

本文整理自 OpenMLDB 社区开发者、伊利诺伊大学 徐鹏程 在 OpenMLDB Meetup No.7 中的分享——《OpenMLDB 整合自动特征工程》。
大家好,我是来自伊利诺伊大学的硕士在读学生,也是 OpenMLDB 开源社区的贡献者——徐鹏程。我参与开发的项目,也是今天要和大家介绍的:OpenMLDB 整合自动特征工程。这个项目的工作内容是把 OpenMLDB 和 AutoX 两者结合起来做成一个自动特征工程,我们把它命名为 AutoFE,即 Auto Feature Engineering。
在开始前做个简单自我介绍,我本科就读于上海交通大学,硕士在伊利诺伊大学香槟分校,专业都是电子与计算机工程,感兴趣的方向有机器学习在生物信息等领域的应用、计算机系统与架构、分布式系统等。
今天我会从以下三个方面展开介绍。
-
问题背景
-
解决思路
-
现场 DEMO
问题背景
课题的目标是将 OpenMLDB 和自动特征工程结合起来,达到降低使用门槛的效果。
我们既想要调用 OpenMLDB 这样一个线上线下一致的时序数据库,也想要帮助离线开发的数据科学家减少工作的繁杂,完成一个自动特征工程。
离线开发需要数据科学家根据专业知识和工作经验去构建基于数据的特征,这个工作较为繁复。我们希望通过自动特征工程来减轻负担、降低门槛,同时也与 OpenMLDB 整合,使它能够更好的部署使用。
解决思路
「解决问题流程」
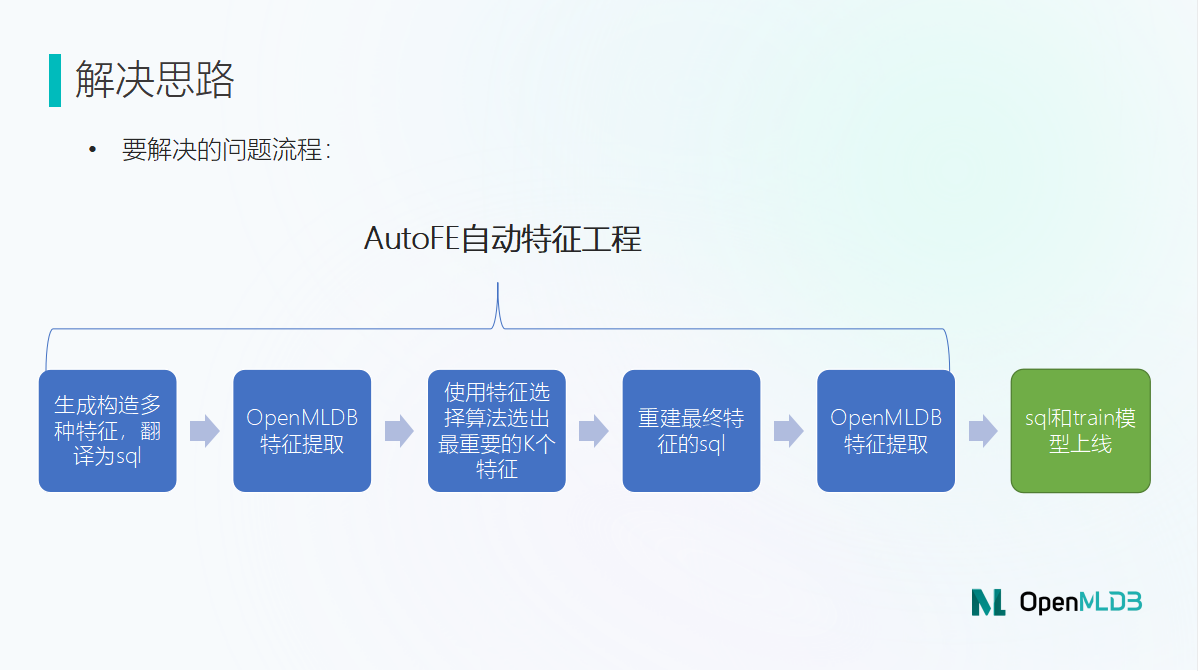
AutoFE 和 OpenMLDB 的通性在于使用了同一套 OpenMLDB 优化后的 SQL。
而课题解决问题的思路是:
step1:使用自动工具生成 SQL,SQL 会利用一些特征工程算法在原有数据的基础上构造生成一些特征。比如我们想解决出租车订单的相关预测问题,像是预测用户下单的等待接单时间、乘车出行时间等。AutoFE 会根据已有的数据,如用户ID、用户定位、用户目的地、每一次订单的用时等构造出适合此类应用场景的新特征,例如,近五分钟平台的平均/最大/最小接单用时,近五分钟比十分钟前的订单平均用时变化量等。
step2:经过 OpenMLDB 的特征提取,会返回一个数据。
step3:我们要针对返回的数据做进一步的筛选。因为部分数据是冗余的,而我们需要的是筛选后的最重要的 K 特征。
step4:K 特征筛选出来后,会重建为最终特征的 SQL 。
step5:最终的 SQL 会传递给 OpenMLDB。
step6:最后进行 SQL 和模型的上线训练。
以上流程已被全部打通,在 OpenMLDB Github 中 Python 目录中有程序链接。
https://github.com/4paradigm/OpenMLDB/tree/main/python/AutoFE
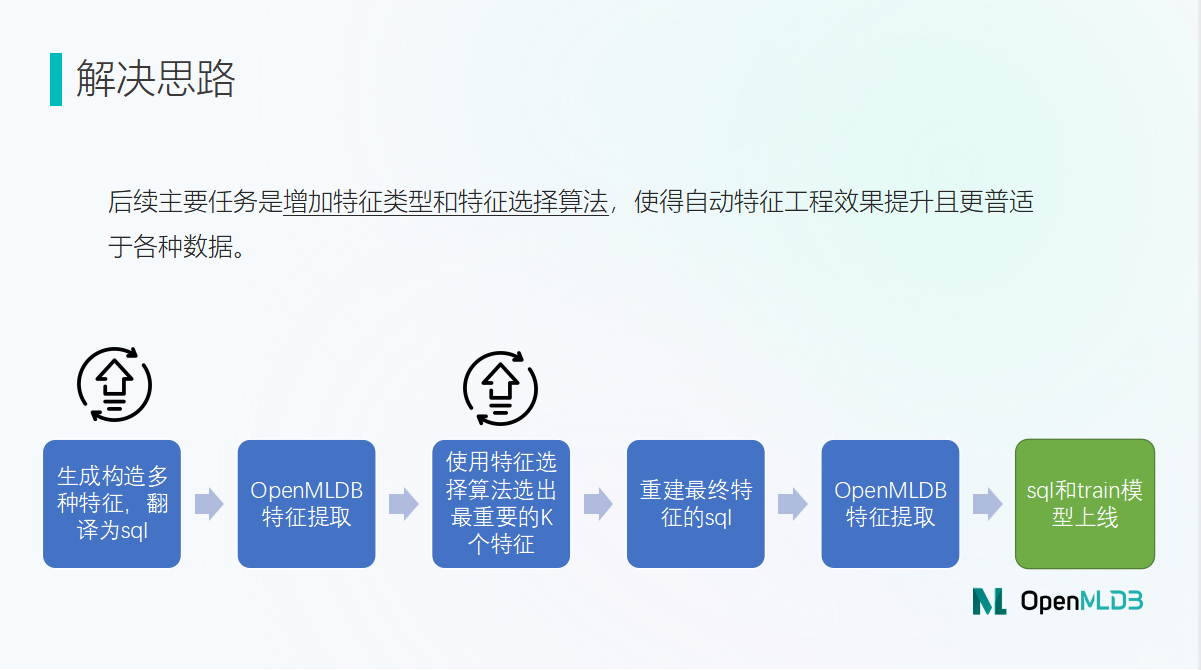
「提升空间」
目前算法还在不断完善中,因为新机器学习算法的不断涌现,所以算法还有广阔的发展空间。尤其是其中较为重要的构造特征以及特征选择两个环节还有充足的提升余地。
「详细拆解」
接下来我会把刚刚简要介绍的环节详细拆解给大家。
Step 1:生成构造多种特征,翻译为 SQL

在流程的最开始,我们要对用户已有的数据,通常是 CSV 表格进行一些基础配置,比如存放位置、数据类型等。配置完成后,就可以启动 AutoFE 的自动特征工程。AutoFE 首先会根据原有数据构造生成新特征,再将其用 SQL 表示,用一个类似于 HTTP 请求的形式发送给 OpenMLDB。
Step 2:OpenMLDB 特征提取
 OpenMLDB 收到 SQL 并进行特征提取后,会以一个新 CSV 的形式返回特征数据,返回数据比原有数据有了较大增长。
OpenMLDB 收到 SQL 并进行特征提取后,会以一个新 CSV 的形式返回特征数据,返回数据比原有数据有了较大增长。
Step 3:特征选择 & Step 4:重建最终特征的 SQL
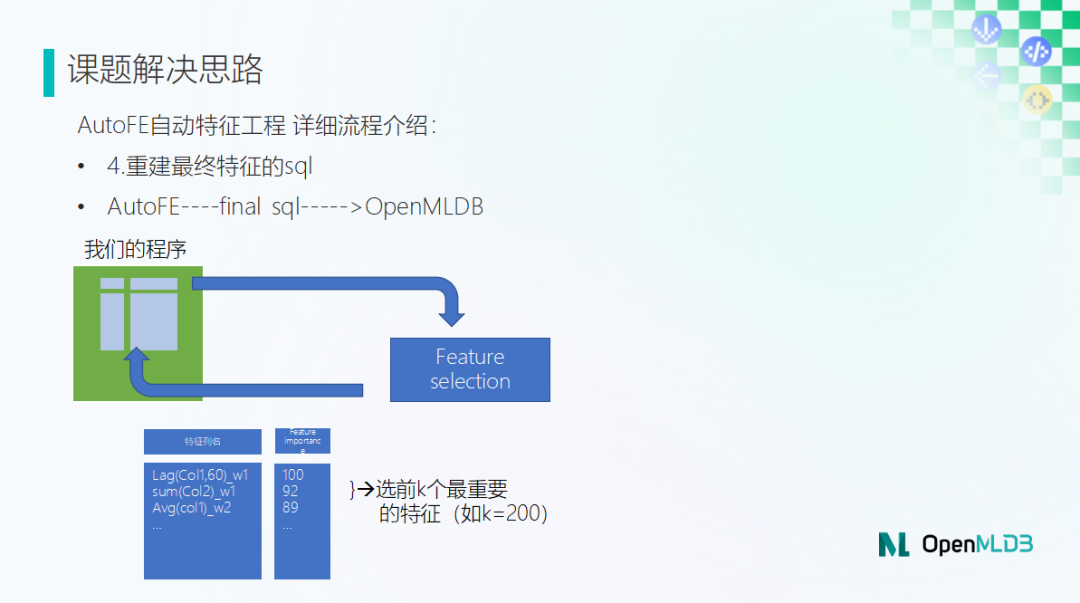
接下来进入到比较关键的一环——特征选择。
面对存放了很多新构造特征的大数据表,我们需要筛选出比较重要的特征,舍去不重要的特征。这时我们会通过 Feature selection 的算法给特征按照重要性排名,截取需要保留的前 K 个。
step 5:再次 OpenMLDB 特征提取

经过特征选择的 SQL 相应也需要更新,删去部分列,优化为更短的 SQL 语句,因为我们筛选保留了最重要的特征,抛弃了不重要的特征。同样的,发送给 OpenMLDB 后,它会以 CSV 形式保存下来。
step 6:SQL 和训练模型上线

这样我们就得到了一个完整的、可供训练模型的数据,它可以很好地表达我们想要的特征。走完这个流程后,就可以进入模型训练和实时特征计算的部分了。

「实现路径」
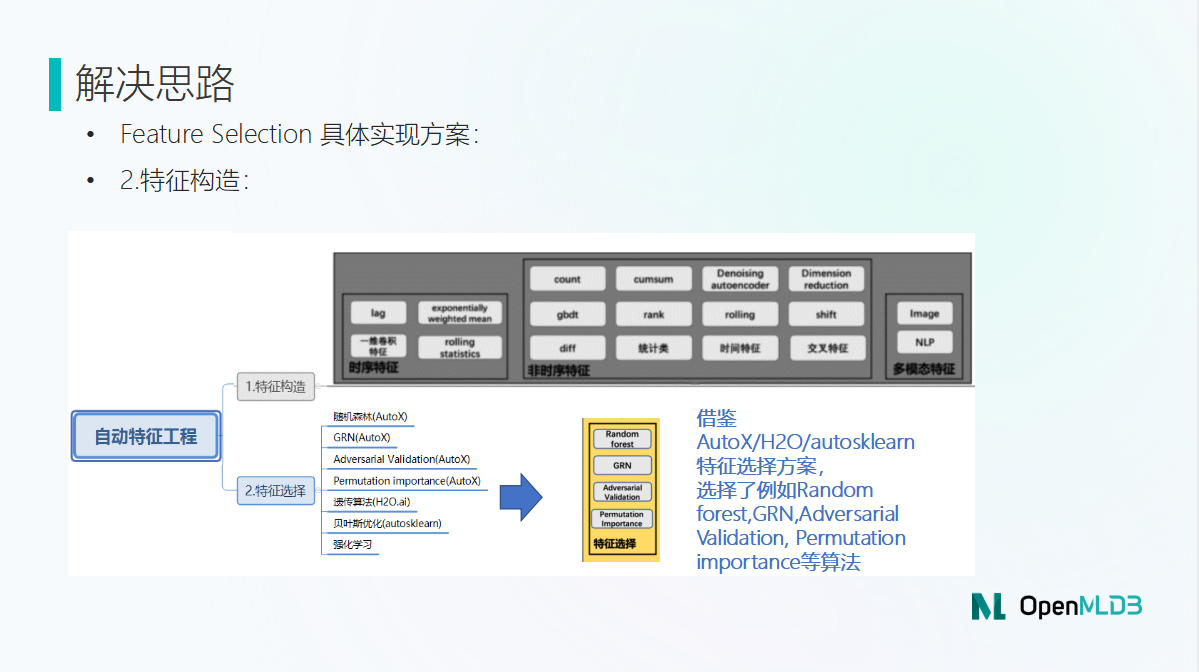
接下来我将简单介绍一下具体的实现路径。主要会分成两块内容,一个是 特征构造,一个是 特征选择。

特征构造环节借鉴了 AutoX 的一些方案,例如 lag,count,cumsum,rolling,shift,diff 等。
因为 OpenMLDB 关注时序性特征较多,所以特征构造方面也更关注时序性,比如说在一个时间窗口内或者一段时间之前的差等等。而其他方向相对而言没有那么完美,例如难以用 SQL 语句去描述图像的特征。
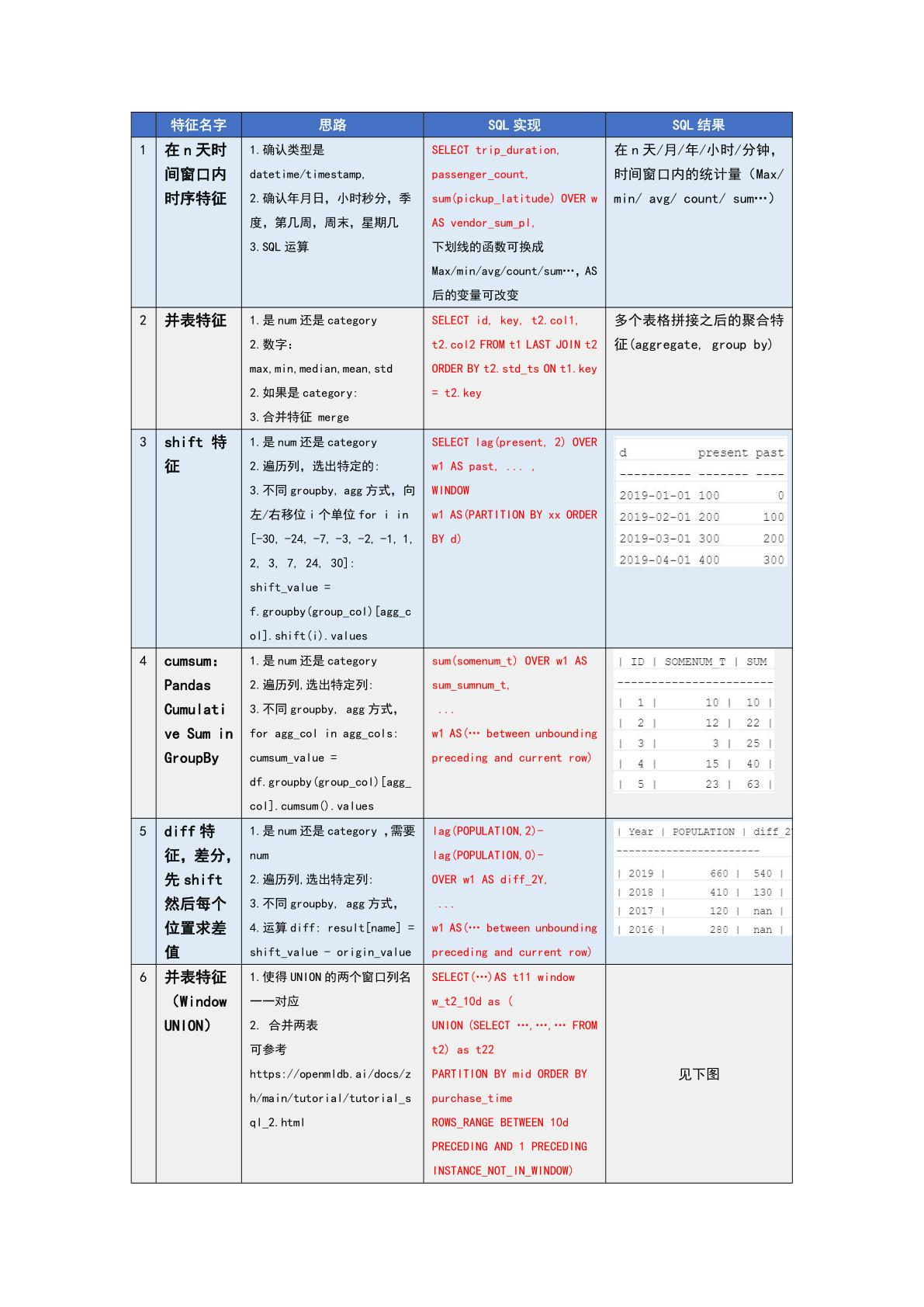
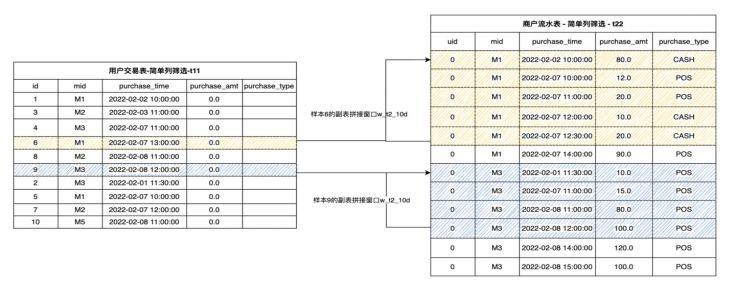
那么我们现在以上图表格为例,简单介绍一下特征构造可以构造出哪些新特征。
-
在 n 天时间窗口内时序特征。通过时间窗口内的统计量进行计算构造。
-
并表特征。将表格按照一定的逻辑,如时间、ID联系拼接起来构造聚合特征。
-
Shift 特征。即是平移的一些特征,比如说用户当前的行为可能和一周前的行为存在关联,我们把平移的行为也作为一个特征新构造出来。
-
cumsum 特征。也就是累计和特征,可以计算最早历史记录到目前的数据,构造新特征。
-
diff 特征。它的逻辑是基于 shift 特征求差值构造新函数。
-
基于 window union 的并表特征。它可以把分布在不同表格的数据合并起来,用一个窗口查找特征。
特征选择方面,我们也借鉴了一些市面上已有开源算法。主要会用到以下三个算法:
-
Adversarial Validation。能够将训练集和测试集分布不一致的特征筛选出来并剔除。
-
GRN。类似于神经网络的原理,可以筛选重要性靠前的特征。
-
Permutation Importance。把一个特征重新排列,观察它预测结构的效果变化,着某种程度上也说明了特征的重要性。



「AutoFE 代码流程」
AutoFE 的代码流程对应了上文提到的环节。
- 第一步是利用现成数据,构造新特征,翻译成 SQL 语句。
- 接下来,以 HTTP 请求的形式去发送给 OpenMLDB,我们会得到一个新的 CSV 数据表。
- 第三步,根据数据表,我们运行一个 get-top-features,选出最重要的 K 个特征。
- 跑完这一步后,同样也会产生最终的 SQL。
- 最后,我们把最终 SQL 发送给 OpenMLDB,经过处理后就得到了用于特征工程数据。
demo 演示
视频链接:https://www.zhihu.com/zvideo/1570865680102121472
以上就是本期分享的全部内容。感谢大家的仔细聆听,也欢迎各位加入 OpenMLDB 社区。
相关链接
OpenMLDB github 主页: https://github.com/4paradigm/OpenMLDB
OpenMLDB 微信交流群









