欺诈交易
接下来举一个简单的例子,在某银行的事中反欺诈交易场景,OpenMLDB 其实就是处于 FeatureOps 的位置,同时衔接了离线批处理和实时特征计算。然后在某银行的业务场景里,他们对响应的要求是非常高的,需要延迟在 20 ms 以内。可以看到,相比较于它原来传统规则的系统、客户自研的系统,OpenMLDB 提供了一个更好的效果,满足了他们发展的业务需求。
2.8 OpenMLDB 的历史
其实 OpenMLDB 是从第四范式成立第一天就开始做的产品。经过了 5 年的研发沉淀,OpenMLDB 跟随着商业产品经历了上百个项目的验证,累积了非常多的案例。
3 | 面向开源开放的 OpenMLDB 社区发展
3.1 OpenMLDB 发展历程
OpenMLDB 真正开源是去年的 6 月,我们其中的关键组件重新从商业平台中抽取出来,做了包装和优化形成了 OpenMLDB 今天的形态,并且对外开源,贡献给社区。我们开源后收获了不错的反馈,去年 9 月收获了第一个开源企业用户 Akulaku,今年我们也看到很多新团队在不断深入使用 OpenMLDB。
3.2 OpenMLDB 开源基本信息
这张图上是 OpenMLDB 的一些基本信息,大家可以简单了解。
3.3 感谢OpenMLDB的社区开发者
趁这个机会,我想再次感谢一下 OpenMLDB 的社区开发者。到目前为止,共有 51 位开发者加入社区。是大家不断地投入时间精力,OpenMLDB 才能被推动着不断往前发展。从 0.4.0 版本以来,又有 15 位新加入的开发者为社区做出了贡献。在这里,我想表示诚挚的感谢。如果大家对 OpenMLDB 感兴趣,也非常欢迎你作为新伙伴加入。
3.4 OpenMLDB v0.5.0 主要特性
最后想重点给大家介绍 OpenMLDB v0.5.0的新特性,预计在 4 月底发布。
- 预聚合技术应用到长窗口上。这个长窗口指的是时间窗口非常大,包含上百万条数据,针对这块数据做优化处理,我们会把预聚合技术应用进去,指数级提升长窗口聚合性能。
- 提供一个新的针对磁盘的存储引擎。如果你对价格敏感的话,可以选者这种 RocksDB 的外存储存。这样使得线上存储引擎可插拔以适配不同业务需求,既可以支持基于内存的高性能存储引擎,也可以支持基于外存的大容量低成本存储引擎,还可以支持基于持久内存的存储引擎以在性能和成本间保持平衡。
- UDF(用户自定义函数)支持,也会在加入到产品中,大幅提升易用性和适用性。
- 支持基于哈希的离散特征编码,以及编码后特征输出到CSV合LIBSVM格式,直接应用到模型训练合模型推理。
- 完善的监控能力,在企业级应用环境中大幅提升稳定性、可观测性、和可分析性。
- 上下游数据源生态整合,提供多种数据源 connectors,包括线上数据源的 Kafka, Pulsar connectors 等等。
3.5 OpenMLDB 后续重要特性
后续规划中 OpenMLDB 特性会朝着三个主要目标去走,三个主要目标就是降低使用门槛,降低使用成本,以及跟上下游生态的打通。
后续迭代都会不断地朝着这三个目标走。比方去规划一个 Cloud native 的 OpenMLDB 版本,包括自动特征工程,可能是今天用户还需要写 SQL,而在未来 SQL 可以根据数据去自动生成。以及还有基于异构硬件的优化,非结构化数据的支持,特征版本合血缘关系管理。大家对某个 feature 特别感兴趣或者特别需要的话,可以通过社区、Github 等渠道进行反馈,我们会去根据社区的反馈去看需求的优先级,也非常欢迎来自社区的共同开发。
3.6 欢迎加入 OpenMLDB 开源社区
上次 Meetup 时,我预告了官网的上线。如今 OpenMLDB 官网已经顺利推出,欢迎大家访问。或者也可以访问我们的 Github 页面,加入我们的微信交流群,又或是我的个人微信探讨交流。
今天的分享就到这里了,感谢大家。
接着,我会从我们最推荐的离线开发到线上服务的完整流程来讲解。
首先,我们会做离线的模式,把离线的数据导到 OpenMLDB,可以是软链的导入方式。此处的 Offline database 是一个虚拟概念化的存在,此时我们就可以做一个离线模型特征脚本的开发,在这个过程中和 Model training 可能也会有一个交互,要反复去调整。待到性能达到预期后,我们可以做一个动作,即 SQL deployment。把 SQL 部署上线,那么 OpenMLDB 的部署模式就会从 Offline 转至 Online。
在 Online 的首要工作是冷启动,导入需要的数据。我们特征脚本一般是面向时序数据的,所以会在窗口上做计算。假设我只需要最近三个月的数据,那我在上线的时间点需要在冷启动的时候把最近三个月的数据导入。而实际上,最近三个月的数据是不够的,因为现实世界的时间是不断推移的,所以需要不断更新这个 Online database。因此,OpenMLDB 需要接入在线的实时数据流。当然这里也提供 SDK,也支持通过 SDK 去实时地插入数据。
做完这一步已经万事具备,此时你可以使用 Preview 功能去看一下线上数据导入是否正确,但这是可选的。
做到这一步呢,整个 OpenMLD B就会转入一个叫做 Request mode,已经处在一个可以做实时计算的这个模式当中了。在我刚才讲述的例子中,小李搜索洗衣机关键字的信息进来后,系统就能结合计算逻辑和数据源坐等返回的特定结果了。这样一个 OpenMLDB 使用流程在我们的产品文档里有更进一步的描述。
2.4 OpenMLDB 产品特性
在介绍完 OpenMLDB 整体的架构和使用流程后,我会展开讲解 OpenMLDB 的产品特性。
2.4.1 OpenMLDB 产品特性一:线上线下一致性执行
之前讲过的一致性执行引擎,其实就是在内部去把 SQL 做了一个转换,转换成线上的执行计划和线下的执行计划,保证这两个值是从定义和执行逻辑上都是一致的。等于说线上线下一致性是在 OpenMLDB 的内部得到了一个天然的保障。
2.4.2 OpenMLDB 产品特性二:高性能在线特征计算引擎
第二个非常重要的特性,就是我们之前讲到的在线特征计算引擎。那我们怎么去保证在的计算的高性能呢?
第一,在线计算引擎加存储引擎都是我们自研的一个时序特征数据库,在内部它是一个双层的跳表结构,这有利于我们去高效地拿到窗口化的数据。
第二,我们做了一些预聚合的处理,部分特征可以提前去聚合计算,不需要等到查询时才准备。比方说需要过去一年内的商品点击量之前,我们可以把每个月的点击量先做好预聚合,当这个线上请求到来的时候,只需把每个月的点击量加起来再补充上最新的特征,就可以达到目的。 在这两种策略的加持下,我们和其他同样是 in memory 的数据库去做比较,可以看到在专门对这个特征工程做的窗口化查询需求下,OpenMLDB的性能会有非常大的优势。
2.4.3 OpenMLDB 产品特性三:面向特征计算的优化的离线计算引擎
第三个特性就是离线计算引擎的优化。
离线计算引擎是基于 Spark 的优化的版本,我们不是把原始的 Spark 直接拿来的,而是针对特征计优化做了一些措施,比如右边这个图,叫做多窗口的一些并行计算优化:SQL 定义了两个窗口,是在不同的 key 上面,一个是 group by name,一个是 group by age,这是两个时间窗口,在 Spark3.0 上翻译出来,这两个窗口会串行地去执行,有时候没法完全的非常好地利用集群的资源,所以我们在这里就改动了 Spark 的源代码,使其可以并行执行起来的,从而提升效率。这是其中的一个改动,其他的还有比如数据倾斜的优化,都是基于在 Spark 发行版里面去做的一些优化。左下角这个图显示了我们目前的版本和 Spark 原始版本的性能比对,可以看到,达到了一个非常显著的性能提升,特别是针对特征工程相关的操作。
2.4.4 OpenMLDB 产品特性四:针对特征工程的 SQL 扩展
特征四涉及到一个很常听到的疑问。因为我们是基于 SQL 去做这个特征工程,那大家很自然的会有一个问题——SQL 的表达能力是否足够?我们的回答是,原生的标准的 SQL 对某些比较复杂的特征处理逻辑上其实不是那么友好。但是,在 OpenMLDB 中,我们做了SQL语法和功能的扩展。
最典型例子是图片左边展示的 LAST JOIN,它能够在左表匹配到右表多行的时候只取最近的一条或者设定的某一条。这种场景在机器学习的这个训练里面有很多应用。
还有一个例子时 WINDOW UNION 的语法,从直观来理解,其实是做了一个跨表的窗口聚合操作。比方说这个左表(也是主表),左表的这个时间戳可以在右表的匹配的数据集上画一个时间窗口,在右表做一个聚合,然后把聚合结果拼到左表上。跨表聚合是 WINDOW UNION 所要达到最主要目的,当然它还有一些更复杂的用法,大家可以去参考我们的语法文档。
基于语法扩展和功能扩展,OpenMLDB 中 SQL 目前的表达能力是足够的。当然我们也看到社区用户其实可能有一些更高的要求,特别是针对一些这个计算函数,我们也在不断的扩展可能的新语法,包括新的 build in 函数,这块内容也非常欢迎大家来和我们一起做。
2.4.5 OpenMLDB 产品特性五:企业级特性支持
第五个非常重要的特性涉及到 OpenMLDB 的历史,它是从第四范式的商业产品转化而来,在开源之前已经应用于很多大规模的企业级应用里了,且在上百个场景里面都经过了实践。所以我们非常看重如何真正落到企业大规模企业级应用里的一些 feature,比方说高可用、扩缩融、平滑升级和企业级监控在如今的 OpenMLDB 中都是支持的。
最主要的一些企业级的 feature 已经在开源版本里列出来了,还有比如多租户、云原生,已经在我们的 roadmap 中,这一部分功能我们会不断地完善它,去更好的去为企业级应用做服务。
2.4.6 OpenMLDB 产品特性六:以SQL为核心的开发和管理体验
最后给大家分享一下这个 OpenMLDB 的一个非常重要的使用方式。我们认为它是一个数据库,最中心的一点就是 OpenMLDB 是以 SQL 为核心的全流程开发和管理体验,在 CLI 里面去做离线特征方案的开发,开发完离线特征计算,可以一步切换到这个SQL的方案上线,直接用一个 DEPLOY 命令把离线的方案切换到线上,就可以直接进入 serving 的服务。然后按步骤操作,就可以直接做线上请求,进行实时特征计算了。
通过一个 API 做线上请求,或者通过 Python,Java 的 SDK,都可以直接去跟 serving 的服务器做通信和线上请求。可以看到,基于 SQL 和基于 CLI 的开发非常低门槛以及方便。
2.5 OpenMLDB 上下游生态
将 OpenMLDB 投射到 MLOps 生命周期中,可以看到 OpenMLDB 占据着其中 FeatureOps 的位置,主要是做特征计算。
2.5.1 内部框架
先解析 OpenMLDB 内部框架,我们有这个 Online 引擎和 Offline 引擎。
Online 引擎又可以被细分为存储和执行。在其中的 SQL 执行层面,因为需要储存最新的实时数据的,所以我们会有一个 Storage engine,在默认情况下会有 in memory storage(build in)。它其实是非常高效的、专门面向时序数据库去优化的一个内存数据库。当然我们也可以数据存在磁盘上,把 RocksDB 插进来。所以 OpenMLDB v 0.5.0的版本会同时提供两种不同的 Storage Engine。如果你对性能需求特别高,可以选择 in memory storage engine。如果你对性能不太敏感但是重视成本,那么可以使用基于磁盘的存储(RocksDB)。
Online SQL Engine 这一块是我们自研的,用于高性能进行 SQL 计算。Offline 板块是基于Spark去做了合理的修改,称作这个 OpenMLDB 的 Spark 发行版,未来我们可能也会有其他的一些扩展。
2.5.2 Data sources
左边的是 DataOps,介绍了数据是如何获取的。比方说 Online data sources 板块,我们发布了 OpenMLDB Pulsar connector, 已经可以接入 Pulsar 的数据了。这个月发布的版本中,我们应该还会把 Kafka 的这个 connector 也同时发布出来,更加有利于这个大家数据的接入。在 Offline data sources 这一块呢,OpenMLDB 支持直接接入 HDFS、S3 数据 ,未来我们也会支持更多的数据源。
2.5.3 ModelOps
往右的 ModelOps 这边,其实是一些下游模型。下游模型通过一些标准输出格式,就能直接接入了。这个月会发布的新版本中,我们会把这个模型特征的功能整合进来,让它可以输出这个标准的 LIBSVM 或者 CSV 的格式,可以直接给到 Pytorch 等使用。
2.5.4 ProductionOps
我们也在做部署合和任务编排,OpenMLDB 已经和 Airflow 和 Kubeflow 做了对接,有望在近期完成与 Airflow 的合作内容。监控一块也是非常易于使用的,OpenMLDB 已经和 Prometheus 和 Grafana 做了对接。
2.6 拥抱前沿新硬件技术:基于持久内存的优化
在前沿技术创新上我们也有产出成果,这个是去年被录用的一个 VLDB 的 paper,VLDB 是国际数据库界最顶尖的学术界的会议,在 paper 里面我们讲了两个事情:
- 一是把我们整个 OpenMLDB 的实现架构都去仔细进行了描述,所以大家想了解这个架构的话可以也去参照一下 paper;
- 二是讲了怎么去跟今天的前沿的硬件技术做结合,前沿的硬件技术就是 persistent memory,即持久内存,以前在学术界叫做非易失性内存。
持久内存是英特尔在大概 18、 19 年左右,发布了真正工业界第一款企业级的持久内存应用,奥腾持久内存。那么持久内存有什么优势呢?首先它成本低,它的单位价格是 Dram的 1/3~1/4 左右。当然它的性能也会比 Dram 稍微差 1/2 或 1/3 左右,但是比 SSD 还是会好一个量级的。其次容量大,一条持久内存可以最高到 512 GB,一台服务器上就很容易达到几个 TB。还有一个非常革命性的技术,就是可持久性的内存。现在的 Dram 掉电以后数据都没了,而 Persistent memory 掉电以后这个数据还在,这个是一个非常革命性的技术。
我们把持久内存跟 OpenMLDB 线上执行引擎已经结合了起来。前面提到了线上执行引擎的特点,首先它是一个基本上是基于纯内存的执行引擎,所以把它运行起来的成本有时候还是挺高的,如果场景特别大,为了满足内存需求,需要十几台机器,才能运行起来。同时它也有恢复时间慢的问题,因为它一旦掉电,需要从外部存储重新构建内存镜像,需要较长的时间。
于是我们就把持久内存跟 OpenMLDB 的线上引擎给结合起来,达到了三个非常好的效果:
- 恢复时间从本来的 6 个小时级别降到了 1 分钟。线上业务的意义其实是非常巨大的,线上业务比方说点餐系统,是不允许长时间掉线的,或者不允许某节点掉线以后影响业务的服务质量。结合之后,一分钟就能把这个业务重新拉起来,就不会影响到服务质量。
- 由于一些底层架构的修改,也改进了 20% 的长尾延迟。在 TP9999 的情况下,这就非常显著。
- 减少了总成本。因为内存单台机器内存扩大,使用的机器数量就变少了,原来用 16 台,现在只需要 6 台,成本一下子就降下来了。
2.7 OpenMLDB 典型案例 – 某银行事中反欺诈交易
接下来举一个简单的例子,在某银行的事中反欺诈交易场景,OpenMLDB 其实就是处于 FeatureOps 的位置,同时衔接了离线批处理和实时特征计算。然后在某银行的业务场景里,他们对响应的要求是非常高的,需要延迟在 20 ms 以内。可以看到,相比较于它原来传统规则的系统、客户自研的系统,OpenMLDB 提供了一个更好的效果,满足了他们发展的业务需求。
2.8 OpenMLDB 的历史
其实 OpenMLDB 是从第四范式成立第一天就开始做的产品。经过了 5 年的研发沉淀,OpenMLDB 跟随着商业产品经历了上百个项目的验证,累积了非常多的案例。
3 | 面向开源开放的 OpenMLDB 社区发展
3.1 OpenMLDB 发展历程
OpenMLDB 真正开源是去年的 6 月,我们其中的关键组件重新从商业平台中抽取出来,做了包装和优化形成了 OpenMLDB 今天的形态,并且对外开源,贡献给社区。我们开源后收获了不错的反馈,去年 9 月收获了第一个开源企业用户 Akulaku,今年我们也看到很多新团队在不断深入使用 OpenMLDB。
3.2 OpenMLDB 开源基本信息
这张图上是 OpenMLDB 的一些基本信息,大家可以简单了解。
3.3 感谢OpenMLDB的社区开发者
趁这个机会,我想再次感谢一下 OpenMLDB 的社区开发者。到目前为止,共有 51 位开发者加入社区。是大家不断地投入时间精力,OpenMLDB 才能被推动着不断往前发展。从 0.4.0 版本以来,又有 15 位新加入的开发者为社区做出了贡献。在这里,我想表示诚挚的感谢。如果大家对 OpenMLDB 感兴趣,也非常欢迎你作为新伙伴加入。
3.4 OpenMLDB v0.5.0 主要特性
最后想重点给大家介绍 OpenMLDB v0.5.0的新特性,预计在 4 月底发布。
- 预聚合技术应用到长窗口上。这个长窗口指的是时间窗口非常大,包含上百万条数据,针对这块数据做优化处理,我们会把预聚合技术应用进去,指数级提升长窗口聚合性能。
- 提供一个新的针对磁盘的存储引擎。如果你对价格敏感的话,可以选者这种 RocksDB 的外存储存。这样使得线上存储引擎可插拔以适配不同业务需求,既可以支持基于内存的高性能存储引擎,也可以支持基于外存的大容量低成本存储引擎,还可以支持基于持久内存的存储引擎以在性能和成本间保持平衡。
- UDF(用户自定义函数)支持,也会在加入到产品中,大幅提升易用性和适用性。
- 支持基于哈希的离散特征编码,以及编码后特征输出到CSV合LIBSVM格式,直接应用到模型训练合模型推理。
- 完善的监控能力,在企业级应用环境中大幅提升稳定性、可观测性、和可分析性。
- 上下游数据源生态整合,提供多种数据源 connectors,包括线上数据源的 Kafka, Pulsar connectors 等等。
3.5 OpenMLDB 后续重要特性
后续规划中 OpenMLDB 特性会朝着三个主要目标去走,三个主要目标就是降低使用门槛,降低使用成本,以及跟上下游生态的打通。
后续迭代都会不断地朝着这三个目标走。比方去规划一个 Cloud native 的 OpenMLDB 版本,包括自动特征工程,可能是今天用户还需要写 SQL,而在未来 SQL 可以根据数据去自动生成。以及还有基于异构硬件的优化,非结构化数据的支持,特征版本合血缘关系管理。大家对某个 feature 特别感兴趣或者特别需要的话,可以通过社区、Github 等渠道进行反馈,我们会去根据社区的反馈去看需求的优先级,也非常欢迎来自社区的共同开发。
3.6 欢迎加入 OpenMLDB 开源社区
上次 Meetup 时,我预告了官网的上线。如今 OpenMLDB 官网已经顺利推出,欢迎大家访问。或者也可以访问我们的 Github 页面,加入我们的微信交流群,又或是我的个人微信探讨交流。
今天的分享就到这里了,感谢大家。
之前讲过的一致性执行引擎,其实就是在内部去把 SQL 做了一个转换,转换成线上的执行计划和线下的执行计划,保证这两个值是从定义和执行逻辑上都是一致的。等于说线上线下一致性是在 OpenMLDB 的内部得到了一个天然的保障。
2.4.2 OpenMLDB 产品特性二:高性能在线特征计算引擎
第二个非常重要的特性,就是我们之前讲到的在线特征计算引擎。那我们怎么去保证在的计算的高性能呢?
第一,在线计算引擎加存储引擎都是我们自研的一个时序特征数据库,在内部它是一个双层的跳表结构,这有利于我们去高效地拿到窗口化的数据。
第二,我们做了一些预聚合的处理,部分特征可以提前去聚合计算,不需要等到查询时才准备。比方说需要过去一年内的商品点击量之前,我们可以把每个月的点击量先做好预聚合,当这个线上请求到来的时候,只需把每个月的点击量加起来再补充上最新的特征,就可以达到目的。 在这两种策略的加持下,我们和其他同样是 in memory 的数据库去做比较,可以看到在专门对这个特征工程做的窗口化查询需求下,OpenMLDB的性能会有非常大的优势。
2.4.3 OpenMLDB 产品特性三:面向特征计算的优化的离线计算引擎
第三个特性就是离线计算引擎的优化。
离线计算引擎是基于 Spark 的优化的版本,我们不是把原始的 Spark 直接拿来的,而是针对特征计优化做了一些措施,比如右边这个图,叫做多窗口的一些并行计算优化:SQL 定义了两个窗口,是在不同的 key 上面,一个是 group by name,一个是 group by age,这是两个时间窗口,在 Spark3.0 上翻译出来,这两个窗口会串行地去执行,有时候没法完全的非常好地利用集群的资源,所以我们在这里就改动了 Spark 的源代码,使其可以并行执行起来的,从而提升效率。这是其中的一个改动,其他的还有比如数据倾斜的优化,都是基于在 Spark 发行版里面去做的一些优化。左下角这个图显示了我们目前的版本和 Spark 原始版本的性能比对,可以看到,达到了一个非常显著的性能提升,特别是针对特征工程相关的操作。
2.4.4 OpenMLDB 产品特性四:针对特征工程的 SQL 扩展
特征四涉及到一个很常听到的疑问。因为我们是基于 SQL 去做这个特征工程,那大家很自然的会有一个问题——SQL 的表达能力是否足够?我们的回答是,原生的标准的 SQL 对某些比较复杂的特征处理逻辑上其实不是那么友好。但是,在 OpenMLDB 中,我们做了SQL语法和功能的扩展。
最典型例子是图片左边展示的 LAST JOIN,它能够在左表匹配到右表多行的时候只取最近的一条或者设定的某一条。这种场景在机器学习的这个训练里面有很多应用。
还有一个例子时 WINDOW UNION 的语法,从直观来理解,其实是做了一个跨表的窗口聚合操作。比方说这个左表(也是主表),左表的这个时间戳可以在右表的匹配的数据集上画一个时间窗口,在右表做一个聚合,然后把聚合结果拼到左表上。跨表聚合是 WINDOW UNION 所要达到最主要目的,当然它还有一些更复杂的用法,大家可以去参考我们的语法文档。
基于语法扩展和功能扩展,OpenMLDB 中 SQL 目前的表达能力是足够的。当然我们也看到社区用户其实可能有一些更高的要求,特别是针对一些这个计算函数,我们也在不断的扩展可能的新语法,包括新的 build in 函数,这块内容也非常欢迎大家来和我们一起做。
2.4.5 OpenMLDB 产品特性五:企业级特性支持
第五个非常重要的特性涉及到 OpenMLDB 的历史,它是从第四范式的商业产品转化而来,在开源之前已经应用于很多大规模的企业级应用里了,且在上百个场景里面都经过了实践。所以我们非常看重如何真正落到企业大规模企业级应用里的一些 feature,比方说高可用、扩缩融、平滑升级和企业级监控在如今的 OpenMLDB 中都是支持的。
最主要的一些企业级的 feature 已经在开源版本里列出来了,还有比如多租户、云原生,已经在我们的 roadmap 中,这一部分功能我们会不断地完善它,去更好的去为企业级应用做服务。
2.4.6 OpenMLDB 产品特性六:以SQL为核心的开发和管理体验
最后给大家分享一下这个 OpenMLDB 的一个非常重要的使用方式。我们认为它是一个数据库,最中心的一点就是 OpenMLDB 是以 SQL 为核心的全流程开发和管理体验,在 CLI 里面去做离线特征方案的开发,开发完离线特征计算,可以一步切换到这个SQL的方案上线,直接用一个 DEPLOY 命令把离线的方案切换到线上,就可以直接进入 serving 的服务。然后按步骤操作,就可以直接做线上请求,进行实时特征计算了。
通过一个 API 做线上请求,或者通过 Python,Java 的 SDK,都可以直接去跟 serving 的服务器做通信和线上请求。可以看到,基于 SQL 和基于 CLI 的开发非常低门槛以及方便。
2.5 OpenMLDB 上下游生态
将 OpenMLDB 投射到 MLOps 生命周期中,可以看到 OpenMLDB 占据着其中 FeatureOps 的位置,主要是做特征计算。
2.5.1 内部框架
先解析 OpenMLDB 内部框架,我们有这个 Online 引擎和 Offline 引擎。
Online 引擎又可以被细分为存储和执行。在其中的 SQL 执行层面,因为需要储存最新的实时数据的,所以我们会有一个 Storage engine,在默认情况下会有 in memory storage(build in)。它其实是非常高效的、专门面向时序数据库去优化的一个内存数据库。当然我们也可以数据存在磁盘上,把 RocksDB 插进来。所以 OpenMLDB v 0.5.0的版本会同时提供两种不同的 Storage Engine。如果你对性能需求特别高,可以选择 in memory storage engine。如果你对性能不太敏感但是重视成本,那么可以使用基于磁盘的存储(RocksDB)。
Online SQL Engine 这一块是我们自研的,用于高性能进行 SQL 计算。Offline 板块是基于Spark去做了合理的修改,称作这个 OpenMLDB 的 Spark 发行版,未来我们可能也会有其他的一些扩展。
2.5.2 Data sources
左边的是 DataOps,介绍了数据是如何获取的。比方说 Online data sources 板块,我们发布了 OpenMLDB Pulsar connector, 已经可以接入 Pulsar 的数据了。这个月发布的版本中,我们应该还会把 Kafka 的这个 connector 也同时发布出来,更加有利于这个大家数据的接入。在 Offline data sources 这一块呢,OpenMLDB 支持直接接入 HDFS、S3 数据 ,未来我们也会支持更多的数据源。
2.5.3 ModelOps
往右的 ModelOps 这边,其实是一些下游模型。下游模型通过一些标准输出格式,就能直接接入了。这个月会发布的新版本中,我们会把这个模型特征的功能整合进来,让它可以输出这个标准的 LIBSVM 或者 CSV 的格式,可以直接给到 Pytorch 等使用。
2.5.4 ProductionOps
我们也在做部署合和任务编排,OpenMLDB 已经和 Airflow 和 Kubeflow 做了对接,有望在近期完成与 Airflow 的合作内容。监控一块也是非常易于使用的,OpenMLDB 已经和 Prometheus 和 Grafana 做了对接。
2.6 拥抱前沿新硬件技术:基于持久内存的优化
在前沿技术创新上我们也有产出成果,这个是去年被录用的一个 VLDB 的 paper,VLDB 是国际数据库界最顶尖的学术界的会议,在 paper 里面我们讲了两个事情:
- 一是把我们整个 OpenMLDB 的实现架构都去仔细进行了描述,所以大家想了解这个架构的话可以也去参照一下 paper;
- 二是讲了怎么去跟今天的前沿的硬件技术做结合,前沿的硬件技术就是 persistent memory,即持久内存,以前在学术界叫做非易失性内存。
持久内存是英特尔在大概 18、 19 年左右,发布了真正工业界第一款企业级的持久内存应用,奥腾持久内存。那么持久内存有什么优势呢?首先它成本低,它的单位价格是 Dram的 1/3~1/4 左右。当然它的性能也会比 Dram 稍微差 1/2 或 1/3 左右,但是比 SSD 还是会好一个量级的。其次容量大,一条持久内存可以最高到 512 GB,一台服务器上就很容易达到几个 TB。还有一个非常革命性的技术,就是可持久性的内存。现在的 Dram 掉电以后数据都没了,而 Persistent memory 掉电以后这个数据还在,这个是一个非常革命性的技术。
我们把持久内存跟 OpenMLDB 线上执行引擎已经结合了起来。前面提到了线上执行引擎的特点,首先它是一个基本上是基于纯内存的执行引擎,所以把它运行起来的成本有时候还是挺高的,如果场景特别大,为了满足内存需求,需要十几台机器,才能运行起来。同时它也有恢复时间慢的问题,因为它一旦掉电,需要从外部存储重新构建内存镜像,需要较长的时间。
于是我们就把持久内存跟 OpenMLDB 的线上引擎给结合起来,达到了三个非常好的效果:
- 恢复时间从本来的 6 个小时级别降到了 1 分钟。线上业务的意义其实是非常巨大的,线上业务比方说点餐系统,是不允许长时间掉线的,或者不允许某节点掉线以后影响业务的服务质量。结合之后,一分钟就能把这个业务重新拉起来,就不会影响到服务质量。
- 由于一些底层架构的修改,也改进了 20% 的长尾延迟。在 TP9999 的情况下,这就非常显著。
- 减少了总成本。因为内存单台机器内存扩大,使用的机器数量就变少了,原来用 16 台,现在只需要 6 台,成本一下子就降下来了。
2.7 OpenMLDB 典型案例 – 某银行事中反欺诈交易
接下来举一个简单的例子,在某银行的事中反欺诈交易场景,OpenMLDB 其实就是处于 FeatureOps 的位置,同时衔接了离线批处理和实时特征计算。然后在某银行的业务场景里,他们对响应的要求是非常高的,需要延迟在 20 ms 以内。可以看到,相比较于它原来传统规则的系统、客户自研的系统,OpenMLDB 提供了一个更好的效果,满足了他们发展的业务需求。
2.8 OpenMLDB 的历史
其实 OpenMLDB 是从第四范式成立第一天就开始做的产品。经过了 5 年的研发沉淀,OpenMLDB 跟随着商业产品经历了上百个项目的验证,累积了非常多的案例。
3 | 面向开源开放的 OpenMLDB 社区发展
3.1 OpenMLDB 发展历程
OpenMLDB 真正开源是去年的 6 月,我们其中的关键组件重新从商业平台中抽取出来,做了包装和优化形成了 OpenMLDB 今天的形态,并且对外开源,贡献给社区。我们开源后收获了不错的反馈,去年 9 月收获了第一个开源企业用户 Akulaku,今年我们也看到很多新团队在不断深入使用 OpenMLDB。
3.2 OpenMLDB 开源基本信息
这张图上是 OpenMLDB 的一些基本信息,大家可以简单了解。
3.3 感谢OpenMLDB的社区开发者
趁这个机会,我想再次感谢一下 OpenMLDB 的社区开发者。到目前为止,共有 51 位开发者加入社区。是大家不断地投入时间精力,OpenMLDB 才能被推动着不断往前发展。从 0.4.0 版本以来,又有 15 位新加入的开发者为社区做出了贡献。在这里,我想表示诚挚的感谢。如果大家对 OpenMLDB 感兴趣,也非常欢迎你作为新伙伴加入。
3.4 OpenMLDB v0.5.0 主要特性
最后想重点给大家介绍 OpenMLDB v0.5.0的新特性,预计在 4 月底发布。
- 预聚合技术应用到长窗口上。这个长窗口指的是时间窗口非常大,包含上百万条数据,针对这块数据做优化处理,我们会把预聚合技术应用进去,指数级提升长窗口聚合性能。
- 提供一个新的针对磁盘的存储引擎。如果你对价格敏感的话,可以选者这种 RocksDB 的外存储存。这样使得线上存储引擎可插拔以适配不同业务需求,既可以支持基于内存的高性能存储引擎,也可以支持基于外存的大容量低成本存储引擎,还可以支持基于持久内存的存储引擎以在性能和成本间保持平衡。
- UDF(用户自定义函数)支持,也会在加入到产品中,大幅提升易用性和适用性。
- 支持基于哈希的离散特征编码,以及编码后特征输出到CSV合LIBSVM格式,直接应用到模型训练合模型推理。
- 完善的监控能力,在企业级应用环境中大幅提升稳定性、可观测性、和可分析性。
- 上下游数据源生态整合,提供多种数据源 connectors,包括线上数据源的 Kafka, Pulsar connectors 等等。
3.5 OpenMLDB 后续重要特性
后续规划中 OpenMLDB 特性会朝着三个主要目标去走,三个主要目标就是降低使用门槛,降低使用成本,以及跟上下游生态的打通。
后续迭代都会不断地朝着这三个目标走。比方去规划一个 Cloud native 的 OpenMLDB 版本,包括自动特征工程,可能是今天用户还需要写 SQL,而在未来 SQL 可以根据数据去自动生成。以及还有基于异构硬件的优化,非结构化数据的支持,特征版本合血缘关系管理。大家对某个 feature 特别感兴趣或者特别需要的话,可以通过社区、Github 等渠道进行反馈,我们会去根据社区的反馈去看需求的优先级,也非常欢迎来自社区的共同开发。
3.6 欢迎加入 OpenMLDB 开源社区
上次 Meetup 时,我预告了官网的上线。如今 OpenMLDB 官网已经顺利推出,欢迎大家访问。或者也可以访问我们的 Github 页面,加入我们的微信交流群,又或是我的个人微信探讨交流。
今天的分享就到这里了,感谢大家。
第三个特性就是离线计算引擎的优化。
离线计算引擎是基于 Spark 的优化的版本,我们不是把原始的 Spark 直接拿来的,而是针对特征计优化做了一些措施,比如右边这个图,叫做多窗口的一些并行计算优化:SQL 定义了两个窗口,是在不同的 key 上面,一个是 group by name,一个是 group by age,这是两个时间窗口,在 Spark3.0 上翻译出来,这两个窗口会串行地去执行,有时候没法完全的非常好地利用集群的资源,所以我们在这里就改动了 Spark 的源代码,使其可以并行执行起来的,从而提升效率。这是其中的一个改动,其他的还有比如数据倾斜的优化,都是基于在 Spark 发行版里面去做的一些优化。左下角这个图显示了我们目前的版本和 Spark 原始版本的性能比对,可以看到,达到了一个非常显著的性能提升,特别是针对特征工程相关的操作。
2.4.4 OpenMLDB 产品特性四:针对特征工程的 SQL 扩展
特征四涉及到一个很常听到的疑问。因为我们是基于 SQL 去做这个特征工程,那大家很自然的会有一个问题——SQL 的表达能力是否足够?我们的回答是,原生的标准的 SQL 对某些比较复杂的特征处理逻辑上其实不是那么友好。但是,在 OpenMLDB 中,我们做了SQL语法和功能的扩展。
最典型例子是图片左边展示的 LAST JOIN,它能够在左表匹配到右表多行的时候只取最近的一条或者设定的某一条。这种场景在机器学习的这个训练里面有很多应用。
还有一个例子时 WINDOW UNION 的语法,从直观来理解,其实是做了一个跨表的窗口聚合操作。比方说这个左表(也是主表),左表的这个时间戳可以在右表的匹配的数据集上画一个时间窗口,在右表做一个聚合,然后把聚合结果拼到左表上。跨表聚合是 WINDOW UNION 所要达到最主要目的,当然它还有一些更复杂的用法,大家可以去参考我们的语法文档。
基于语法扩展和功能扩展,OpenMLDB 中 SQL 目前的表达能力是足够的。当然我们也看到社区用户其实可能有一些更高的要求,特别是针对一些这个计算函数,我们也在不断的扩展可能的新语法,包括新的 build in 函数,这块内容也非常欢迎大家来和我们一起做。
2.4.5 OpenMLDB 产品特性五:企业级特性支持
第五个非常重要的特性涉及到 OpenMLDB 的历史,它是从第四范式的商业产品转化而来,在开源之前已经应用于很多大规模的企业级应用里了,且在上百个场景里面都经过了实践。所以我们非常看重如何真正落到企业大规模企业级应用里的一些 feature,比方说高可用、扩缩融、平滑升级和企业级监控在如今的 OpenMLDB 中都是支持的。
最主要的一些企业级的 feature 已经在开源版本里列出来了,还有比如多租户、云原生,已经在我们的 roadmap 中,这一部分功能我们会不断地完善它,去更好的去为企业级应用做服务。
2.4.6 OpenMLDB 产品特性六:以SQL为核心的开发和管理体验
最后给大家分享一下这个 OpenMLDB 的一个非常重要的使用方式。我们认为它是一个数据库,最中心的一点就是 OpenMLDB 是以 SQL 为核心的全流程开发和管理体验,在 CLI 里面去做离线特征方案的开发,开发完离线特征计算,可以一步切换到这个SQL的方案上线,直接用一个 DEPLOY 命令把离线的方案切换到线上,就可以直接进入 serving 的服务。然后按步骤操作,就可以直接做线上请求,进行实时特征计算了。
通过一个 API 做线上请求,或者通过 Python,Java 的 SDK,都可以直接去跟 serving 的服务器做通信和线上请求。可以看到,基于 SQL 和基于 CLI 的开发非常低门槛以及方便。
2.5 OpenMLDB 上下游生态
将 OpenMLDB 投射到 MLOps 生命周期中,可以看到 OpenMLDB 占据着其中 FeatureOps 的位置,主要是做特征计算。
2.5.1 内部框架
先解析 OpenMLDB 内部框架,我们有这个 Online 引擎和 Offline 引擎。
Online 引擎又可以被细分为存储和执行。在其中的 SQL 执行层面,因为需要储存最新的实时数据的,所以我们会有一个 Storage engine,在默认情况下会有 in memory storage(build in)。它其实是非常高效的、专门面向时序数据库去优化的一个内存数据库。当然我们也可以数据存在磁盘上,把 RocksDB 插进来。所以 OpenMLDB v 0.5.0的版本会同时提供两种不同的 Storage Engine。如果你对性能需求特别高,可以选择 in memory storage engine。如果你对性能不太敏感但是重视成本,那么可以使用基于磁盘的存储(RocksDB)。
Online SQL Engine 这一块是我们自研的,用于高性能进行 SQL 计算。Offline 板块是基于Spark去做了合理的修改,称作这个 OpenMLDB 的 Spark 发行版,未来我们可能也会有其他的一些扩展。
2.5.2 Data sources
左边的是 DataOps,介绍了数据是如何获取的。比方说 Online data sources 板块,我们发布了 OpenMLDB Pulsar connector, 已经可以接入 Pulsar 的数据了。这个月发布的版本中,我们应该还会把 Kafka 的这个 connector 也同时发布出来,更加有利于这个大家数据的接入。在 Offline data sources 这一块呢,OpenMLDB 支持直接接入 HDFS、S3 数据 ,未来我们也会支持更多的数据源。
2.5.3 ModelOps
往右的 ModelOps 这边,其实是一些下游模型。下游模型通过一些标准输出格式,就能直接接入了。这个月会发布的新版本中,我们会把这个模型特征的功能整合进来,让它可以输出这个标准的 LIBSVM 或者 CSV 的格式,可以直接给到 Pytorch 等使用。
2.5.4 ProductionOps
我们也在做部署合和任务编排,OpenMLDB 已经和 Airflow 和 Kubeflow 做了对接,有望在近期完成与 Airflow 的合作内容。监控一块也是非常易于使用的,OpenMLDB 已经和 Prometheus 和 Grafana 做了对接。
2.6 拥抱前沿新硬件技术:基于持久内存的优化
在前沿技术创新上我们也有产出成果,这个是去年被录用的一个 VLDB 的 paper,VLDB 是国际数据库界最顶尖的学术界的会议,在 paper 里面我们讲了两个事情:
- 一是把我们整个 OpenMLDB 的实现架构都去仔细进行了描述,所以大家想了解这个架构的话可以也去参照一下 paper;
- 二是讲了怎么去跟今天的前沿的硬件技术做结合,前沿的硬件技术就是 persistent memory,即持久内存,以前在学术界叫做非易失性内存。
持久内存是英特尔在大概 18、 19 年左右,发布了真正工业界第一款企业级的持久内存应用,奥腾持久内存。那么持久内存有什么优势呢?首先它成本低,它的单位价格是 Dram的 1/3~1/4 左右。当然它的性能也会比 Dram 稍微差 1/2 或 1/3 左右,但是比 SSD 还是会好一个量级的。其次容量大,一条持久内存可以最高到 512 GB,一台服务器上就很容易达到几个 TB。还有一个非常革命性的技术,就是可持久性的内存。现在的 Dram 掉电以后数据都没了,而 Persistent memory 掉电以后这个数据还在,这个是一个非常革命性的技术。
我们把持久内存跟 OpenMLDB 线上执行引擎已经结合了起来。前面提到了线上执行引擎的特点,首先它是一个基本上是基于纯内存的执行引擎,所以把它运行起来的成本有时候还是挺高的,如果场景特别大,为了满足内存需求,需要十几台机器,才能运行起来。同时它也有恢复时间慢的问题,因为它一旦掉电,需要从外部存储重新构建内存镜像,需要较长的时间。
于是我们就把持久内存跟 OpenMLDB 的线上引擎给结合起来,达到了三个非常好的效果:
- 恢复时间从本来的 6 个小时级别降到了 1 分钟。线上业务的意义其实是非常巨大的,线上业务比方说点餐系统,是不允许长时间掉线的,或者不允许某节点掉线以后影响业务的服务质量。结合之后,一分钟就能把这个业务重新拉起来,就不会影响到服务质量。
- 由于一些底层架构的修改,也改进了 20% 的长尾延迟。在 TP9999 的情况下,这就非常显著。
- 减少了总成本。因为内存单台机器内存扩大,使用的机器数量就变少了,原来用 16 台,现在只需要 6 台,成本一下子就降下来了。
2.7 OpenMLDB 典型案例 – 某银行事中反欺诈交易
接下来举一个简单的例子,在某银行的事中反欺诈交易场景,OpenMLDB 其实就是处于 FeatureOps 的位置,同时衔接了离线批处理和实时特征计算。然后在某银行的业务场景里,他们对响应的要求是非常高的,需要延迟在 20 ms 以内。可以看到,相比较于它原来传统规则的系统、客户自研的系统,OpenMLDB 提供了一个更好的效果,满足了他们发展的业务需求。
2.8 OpenMLDB 的历史
其实 OpenMLDB 是从第四范式成立第一天就开始做的产品。经过了 5 年的研发沉淀,OpenMLDB 跟随着商业产品经历了上百个项目的验证,累积了非常多的案例。
3 | 面向开源开放的 OpenMLDB 社区发展
3.1 OpenMLDB 发展历程
OpenMLDB 真正开源是去年的 6 月,我们其中的关键组件重新从商业平台中抽取出来,做了包装和优化形成了 OpenMLDB 今天的形态,并且对外开源,贡献给社区。我们开源后收获了不错的反馈,去年 9 月收获了第一个开源企业用户 Akulaku,今年我们也看到很多新团队在不断深入使用 OpenMLDB。
3.2 OpenMLDB 开源基本信息
这张图上是 OpenMLDB 的一些基本信息,大家可以简单了解。
3.3 感谢OpenMLDB的社区开发者
趁这个机会,我想再次感谢一下 OpenMLDB 的社区开发者。到目前为止,共有 51 位开发者加入社区。是大家不断地投入时间精力,OpenMLDB 才能被推动着不断往前发展。从 0.4.0 版本以来,又有 15 位新加入的开发者为社区做出了贡献。在这里,我想表示诚挚的感谢。如果大家对 OpenMLDB 感兴趣,也非常欢迎你作为新伙伴加入。
3.4 OpenMLDB v0.5.0 主要特性
最后想重点给大家介绍 OpenMLDB v0.5.0的新特性,预计在 4 月底发布。
- 预聚合技术应用到长窗口上。这个长窗口指的是时间窗口非常大,包含上百万条数据,针对这块数据做优化处理,我们会把预聚合技术应用进去,指数级提升长窗口聚合性能。
- 提供一个新的针对磁盘的存储引擎。如果你对价格敏感的话,可以选者这种 RocksDB 的外存储存。这样使得线上存储引擎可插拔以适配不同业务需求,既可以支持基于内存的高性能存储引擎,也可以支持基于外存的大容量低成本存储引擎,还可以支持基于持久内存的存储引擎以在性能和成本间保持平衡。
- UDF(用户自定义函数)支持,也会在加入到产品中,大幅提升易用性和适用性。
- 支持基于哈希的离散特征编码,以及编码后特征输出到CSV合LIBSVM格式,直接应用到模型训练合模型推理。
- 完善的监控能力,在企业级应用环境中大幅提升稳定性、可观测性、和可分析性。
- 上下游数据源生态整合,提供多种数据源 connectors,包括线上数据源的 Kafka, Pulsar connectors 等等。
3.5 OpenMLDB 后续重要特性
后续规划中 OpenMLDB 特性会朝着三个主要目标去走,三个主要目标就是降低使用门槛,降低使用成本,以及跟上下游生态的打通。
后续迭代都会不断地朝着这三个目标走。比方去规划一个 Cloud native 的 OpenMLDB 版本,包括自动特征工程,可能是今天用户还需要写 SQL,而在未来 SQL 可以根据数据去自动生成。以及还有基于异构硬件的优化,非结构化数据的支持,特征版本合血缘关系管理。大家对某个 feature 特别感兴趣或者特别需要的话,可以通过社区、Github 等渠道进行反馈,我们会去根据社区的反馈去看需求的优先级,也非常欢迎来自社区的共同开发。
3.6 欢迎加入 OpenMLDB 开源社区
上次 Meetup 时,我预告了官网的上线。如今 OpenMLDB 官网已经顺利推出,欢迎大家访问。或者也可以访问我们的 Github 页面,加入我们的微信交流群,又或是我的个人微信探讨交流。
今天的分享就到这里了,感谢大家。
第五个非常重要的特性涉及到 OpenMLDB 的历史,它是从第四范式的商业产品转化而来,在开源之前已经应用于很多大规模的企业级应用里了,且在上百个场景里面都经过了实践。所以我们非常看重如何真正落到企业大规模企业级应用里的一些 feature,比方说高可用、扩缩融、平滑升级和企业级监控在如今的 OpenMLDB 中都是支持的。
最主要的一些企业级的 feature 已经在开源版本里列出来了,还有比如多租户、云原生,已经在我们的 roadmap 中,这一部分功能我们会不断地完善它,去更好的去为企业级应用做服务。
2.4.6 OpenMLDB 产品特性六:以SQL为核心的开发和管理体验
最后给大家分享一下这个 OpenMLDB 的一个非常重要的使用方式。我们认为它是一个数据库,最中心的一点就是 OpenMLDB 是以 SQL 为核心的全流程开发和管理体验,在 CLI 里面去做离线特征方案的开发,开发完离线特征计算,可以一步切换到这个SQL的方案上线,直接用一个 DEPLOY 命令把离线的方案切换到线上,就可以直接进入 serving 的服务。然后按步骤操作,就可以直接做线上请求,进行实时特征计算了。
通过一个 API 做线上请求,或者通过 Python,Java 的 SDK,都可以直接去跟 serving 的服务器做通信和线上请求。可以看到,基于 SQL 和基于 CLI 的开发非常低门槛以及方便。
2.5 OpenMLDB 上下游生态
将 OpenMLDB 投射到 MLOps 生命周期中,可以看到 OpenMLDB 占据着其中 FeatureOps 的位置,主要是做特征计算。
2.5.1 内部框架
先解析 OpenMLDB 内部框架,我们有这个 Online 引擎和 Offline 引擎。
Online 引擎又可以被细分为存储和执行。在其中的 SQL 执行层面,因为需要储存最新的实时数据的,所以我们会有一个 Storage engine,在默认情况下会有 in memory storage(build in)。它其实是非常高效的、专门面向时序数据库去优化的一个内存数据库。当然我们也可以数据存在磁盘上,把 RocksDB 插进来。所以 OpenMLDB v 0.5.0的版本会同时提供两种不同的 Storage Engine。如果你对性能需求特别高,可以选择 in memory storage engine。如果你对性能不太敏感但是重视成本,那么可以使用基于磁盘的存储(RocksDB)。
Online SQL Engine 这一块是我们自研的,用于高性能进行 SQL 计算。Offline 板块是基于Spark去做了合理的修改,称作这个 OpenMLDB 的 Spark 发行版,未来我们可能也会有其他的一些扩展。
2.5.2 Data sources
左边的是 DataOps,介绍了数据是如何获取的。比方说 Online data sources 板块,我们发布了 OpenMLDB Pulsar connector, 已经可以接入 Pulsar 的数据了。这个月发布的版本中,我们应该还会把 Kafka 的这个 connector 也同时发布出来,更加有利于这个大家数据的接入。在 Offline data sources 这一块呢,OpenMLDB 支持直接接入 HDFS、S3 数据 ,未来我们也会支持更多的数据源。
2.5.3 ModelOps
往右的 ModelOps 这边,其实是一些下游模型。下游模型通过一些标准输出格式,就能直接接入了。这个月会发布的新版本中,我们会把这个模型特征的功能整合进来,让它可以输出这个标准的 LIBSVM 或者 CSV 的格式,可以直接给到 Pytorch 等使用。
2.5.4 ProductionOps
我们也在做部署合和任务编排,OpenMLDB 已经和 Airflow 和 Kubeflow 做了对接,有望在近期完成与 Airflow 的合作内容。监控一块也是非常易于使用的,OpenMLDB 已经和 Prometheus 和 Grafana 做了对接。
2.6 拥抱前沿新硬件技术:基于持久内存的优化
在前沿技术创新上我们也有产出成果,这个是去年被录用的一个 VLDB 的 paper,VLDB 是国际数据库界最顶尖的学术界的会议,在 paper 里面我们讲了两个事情:
- 一是把我们整个 OpenMLDB 的实现架构都去仔细进行了描述,所以大家想了解这个架构的话可以也去参照一下 paper;
- 二是讲了怎么去跟今天的前沿的硬件技术做结合,前沿的硬件技术就是 persistent memory,即持久内存,以前在学术界叫做非易失性内存。
持久内存是英特尔在大概 18、 19 年左右,发布了真正工业界第一款企业级的持久内存应用,奥腾持久内存。那么持久内存有什么优势呢?首先它成本低,它的单位价格是 Dram的 1/3~1/4 左右。当然它的性能也会比 Dram 稍微差 1/2 或 1/3 左右,但是比 SSD 还是会好一个量级的。其次容量大,一条持久内存可以最高到 512 GB,一台服务器上就很容易达到几个 TB。还有一个非常革命性的技术,就是可持久性的内存。现在的 Dram 掉电以后数据都没了,而 Persistent memory 掉电以后这个数据还在,这个是一个非常革命性的技术。
我们把持久内存跟 OpenMLDB 线上执行引擎已经结合了起来。前面提到了线上执行引擎的特点,首先它是一个基本上是基于纯内存的执行引擎,所以把它运行起来的成本有时候还是挺高的,如果场景特别大,为了满足内存需求,需要十几台机器,才能运行起来。同时它也有恢复时间慢的问题,因为它一旦掉电,需要从外部存储重新构建内存镜像,需要较长的时间。
于是我们就把持久内存跟 OpenMLDB 的线上引擎给结合起来,达到了三个非常好的效果:
- 恢复时间从本来的 6 个小时级别降到了 1 分钟。线上业务的意义其实是非常巨大的,线上业务比方说点餐系统,是不允许长时间掉线的,或者不允许某节点掉线以后影响业务的服务质量。结合之后,一分钟就能把这个业务重新拉起来,就不会影响到服务质量。
- 由于一些底层架构的修改,也改进了 20% 的长尾延迟。在 TP9999 的情况下,这就非常显著。
- 减少了总成本。因为内存单台机器内存扩大,使用的机器数量就变少了,原来用 16 台,现在只需要 6 台,成本一下子就降下来了。
2.7 OpenMLDB 典型案例 – 某银行事中反欺诈交易
接下来举一个简单的例子,在某银行的事中反欺诈交易场景,OpenMLDB 其实就是处于 FeatureOps 的位置,同时衔接了离线批处理和实时特征计算。然后在某银行的业务场景里,他们对响应的要求是非常高的,需要延迟在 20 ms 以内。可以看到,相比较于它原来传统规则的系统、客户自研的系统,OpenMLDB 提供了一个更好的效果,满足了他们发展的业务需求。
2.8 OpenMLDB 的历史
其实 OpenMLDB 是从第四范式成立第一天就开始做的产品。经过了 5 年的研发沉淀,OpenMLDB 跟随着商业产品经历了上百个项目的验证,累积了非常多的案例。
3 | 面向开源开放的 OpenMLDB 社区发展
3.1 OpenMLDB 发展历程
OpenMLDB 真正开源是去年的 6 月,我们其中的关键组件重新从商业平台中抽取出来,做了包装和优化形成了 OpenMLDB 今天的形态,并且对外开源,贡献给社区。我们开源后收获了不错的反馈,去年 9 月收获了第一个开源企业用户 Akulaku,今年我们也看到很多新团队在不断深入使用 OpenMLDB。
3.2 OpenMLDB 开源基本信息
这张图上是 OpenMLDB 的一些基本信息,大家可以简单了解。
3.3 感谢OpenMLDB的社区开发者
趁这个机会,我想再次感谢一下 OpenMLDB 的社区开发者。到目前为止,共有 51 位开发者加入社区。是大家不断地投入时间精力,OpenMLDB 才能被推动着不断往前发展。从 0.4.0 版本以来,又有 15 位新加入的开发者为社区做出了贡献。在这里,我想表示诚挚的感谢。如果大家对 OpenMLDB 感兴趣,也非常欢迎你作为新伙伴加入。
3.4 OpenMLDB v0.5.0 主要特性
最后想重点给大家介绍 OpenMLDB v0.5.0的新特性,预计在 4 月底发布。
- 预聚合技术应用到长窗口上。这个长窗口指的是时间窗口非常大,包含上百万条数据,针对这块数据做优化处理,我们会把预聚合技术应用进去,指数级提升长窗口聚合性能。
- 提供一个新的针对磁盘的存储引擎。如果你对价格敏感的话,可以选者这种 RocksDB 的外存储存。这样使得线上存储引擎可插拔以适配不同业务需求,既可以支持基于内存的高性能存储引擎,也可以支持基于外存的大容量低成本存储引擎,还可以支持基于持久内存的存储引擎以在性能和成本间保持平衡。
- UDF(用户自定义函数)支持,也会在加入到产品中,大幅提升易用性和适用性。
- 支持基于哈希的离散特征编码,以及编码后特征输出到CSV合LIBSVM格式,直接应用到模型训练合模型推理。
- 完善的监控能力,在企业级应用环境中大幅提升稳定性、可观测性、和可分析性。
- 上下游数据源生态整合,提供多种数据源 connectors,包括线上数据源的 Kafka, Pulsar connectors 等等。
3.5 OpenMLDB 后续重要特性
后续规划中 OpenMLDB 特性会朝着三个主要目标去走,三个主要目标就是降低使用门槛,降低使用成本,以及跟上下游生态的打通。
后续迭代都会不断地朝着这三个目标走。比方去规划一个 Cloud native 的 OpenMLDB 版本,包括自动特征工程,可能是今天用户还需要写 SQL,而在未来 SQL 可以根据数据去自动生成。以及还有基于异构硬件的优化,非结构化数据的支持,特征版本合血缘关系管理。大家对某个 feature 特别感兴趣或者特别需要的话,可以通过社区、Github 等渠道进行反馈,我们会去根据社区的反馈去看需求的优先级,也非常欢迎来自社区的共同开发。
3.6 欢迎加入 OpenMLDB 开源社区
上次 Meetup 时,我预告了官网的上线。如今 OpenMLDB 官网已经顺利推出,欢迎大家访问。或者也可以访问我们的 Github 页面,加入我们的微信交流群,又或是我的个人微信探讨交流。
今天的分享就到这里了,感谢大家。
将 OpenMLDB 投射到 MLOps 生命周期中,可以看到 OpenMLDB 占据着其中 FeatureOps 的位置,主要是做特征计算。
2.5.1 内部框架
先解析 OpenMLDB 内部框架,我们有这个 Online 引擎和 Offline 引擎。
Online 引擎又可以被细分为存储和执行。在其中的 SQL 执行层面,因为需要储存最新的实时数据的,所以我们会有一个 Storage engine,在默认情况下会有 in memory storage(build in)。它其实是非常高效的、专门面向时序数据库去优化的一个内存数据库。当然我们也可以数据存在磁盘上,把 RocksDB 插进来。所以 OpenMLDB v 0.5.0的版本会同时提供两种不同的 Storage Engine。如果你对性能需求特别高,可以选择 in memory storage engine。如果你对性能不太敏感但是重视成本,那么可以使用基于磁盘的存储(RocksDB)。
Online SQL Engine 这一块是我们自研的,用于高性能进行 SQL 计算。Offline 板块是基于Spark去做了合理的修改,称作这个 OpenMLDB 的 Spark 发行版,未来我们可能也会有其他的一些扩展。
2.5.2 Data sources
左边的是 DataOps,介绍了数据是如何获取的。比方说 Online data sources 板块,我们发布了 OpenMLDB Pulsar connector, 已经可以接入 Pulsar 的数据了。这个月发布的版本中,我们应该还会把 Kafka 的这个 connector 也同时发布出来,更加有利于这个大家数据的接入。在 Offline data sources 这一块呢,OpenMLDB 支持直接接入 HDFS、S3 数据 ,未来我们也会支持更多的数据源。
2.5.3 ModelOps
往右的 ModelOps 这边,其实是一些下游模型。下游模型通过一些标准输出格式,就能直接接入了。这个月会发布的新版本中,我们会把这个模型特征的功能整合进来,让它可以输出这个标准的 LIBSVM 或者 CSV 的格式,可以直接给到 Pytorch 等使用。
2.5.4 ProductionOps
我们也在做部署合和任务编排,OpenMLDB 已经和 Airflow 和 Kubeflow 做了对接,有望在近期完成与 Airflow 的合作内容。监控一块也是非常易于使用的,OpenMLDB 已经和 Prometheus 和 Grafana 做了对接。
2.6 拥抱前沿新硬件技术:基于持久内存的优化
在前沿技术创新上我们也有产出成果,这个是去年被录用的一个 VLDB 的 paper,VLDB 是国际数据库界最顶尖的学术界的会议,在 paper 里面我们讲了两个事情:
- 一是把我们整个 OpenMLDB 的实现架构都去仔细进行了描述,所以大家想了解这个架构的话可以也去参照一下 paper;
- 二是讲了怎么去跟今天的前沿的硬件技术做结合,前沿的硬件技术就是 persistent memory,即持久内存,以前在学术界叫做非易失性内存。
持久内存是英特尔在大概 18、 19 年左右,发布了真正工业界第一款企业级的持久内存应用,奥腾持久内存。那么持久内存有什么优势呢?首先它成本低,它的单位价格是 Dram的 1/3~1/4 左右。当然它的性能也会比 Dram 稍微差 1/2 或 1/3 左右,但是比 SSD 还是会好一个量级的。其次容量大,一条持久内存可以最高到 512 GB,一台服务器上就很容易达到几个 TB。还有一个非常革命性的技术,就是可持久性的内存。现在的 Dram 掉电以后数据都没了,而 Persistent memory 掉电以后这个数据还在,这个是一个非常革命性的技术。
我们把持久内存跟 OpenMLDB 线上执行引擎已经结合了起来。前面提到了线上执行引擎的特点,首先它是一个基本上是基于纯内存的执行引擎,所以把它运行起来的成本有时候还是挺高的,如果场景特别大,为了满足内存需求,需要十几台机器,才能运行起来。同时它也有恢复时间慢的问题,因为它一旦掉电,需要从外部存储重新构建内存镜像,需要较长的时间。
于是我们就把持久内存跟 OpenMLDB 的线上引擎给结合起来,达到了三个非常好的效果:
- 恢复时间从本来的 6 个小时级别降到了 1 分钟。线上业务的意义其实是非常巨大的,线上业务比方说点餐系统,是不允许长时间掉线的,或者不允许某节点掉线以后影响业务的服务质量。结合之后,一分钟就能把这个业务重新拉起来,就不会影响到服务质量。
- 由于一些底层架构的修改,也改进了 20% 的长尾延迟。在 TP9999 的情况下,这就非常显著。
- 减少了总成本。因为内存单台机器内存扩大,使用的机器数量就变少了,原来用 16 台,现在只需要 6 台,成本一下子就降下来了。
2.7 OpenMLDB 典型案例 – 某银行事中反欺诈交易
接下来举一个简单的例子,在某银行的事中反欺诈交易场景,OpenMLDB 其实就是处于 FeatureOps 的位置,同时衔接了离线批处理和实时特征计算。然后在某银行的业务场景里,他们对响应的要求是非常高的,需要延迟在 20 ms 以内。可以看到,相比较于它原来传统规则的系统、客户自研的系统,OpenMLDB 提供了一个更好的效果,满足了他们发展的业务需求。
2.8 OpenMLDB 的历史
其实 OpenMLDB 是从第四范式成立第一天就开始做的产品。经过了 5 年的研发沉淀,OpenMLDB 跟随着商业产品经历了上百个项目的验证,累积了非常多的案例。
3 | 面向开源开放的 OpenMLDB 社区发展
3.1 OpenMLDB 发展历程
OpenMLDB 真正开源是去年的 6 月,我们其中的关键组件重新从商业平台中抽取出来,做了包装和优化形成了 OpenMLDB 今天的形态,并且对外开源,贡献给社区。我们开源后收获了不错的反馈,去年 9 月收获了第一个开源企业用户 Akulaku,今年我们也看到很多新团队在不断深入使用 OpenMLDB。
3.2 OpenMLDB 开源基本信息
这张图上是 OpenMLDB 的一些基本信息,大家可以简单了解。
3.3 感谢OpenMLDB的社区开发者
趁这个机会,我想再次感谢一下 OpenMLDB 的社区开发者。到目前为止,共有 51 位开发者加入社区。是大家不断地投入时间精力,OpenMLDB 才能被推动着不断往前发展。从 0.4.0 版本以来,又有 15 位新加入的开发者为社区做出了贡献。在这里,我想表示诚挚的感谢。如果大家对 OpenMLDB 感兴趣,也非常欢迎你作为新伙伴加入。
3.4 OpenMLDB v0.5.0 主要特性
最后想重点给大家介绍 OpenMLDB v0.5.0的新特性,预计在 4 月底发布。
- 预聚合技术应用到长窗口上。这个长窗口指的是时间窗口非常大,包含上百万条数据,针对这块数据做优化处理,我们会把预聚合技术应用进去,指数级提升长窗口聚合性能。
- 提供一个新的针对磁盘的存储引擎。如果你对价格敏感的话,可以选者这种 RocksDB 的外存储存。这样使得线上存储引擎可插拔以适配不同业务需求,既可以支持基于内存的高性能存储引擎,也可以支持基于外存的大容量低成本存储引擎,还可以支持基于持久内存的存储引擎以在性能和成本间保持平衡。
- UDF(用户自定义函数)支持,也会在加入到产品中,大幅提升易用性和适用性。
- 支持基于哈希的离散特征编码,以及编码后特征输出到CSV合LIBSVM格式,直接应用到模型训练合模型推理。
- 完善的监控能力,在企业级应用环境中大幅提升稳定性、可观测性、和可分析性。
- 上下游数据源生态整合,提供多种数据源 connectors,包括线上数据源的 Kafka, Pulsar connectors 等等。
3.5 OpenMLDB 后续重要特性
后续规划中 OpenMLDB 特性会朝着三个主要目标去走,三个主要目标就是降低使用门槛,降低使用成本,以及跟上下游生态的打通。
后续迭代都会不断地朝着这三个目标走。比方去规划一个 Cloud native 的 OpenMLDB 版本,包括自动特征工程,可能是今天用户还需要写 SQL,而在未来 SQL 可以根据数据去自动生成。以及还有基于异构硬件的优化,非结构化数据的支持,特征版本合血缘关系管理。大家对某个 feature 特别感兴趣或者特别需要的话,可以通过社区、Github 等渠道进行反馈,我们会去根据社区的反馈去看需求的优先级,也非常欢迎来自社区的共同开发。
3.6 欢迎加入 OpenMLDB 开源社区
上次 Meetup 时,我预告了官网的上线。如今 OpenMLDB 官网已经顺利推出,欢迎大家访问。或者也可以访问我们的 Github 页面,加入我们的微信交流群,又或是我的个人微信探讨交流。
今天的分享就到这里了,感谢大家。
2.5.3 ModelOps
往右的 ModelOps 这边,其实是一些下游模型。下游模型通过一些标准输出格式,就能直接接入了。这个月会发布的新版本中,我们会把这个模型特征的功能整合进来,让它可以输出这个标准的 LIBSVM 或者 CSV 的格式,可以直接给到 Pytorch 等使用。
2.5.4 ProductionOps
我们也在做部署合和任务编排,OpenMLDB 已经和 Airflow 和 Kubeflow 做了对接,有望在近期完成与 Airflow 的合作内容。监控一块也是非常易于使用的,OpenMLDB 已经和 Prometheus 和 Grafana 做了对接。
2.6 拥抱前沿新硬件技术:基于持久内存的优化
在前沿技术创新上我们也有产出成果,这个是去年被录用的一个 VLDB 的 paper,VLDB 是国际数据库界最顶尖的学术界的会议,在 paper 里面我们讲了两个事情:
- 一是把我们整个 OpenMLDB 的实现架构都去仔细进行了描述,所以大家想了解这个架构的话可以也去参照一下 paper;
- 二是讲了怎么去跟今天的前沿的硬件技术做结合,前沿的硬件技术就是 persistent memory,即持久内存,以前在学术界叫做非易失性内存。
持久内存是英特尔在大概 18、 19 年左右,发布了真正工业界第一款企业级的持久内存应用,奥腾持久内存。那么持久内存有什么优势呢?首先它成本低,它的单位价格是 Dram的 1/3~1/4 左右。当然它的性能也会比 Dram 稍微差 1/2 或 1/3 左右,但是比 SSD 还是会好一个量级的。其次容量大,一条持久内存可以最高到 512 GB,一台服务器上就很容易达到几个 TB。还有一个非常革命性的技术,就是可持久性的内存。现在的 Dram 掉电以后数据都没了,而 Persistent memory 掉电以后这个数据还在,这个是一个非常革命性的技术。
我们把持久内存跟 OpenMLDB 线上执行引擎已经结合了起来。前面提到了线上执行引擎的特点,首先它是一个基本上是基于纯内存的执行引擎,所以把它运行起来的成本有时候还是挺高的,如果场景特别大,为了满足内存需求,需要十几台机器,才能运行起来。同时它也有恢复时间慢的问题,因为它一旦掉电,需要从外部存储重新构建内存镜像,需要较长的时间。
于是我们就把持久内存跟 OpenMLDB 的线上引擎给结合起来,达到了三个非常好的效果:
- 恢复时间从本来的 6 个小时级别降到了 1 分钟。线上业务的意义其实是非常巨大的,线上业务比方说点餐系统,是不允许长时间掉线的,或者不允许某节点掉线以后影响业务的服务质量。结合之后,一分钟就能把这个业务重新拉起来,就不会影响到服务质量。
- 由于一些底层架构的修改,也改进了 20% 的长尾延迟。在 TP9999 的情况下,这就非常显著。
- 减少了总成本。因为内存单台机器内存扩大,使用的机器数量就变少了,原来用 16 台,现在只需要 6 台,成本一下子就降下来了。
2.7 OpenMLDB 典型案例 – 某银行事中反欺诈交易
接下来举一个简单的例子,在某银行的事中反欺诈交易场景,OpenMLDB 其实就是处于 FeatureOps 的位置,同时衔接了离线批处理和实时特征计算。然后在某银行的业务场景里,他们对响应的要求是非常高的,需要延迟在 20 ms 以内。可以看到,相比较于它原来传统规则的系统、客户自研的系统,OpenMLDB 提供了一个更好的效果,满足了他们发展的业务需求。
2.8 OpenMLDB 的历史
其实 OpenMLDB 是从第四范式成立第一天就开始做的产品。经过了 5 年的研发沉淀,OpenMLDB 跟随着商业产品经历了上百个项目的验证,累积了非常多的案例。
3 | 面向开源开放的 OpenMLDB 社区发展
3.1 OpenMLDB 发展历程
OpenMLDB 真正开源是去年的 6 月,我们其中的关键组件重新从商业平台中抽取出来,做了包装和优化形成了 OpenMLDB 今天的形态,并且对外开源,贡献给社区。我们开源后收获了不错的反馈,去年 9 月收获了第一个开源企业用户 Akulaku,今年我们也看到很多新团队在不断深入使用 OpenMLDB。
3.2 OpenMLDB 开源基本信息
这张图上是 OpenMLDB 的一些基本信息,大家可以简单了解。
3.3 感谢OpenMLDB的社区开发者
趁这个机会,我想再次感谢一下 OpenMLDB 的社区开发者。到目前为止,共有 51 位开发者加入社区。是大家不断地投入时间精力,OpenMLDB 才能被推动着不断往前发展。从 0.4.0 版本以来,又有 15 位新加入的开发者为社区做出了贡献。在这里,我想表示诚挚的感谢。如果大家对 OpenMLDB 感兴趣,也非常欢迎你作为新伙伴加入。
3.4 OpenMLDB v0.5.0 主要特性
最后想重点给大家介绍 OpenMLDB v0.5.0的新特性,预计在 4 月底发布。
- 预聚合技术应用到长窗口上。这个长窗口指的是时间窗口非常大,包含上百万条数据,针对这块数据做优化处理,我们会把预聚合技术应用进去,指数级提升长窗口聚合性能。
- 提供一个新的针对磁盘的存储引擎。如果你对价格敏感的话,可以选者这种 RocksDB 的外存储存。这样使得线上存储引擎可插拔以适配不同业务需求,既可以支持基于内存的高性能存储引擎,也可以支持基于外存的大容量低成本存储引擎,还可以支持基于持久内存的存储引擎以在性能和成本间保持平衡。
- UDF(用户自定义函数)支持,也会在加入到产品中,大幅提升易用性和适用性。
- 支持基于哈希的离散特征编码,以及编码后特征输出到CSV合LIBSVM格式,直接应用到模型训练合模型推理。
- 完善的监控能力,在企业级应用环境中大幅提升稳定性、可观测性、和可分析性。
- 上下游数据源生态整合,提供多种数据源 connectors,包括线上数据源的 Kafka, Pulsar connectors 等等。
3.5 OpenMLDB 后续重要特性
后续规划中 OpenMLDB 特性会朝着三个主要目标去走,三个主要目标就是降低使用门槛,降低使用成本,以及跟上下游生态的打通。
后续迭代都会不断地朝着这三个目标走。比方去规划一个 Cloud native 的 OpenMLDB 版本,包括自动特征工程,可能是今天用户还需要写 SQL,而在未来 SQL 可以根据数据去自动生成。以及还有基于异构硬件的优化,非结构化数据的支持,特征版本合血缘关系管理。大家对某个 feature 特别感兴趣或者特别需要的话,可以通过社区、Github 等渠道进行反馈,我们会去根据社区的反馈去看需求的优先级,也非常欢迎来自社区的共同开发。
3.6 欢迎加入 OpenMLDB 开源社区
上次 Meetup 时,我预告了官网的上线。如今 OpenMLDB 官网已经顺利推出,欢迎大家访问。或者也可以访问我们的 Github 页面,加入我们的微信交流群,又或是我的个人微信探讨交流。
今天的分享就到这里了,感谢大家。
2.6 拥抱前沿新硬件技术:基于持久内存的优化
在前沿技术创新上我们也有产出成果,这个是去年被录用的一个 VLDB 的 paper,VLDB 是国际数据库界最顶尖的学术界的会议,在 paper 里面我们讲了两个事情:
- 一是把我们整个 OpenMLDB 的实现架构都去仔细进行了描述,所以大家想了解这个架构的话可以也去参照一下 paper;
- 二是讲了怎么去跟今天的前沿的硬件技术做结合,前沿的硬件技术就是 persistent memory,即持久内存,以前在学术界叫做非易失性内存。
持久内存是英特尔在大概 18、 19 年左右,发布了真正工业界第一款企业级的持久内存应用,奥腾持久内存。那么持久内存有什么优势呢?首先它成本低,它的单位价格是 Dram的 1/3~1/4 左右。当然它的性能也会比 Dram 稍微差 1/2 或 1/3 左右,但是比 SSD 还是会好一个量级的。其次容量大,一条持久内存可以最高到 512 GB,一台服务器上就很容易达到几个 TB。还有一个非常革命性的技术,就是可持久性的内存。现在的 Dram 掉电以后数据都没了,而 Persistent memory 掉电以后这个数据还在,这个是一个非常革命性的技术。
我们把持久内存跟 OpenMLDB 线上执行引擎已经结合了起来。前面提到了线上执行引擎的特点,首先它是一个基本上是基于纯内存的执行引擎,所以把它运行起来的成本有时候还是挺高的,如果场景特别大,为了满足内存需求,需要十几台机器,才能运行起来。同时它也有恢复时间慢的问题,因为它一旦掉电,需要从外部存储重新构建内存镜像,需要较长的时间。
于是我们就把持久内存跟 OpenMLDB 的线上引擎给结合起来,达到了三个非常好的效果:
- 恢复时间从本来的 6 个小时级别降到了 1 分钟。线上业务的意义其实是非常巨大的,线上业务比方说点餐系统,是不允许长时间掉线的,或者不允许某节点掉线以后影响业务的服务质量。结合之后,一分钟就能把这个业务重新拉起来,就不会影响到服务质量。
- 由于一些底层架构的修改,也改进了 20% 的长尾延迟。在 TP9999 的情况下,这就非常显著。
- 减少了总成本。因为内存单台机器内存扩大,使用的机器数量就变少了,原来用 16 台,现在只需要 6 台,成本一下子就降下来了。
2.7 OpenMLDB 典型案例 – 某银行事中反欺诈交易
接下来举一个简单的例子,在某银行的事中反欺诈交易场景,OpenMLDB 其实就是处于 FeatureOps 的位置,同时衔接了离线批处理和实时特征计算。然后在某银行的业务场景里,他们对响应的要求是非常高的,需要延迟在 20 ms 以内。可以看到,相比较于它原来传统规则的系统、客户自研的系统,OpenMLDB 提供了一个更好的效果,满足了他们发展的业务需求。
2.8 OpenMLDB 的历史
其实 OpenMLDB 是从第四范式成立第一天就开始做的产品。经过了 5 年的研发沉淀,OpenMLDB 跟随着商业产品经历了上百个项目的验证,累积了非常多的案例。
3 | 面向开源开放的 OpenMLDB 社区发展
3.1 OpenMLDB 发展历程
OpenMLDB 真正开源是去年的 6 月,我们其中的关键组件重新从商业平台中抽取出来,做了包装和优化形成了 OpenMLDB 今天的形态,并且对外开源,贡献给社区。我们开源后收获了不错的反馈,去年 9 月收获了第一个开源企业用户 Akulaku,今年我们也看到很多新团队在不断深入使用 OpenMLDB。
3.2 OpenMLDB 开源基本信息
这张图上是 OpenMLDB 的一些基本信息,大家可以简单了解。
3.3 感谢OpenMLDB的社区开发者
趁这个机会,我想再次感谢一下 OpenMLDB 的社区开发者。到目前为止,共有 51 位开发者加入社区。是大家不断地投入时间精力,OpenMLDB 才能被推动着不断往前发展。从 0.4.0 版本以来,又有 15 位新加入的开发者为社区做出了贡献。在这里,我想表示诚挚的感谢。如果大家对 OpenMLDB 感兴趣,也非常欢迎你作为新伙伴加入。
3.4 OpenMLDB v0.5.0 主要特性
最后想重点给大家介绍 OpenMLDB v0.5.0的新特性,预计在 4 月底发布。
- 预聚合技术应用到长窗口上。这个长窗口指的是时间窗口非常大,包含上百万条数据,针对这块数据做优化处理,我们会把预聚合技术应用进去,指数级提升长窗口聚合性能。
- 提供一个新的针对磁盘的存储引擎。如果你对价格敏感的话,可以选者这种 RocksDB 的外存储存。这样使得线上存储引擎可插拔以适配不同业务需求,既可以支持基于内存的高性能存储引擎,也可以支持基于外存的大容量低成本存储引擎,还可以支持基于持久内存的存储引擎以在性能和成本间保持平衡。
- UDF(用户自定义函数)支持,也会在加入到产品中,大幅提升易用性和适用性。
- 支持基于哈希的离散特征编码,以及编码后特征输出到CSV合LIBSVM格式,直接应用到模型训练合模型推理。
- 完善的监控能力,在企业级应用环境中大幅提升稳定性、可观测性、和可分析性。
- 上下游数据源生态整合,提供多种数据源 connectors,包括线上数据源的 Kafka, Pulsar connectors 等等。
3.5 OpenMLDB 后续重要特性
后续规划中 OpenMLDB 特性会朝着三个主要目标去走,三个主要目标就是降低使用门槛,降低使用成本,以及跟上下游生态的打通。
后续迭代都会不断地朝着这三个目标走。比方去规划一个 Cloud native 的 OpenMLDB 版本,包括自动特征工程,可能是今天用户还需要写 SQL,而在未来 SQL 可以根据数据去自动生成。以及还有基于异构硬件的优化,非结构化数据的支持,特征版本合血缘关系管理。大家对某个 feature 特别感兴趣或者特别需要的话,可以通过社区、Github 等渠道进行反馈,我们会去根据社区的反馈去看需求的优先级,也非常欢迎来自社区的共同开发。
3.6 欢迎加入 OpenMLDB 开源社区
上次 Meetup 时,我预告了官网的上线。如今 OpenMLDB 官网已经顺利推出,欢迎大家访问。或者也可以访问我们的 Github 页面,加入我们的微信交流群,又或是我的个人微信探讨交流。
今天的分享就到这里了,感谢大家。
接下来举一个简单的例子,在某银行的事中反欺诈交易场景,OpenMLDB 其实就是处于 FeatureOps 的位置,同时衔接了离线批处理和实时特征计算。然后在某银行的业务场景里,他们对响应的要求是非常高的,需要延迟在 20 ms 以内。可以看到,相比较于它原来传统规则的系统、客户自研的系统,OpenMLDB 提供了一个更好的效果,满足了他们发展的业务需求。
2.8 OpenMLDB 的历史
其实 OpenMLDB 是从第四范式成立第一天就开始做的产品。经过了 5 年的研发沉淀,OpenMLDB 跟随着商业产品经历了上百个项目的验证,累积了非常多的案例。
3 | 面向开源开放的 OpenMLDB 社区发展
3.1 OpenMLDB 发展历程
OpenMLDB 真正开源是去年的 6 月,我们其中的关键组件重新从商业平台中抽取出来,做了包装和优化形成了 OpenMLDB 今天的形态,并且对外开源,贡献给社区。我们开源后收获了不错的反馈,去年 9 月收获了第一个开源企业用户 Akulaku,今年我们也看到很多新团队在不断深入使用 OpenMLDB。
3.2 OpenMLDB 开源基本信息
这张图上是 OpenMLDB 的一些基本信息,大家可以简单了解。
3.3 感谢OpenMLDB的社区开发者
趁这个机会,我想再次感谢一下 OpenMLDB 的社区开发者。到目前为止,共有 51 位开发者加入社区。是大家不断地投入时间精力,OpenMLDB 才能被推动着不断往前发展。从 0.4.0 版本以来,又有 15 位新加入的开发者为社区做出了贡献。在这里,我想表示诚挚的感谢。如果大家对 OpenMLDB 感兴趣,也非常欢迎你作为新伙伴加入。
3.4 OpenMLDB v0.5.0 主要特性
最后想重点给大家介绍 OpenMLDB v0.5.0的新特性,预计在 4 月底发布。
- 预聚合技术应用到长窗口上。这个长窗口指的是时间窗口非常大,包含上百万条数据,针对这块数据做优化处理,我们会把预聚合技术应用进去,指数级提升长窗口聚合性能。
- 提供一个新的针对磁盘的存储引擎。如果你对价格敏感的话,可以选者这种 RocksDB 的外存储存。这样使得线上存储引擎可插拔以适配不同业务需求,既可以支持基于内存的高性能存储引擎,也可以支持基于外存的大容量低成本存储引擎,还可以支持基于持久内存的存储引擎以在性能和成本间保持平衡。
- UDF(用户自定义函数)支持,也会在加入到产品中,大幅提升易用性和适用性。
- 支持基于哈希的离散特征编码,以及编码后特征输出到CSV合LIBSVM格式,直接应用到模型训练合模型推理。
- 完善的监控能力,在企业级应用环境中大幅提升稳定性、可观测性、和可分析性。
- 上下游数据源生态整合,提供多种数据源 connectors,包括线上数据源的 Kafka, Pulsar connectors 等等。
3.5 OpenMLDB 后续重要特性
后续规划中 OpenMLDB 特性会朝着三个主要目标去走,三个主要目标就是降低使用门槛,降低使用成本,以及跟上下游生态的打通。
后续迭代都会不断地朝着这三个目标走。比方去规划一个 Cloud native 的 OpenMLDB 版本,包括自动特征工程,可能是今天用户还需要写 SQL,而在未来 SQL 可以根据数据去自动生成。以及还有基于异构硬件的优化,非结构化数据的支持,特征版本合血缘关系管理。大家对某个 feature 特别感兴趣或者特别需要的话,可以通过社区、Github 等渠道进行反馈,我们会去根据社区的反馈去看需求的优先级,也非常欢迎来自社区的共同开发。
3.6 欢迎加入 OpenMLDB 开源社区
上次 Meetup 时,我预告了官网的上线。如今 OpenMLDB 官网已经顺利推出,欢迎大家访问。或者也可以访问我们的 Github 页面,加入我们的微信交流群,又或是我的个人微信探讨交流。
今天的分享就到这里了,感谢大家。
OpenMLDB 真正开源是去年的 6 月,我们其中的关键组件重新从商业平台中抽取出来,做了包装和优化形成了 OpenMLDB 今天的形态,并且对外开源,贡献给社区。我们开源后收获了不错的反馈,去年 9 月收获了第一个开源企业用户 Akulaku,今年我们也看到很多新团队在不断深入使用 OpenMLDB。
3.2 OpenMLDB 开源基本信息
这张图上是 OpenMLDB 的一些基本信息,大家可以简单了解。
3.3 感谢OpenMLDB的社区开发者
趁这个机会,我想再次感谢一下 OpenMLDB 的社区开发者。到目前为止,共有 51 位开发者加入社区。是大家不断地投入时间精力,OpenMLDB 才能被推动着不断往前发展。从 0.4.0 版本以来,又有 15 位新加入的开发者为社区做出了贡献。在这里,我想表示诚挚的感谢。如果大家对 OpenMLDB 感兴趣,也非常欢迎你作为新伙伴加入。
3.4 OpenMLDB v0.5.0 主要特性
最后想重点给大家介绍 OpenMLDB v0.5.0的新特性,预计在 4 月底发布。
- 预聚合技术应用到长窗口上。这个长窗口指的是时间窗口非常大,包含上百万条数据,针对这块数据做优化处理,我们会把预聚合技术应用进去,指数级提升长窗口聚合性能。
- 提供一个新的针对磁盘的存储引擎。如果你对价格敏感的话,可以选者这种 RocksDB 的外存储存。这样使得线上存储引擎可插拔以适配不同业务需求,既可以支持基于内存的高性能存储引擎,也可以支持基于外存的大容量低成本存储引擎,还可以支持基于持久内存的存储引擎以在性能和成本间保持平衡。
- UDF(用户自定义函数)支持,也会在加入到产品中,大幅提升易用性和适用性。
- 支持基于哈希的离散特征编码,以及编码后特征输出到CSV合LIBSVM格式,直接应用到模型训练合模型推理。
- 完善的监控能力,在企业级应用环境中大幅提升稳定性、可观测性、和可分析性。
- 上下游数据源生态整合,提供多种数据源 connectors,包括线上数据源的 Kafka, Pulsar connectors 等等。
3.5 OpenMLDB 后续重要特性
后续规划中 OpenMLDB 特性会朝着三个主要目标去走,三个主要目标就是降低使用门槛,降低使用成本,以及跟上下游生态的打通。
后续迭代都会不断地朝着这三个目标走。比方去规划一个 Cloud native 的 OpenMLDB 版本,包括自动特征工程,可能是今天用户还需要写 SQL,而在未来 SQL 可以根据数据去自动生成。以及还有基于异构硬件的优化,非结构化数据的支持,特征版本合血缘关系管理。大家对某个 feature 特别感兴趣或者特别需要的话,可以通过社区、Github 等渠道进行反馈,我们会去根据社区的反馈去看需求的优先级,也非常欢迎来自社区的共同开发。
3.6 欢迎加入 OpenMLDB 开源社区
上次 Meetup 时,我预告了官网的上线。如今 OpenMLDB 官网已经顺利推出,欢迎大家访问。或者也可以访问我们的 Github 页面,加入我们的微信交流群,又或是我的个人微信探讨交流。
今天的分享就到这里了,感谢大家。
趁这个机会,我想再次感谢一下 OpenMLDB 的社区开发者。到目前为止,共有 51 位开发者加入社区。是大家不断地投入时间精力,OpenMLDB 才能被推动着不断往前发展。从 0.4.0 版本以来,又有 15 位新加入的开发者为社区做出了贡献。在这里,我想表示诚挚的感谢。如果大家对 OpenMLDB 感兴趣,也非常欢迎你作为新伙伴加入。
3.4 OpenMLDB v0.5.0 主要特性
最后想重点给大家介绍 OpenMLDB v0.5.0的新特性,预计在 4 月底发布。
- 预聚合技术应用到长窗口上。这个长窗口指的是时间窗口非常大,包含上百万条数据,针对这块数据做优化处理,我们会把预聚合技术应用进去,指数级提升长窗口聚合性能。
- 提供一个新的针对磁盘的存储引擎。如果你对价格敏感的话,可以选者这种 RocksDB 的外存储存。这样使得线上存储引擎可插拔以适配不同业务需求,既可以支持基于内存的高性能存储引擎,也可以支持基于外存的大容量低成本存储引擎,还可以支持基于持久内存的存储引擎以在性能和成本间保持平衡。
- UDF(用户自定义函数)支持,也会在加入到产品中,大幅提升易用性和适用性。
- 支持基于哈希的离散特征编码,以及编码后特征输出到CSV合LIBSVM格式,直接应用到模型训练合模型推理。
- 完善的监控能力,在企业级应用环境中大幅提升稳定性、可观测性、和可分析性。
- 上下游数据源生态整合,提供多种数据源 connectors,包括线上数据源的 Kafka, Pulsar connectors 等等。
3.5 OpenMLDB 后续重要特性
后续规划中 OpenMLDB 特性会朝着三个主要目标去走,三个主要目标就是降低使用门槛,降低使用成本,以及跟上下游生态的打通。
后续迭代都会不断地朝着这三个目标走。比方去规划一个 Cloud native 的 OpenMLDB 版本,包括自动特征工程,可能是今天用户还需要写 SQL,而在未来 SQL 可以根据数据去自动生成。以及还有基于异构硬件的优化,非结构化数据的支持,特征版本合血缘关系管理。大家对某个 feature 特别感兴趣或者特别需要的话,可以通过社区、Github 等渠道进行反馈,我们会去根据社区的反馈去看需求的优先级,也非常欢迎来自社区的共同开发。
3.6 欢迎加入 OpenMLDB 开源社区
上次 Meetup 时,我预告了官网的上线。如今 OpenMLDB 官网已经顺利推出,欢迎大家访问。或者也可以访问我们的 Github 页面,加入我们的微信交流群,又或是我的个人微信探讨交流。
今天的分享就到这里了,感谢大家。
后续迭代都会不断地朝着这三个目标走。比方去规划一个 Cloud native 的 OpenMLDB 版本,包括自动特征工程,可能是今天用户还需要写 SQL,而在未来 SQL 可以根据数据去自动生成。以及还有基于异构硬件的优化,非结构化数据的支持,特征版本合血缘关系管理。大家对某个 feature 特别感兴趣或者特别需要的话,可以通过社区、Github 等渠道进行反馈,我们会去根据社区的反馈去看需求的优先级,也非常欢迎来自社区的共同开发。








